
저장한 test_data.csv를 불러오는 것부터 시작해서, 데이터의 이상치(Outlier)를 잡아내고 통계적으로 요약
import pandas as pd
class FinalDataAnalyzer:
def __init__(self, file_path: str):
try:
self.df = pd.read_csv(file_path)
print(f"[성공] {file_path} 파일을 불러왔습니다.")
except FileNotFoundError:
print("[오류] 파일이 없습니다. 경로를 확인하세요.")
def remove_outliers(self, column: str, min_val: float, max_val: float):
# [미션 2] 불리언 인덱싱을 활용하세요.
# 해당 컬럼의 값이 min_val보다 크거나 같고(&), max_val보다 작거나 같은 행만 남겨야 합니다.
# self.df = self.df[(조건1) & (조건2)]
before_cnt = len(self.df)
self.df = self.df[(self.df[column] >= min_val) & (self.df[column] <= max_val)]
after_cnt = len(self.df)
print(f"[알림] {column} 이상치 제거 완료 ({before_cnt} -> {after_cnt}행)")
def show_summary(self):
print("\n" + "="*30)
print("데이터 요약 통계")
print("="*30)
print(self.df.describe())
# --- 실행부 ---
# 1. 어제 만든 파일로 분석기 생성
analyzer = FinalDataAnalyzer('test_data.csv')
# 2. 이상치 제거 테스트 (예: 나이는 0~120세, 점수는 0~100점만 정상으로 간주)
analyzer.remove_outliers('age', 0, 120)
analyzer.remove_outliers('score', 0, 100)
# 3. 최종 요약 보고
analyzer.show_summary()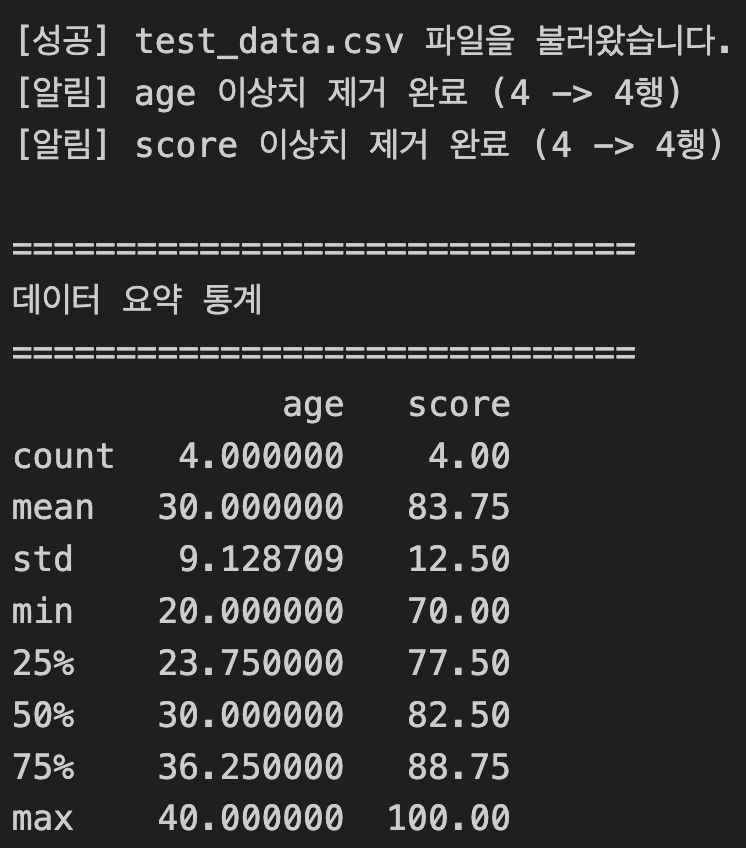
- try-except 사용

AI/ML Engineer 🧑💻