
- 데이터 로드: 외부 데이터를 DataFrame으로 변환
- 데이터 진단: 결측치
- 데이터 처방: dropna(삭제), fillna(채우기)
- 데이터 배포: 파일(to_csv)로 저장
import pandas as pd
import numpy as np
class RealWorldDataAnalyzer:
def __init__(self, data_dict: dict):
self.df = pd.DataFrame(data_dict)
def check_missing(self):
print("\n[결측치 확인]")
print(self.df.isnull().sum())
def fill_missing_score(self):
avg_score = self.df['score'].mean()
self.df['score'] = self.df['score'].fillna(avg_score)
print(f"\n[알림] 점수 빈칸을 평균값({avg_score:.1f})으로 채웠습니다.")
def drop_missing_age(self):
self.df = self.df.dropna(subset=['age'])
print("\n[알림] 나이가 비어있는 행을 삭제했습니다.")
def save_to_csv(self, filename: str):
self.df.to_csv(filename, index=False)
print(f"\n[성공] 데이터가 {filename}으로 저장되었습니다.")
# 실행 테스트
data = {
'name': ['User1', 'User2', 'User3', 'User4', 'User5'],
'age': [20, 25, np.nan, 35, 40],
'score': [80, np.nan, 90, 100, 70]
}
analyzer = RealWorldDataAnalyzer(data)
analyzer.check_missing() # 1. 빈칸 확인
analyzer.fill_missing_score() # 2. 점수 채우기
analyzer.drop_missing_age() # 3. 나이 없는 행 삭제
analyzer.check_missing() # 4. 다시 확인 (모두 0이 나와야 함)
print("\n[최종 데이터]")
print(analyzer.df)
analyzer.save_to_csv('test_data.csv')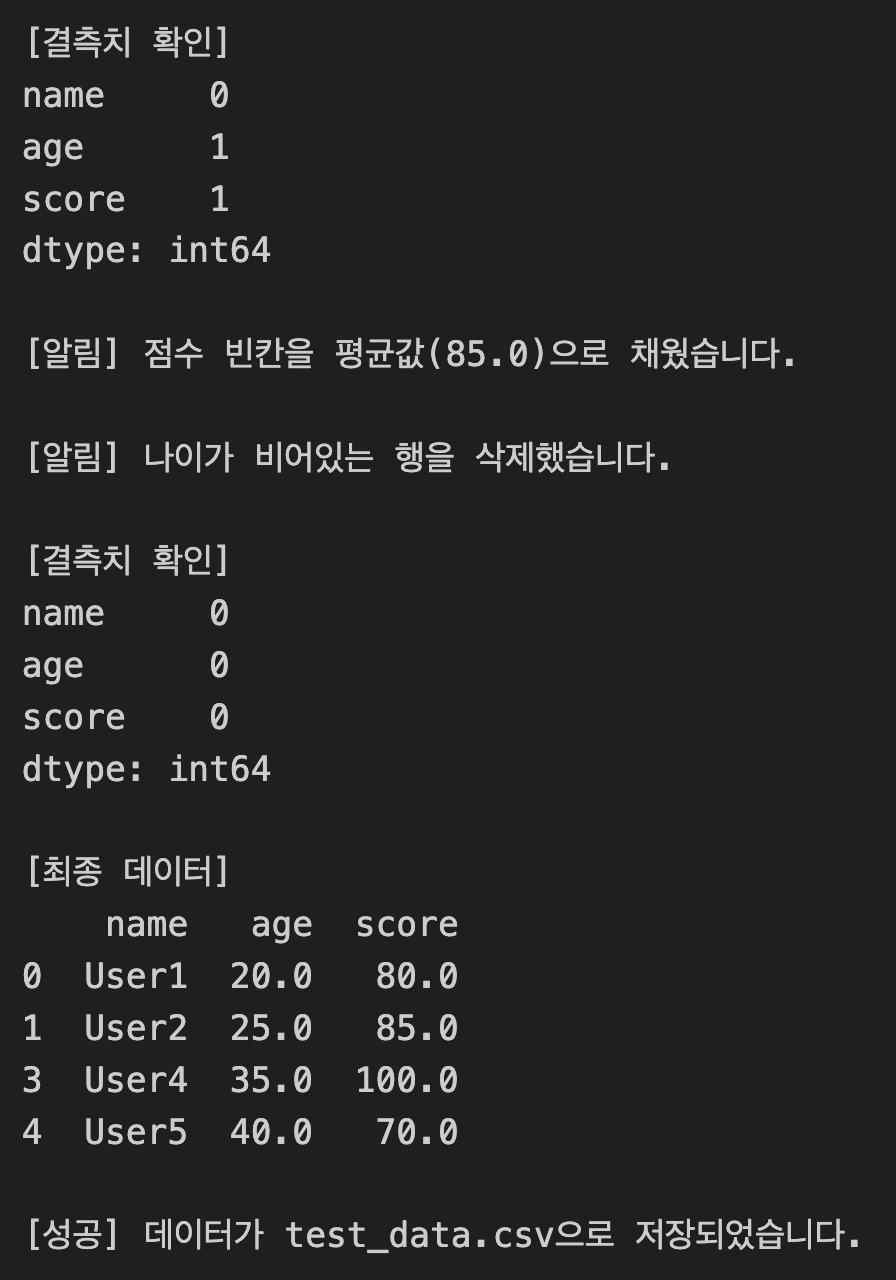


AI/ML Engineer 🧑💻