조기 종료 (Early Stopping)
- 작동 원리: 학습 중 일정 횟수 동안 성적이 오르지 않으면 스스로 학습을 멈춘다.
- 장점: 학습 시간을 단축하고 모델의 일반화 성능을 높인다.
클래스 가중치 (Class Weight)
사용중인 데이터는 '미수료자(0)'가 훨씬 많다. AI는 쪽수(?)가 많은 쪽에 유리하게 판단하는 경향이 있다.
- 해결책: 데이터 수가 적은 '수료자(1)' 정답을 맞혔을 때 더 큰 보너스 점수를 준다.
- 참고: MLPClassifier는 이 기능을 직접 지원하지 않으므로, 오늘은 이 기능을 완벽하게 지원하는 모델인 RandomForestClassifier를 함께 사용해 보겠다.
import pandas as pd
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.preprocessing import StandardScaler
class SmartDeepPredictor:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
self.features = ['time_input', 'total_class_count', 'is_multi_learner', 'is_extra_class', 'job']
self.target = 'completed'
self.df = self.df[self.features + [self.target]].dropna()
def run_smart_analysis(self):
# 1. 전처리
encoded_df = pd.get_dummies(self.df, columns=['job'])
X = encoded_df.drop(columns=[self.target])
y = encoded_df[self.target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 2. 조기 종료를 적용한 신경망
mlp = MLPClassifier(
hidden_layer_sizes=(64, 32, 16),
early_stopping=True,
validation_fraction=0.1, # 10%의 데이터를 내부 검증용으로 사용
random_state=42
)
mlp.fit(X_train_scaled, y_train)
# 3. 클래스 가중치를 적용한 랜덤 포레스트
rf = RandomForestClassifier(
n_estimators=100,
class_weight='balanced', # 적은 수의 데이터를 더 중요하게 취급
random_state=42
)
rf.fit(X_train, y_train)
# 4. 결과 출력 및 비교
models = {"신경망(EarlyStopping)": mlp, "랜덤포레스트(Balanced)": rf}
for name, model in models.items():
current_X = X_test_scaled if name == "신경망(EarlyStopping)" else X_test
y_pred = model.predict(current_X)
print(f"\n--- {name} 분석 결과 ---")
print(f"정확도: {accuracy_score(y_test, y_pred): .4f}")
print("혼동 행렬:")
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
# --- 실행부 ---
predictor = SmartDeepPredictor('train.csv')
predictor.run_smart_analysis()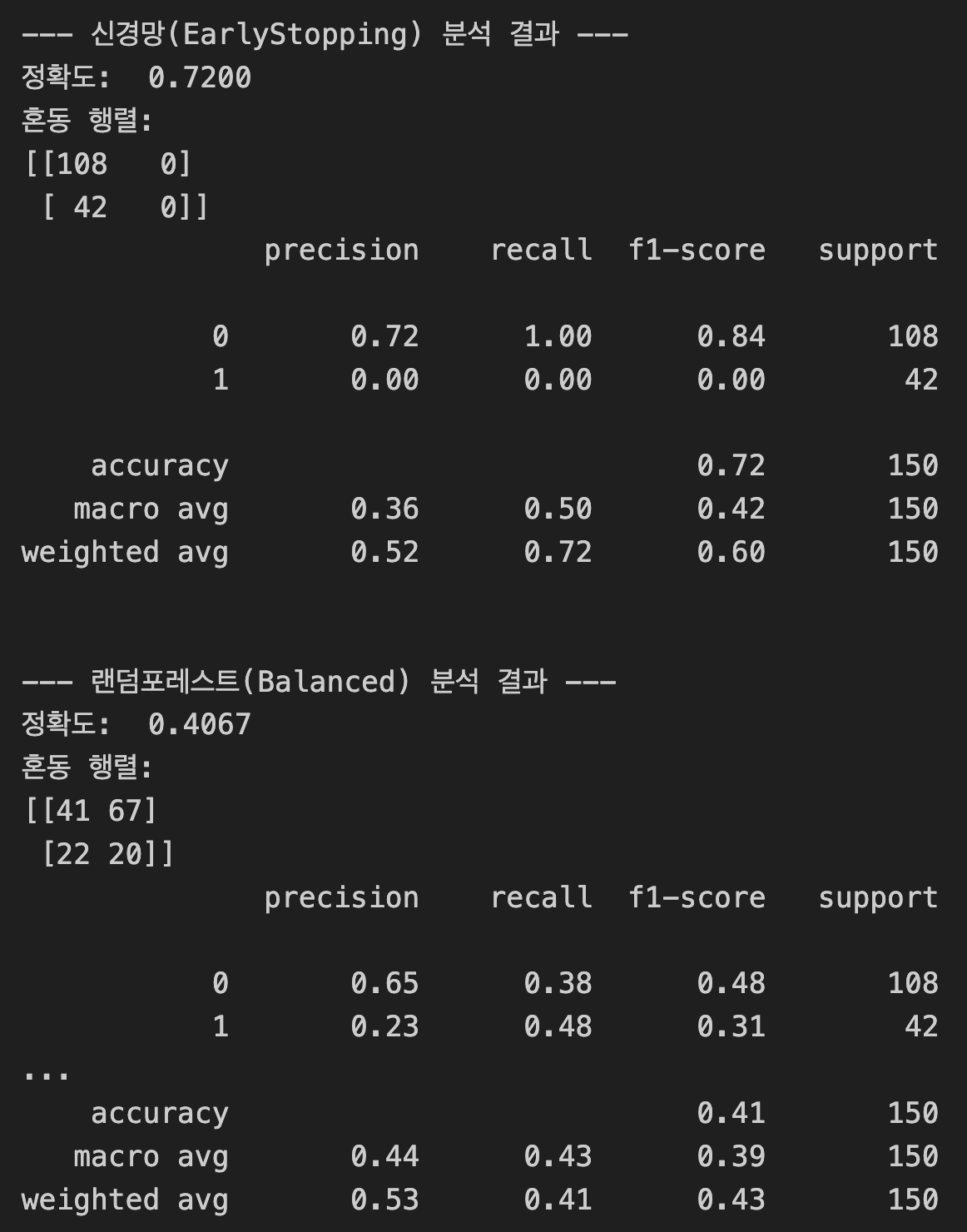
신경망(MLP) 결과: "안전하지만 무능한 우등생"
- 정확도(0.7200): 숫자는 높지만 속임수이다. 모든 사람을 '미수료(0)'라고 찍어서 맞힌 점수이다.
- 문제점: 혼동 행렬을 보면 수료자(1) 42명 중 단 한 명도 찾아내지 못했다(recall = 0.00). 딥러닝 모델은 데이터 불균형이 심할 경우, 대다수를 차지하는 쪽으로만 답을 내놓는 편향에 빠지기 쉽다는 것을 다시 한번 확인했다.
랜덤 포레스트(Balanced) 결과: "성적은 낮아도 진짜 범인을 잡는 탐정
- 정확도(0.4067): 신경망보다 낮아 보이지만 이 모델이 훨씬 더 가치 있는 모델이다.
- 성과: 혼동 행렬의 (1, 1) 위치를 보면 20명을 정확히 찾아냈다.
- Recall(재현율) 0.48: 실제 수료자 42명 중 거의 절반(48%)을 찾아냈다는 뜻이다. 0명이었던 신경망에 비해 비약적인 발전이다.
- 비결: class_weight='balanced' 설정 덕분에 AI가 "수료자(1) 한 명을 놓치는 게 미수료자(0) 열 명을 틀리는 것보다 더 뼈아프다"라고 인식하고 적극적으로 1번을 골라낸 것이다.
💡 오늘의 핵심 인사이트: "정확도의 함정"
공모전이나 실무에서는 단순히 정확도(Accuracy)만 높이는 것이 정답이 아니다. 만약 "암 환자를 찾는 AI"라면, 암이 아닌 사람을 암이라고 오진하는 것보다 암 환자를 못 보고 지나치는 것이 훨씬 위험하기 때문이다.

AI/ML Engineer 🧑💻