
3일차: "Pandas"
오늘은 어제 만든 클래스 구조를 활용해 DataProcessor를 만들어 보자.
Pandas는 데이터를 DataFrame이라는 표 형태로 다룬다.
import pandas as pd
import numpy as np
# 1. 샘플 데이터 생성 (이름, 나이, 점수)
data = {
'name': ['Kim', 'Lee', 'Park', 'Choi', 'Jung'],
'age': [20, 25, 30, 35, 40],
'score': [85, 92, 78, 88, 95]
}
df = pd.DataFrame(data)import pandas as pd
class DataProcessor:
def __init__(self, data_dict: dict):
self.df = pd.DataFrame(data_dict)
print("데이터프레임이 생성되었습니다.")
def add_bonus(self):
self.df['score'] = self.df['score'] + 5
def filter_age(self, min_age: int):
filtered_df = self.df[self.df['age'] >= min_age]
print(filtered_df)
return filtered_df
def get_status(self):
avg_score = self.df['score'].mean()
max_age = self.df['age'].max()
print(f"평균 점수: {avg_score: .1f}점")
print(f"최고령 나이: {max_age}세")
def add_grade(self):
# x는 score 컬럼의 개별 값 하나하나를 의미합니다.
self.df['grade'] = self.df['score'].apply(lambda x: 'A' if x >= 90 else ('B' if x >= 80 else 'C'))
print("등급 계산이 완료되었습니다.")
# 실행용 데이터
raw_data = {
'name': ['User1', 'User2', 'User3', 'User4'],
'age': [18, 22, 35, 40],
'score': [70, 80, 90, 100]
}
processor = DataProcessor(raw_data)
processor.add_bonus()
processor.add_grade()
processor.get_status()
print(processor.df)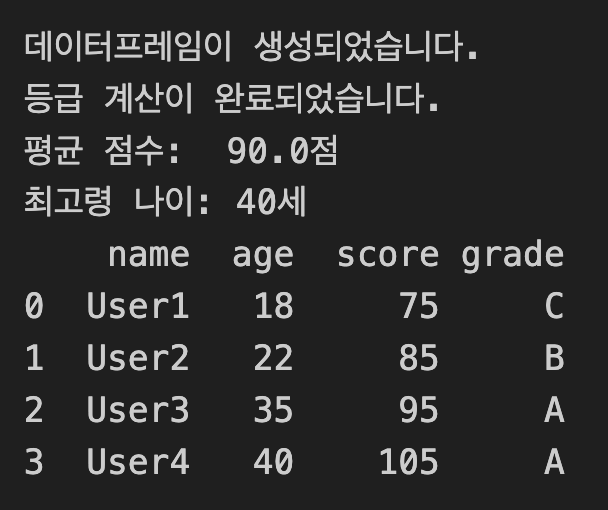
- 브로드캐스팅: for문을 돌리지 않고
self.df['score'] + 5한 줄로 데이터를 한 번에 수정 - 불리언 인덱싱:
df[df['age'] >= 30]처럼 조건식을 써서 원하는 데이터만 골라내는 필터링 기법 - Lamda & Apply: 단순 사칙연산을 넘어
if-else가 들어가는 복잡한 로직을 데이터프레임의 행마다 적용

AI/ML Engineer 🧑💻