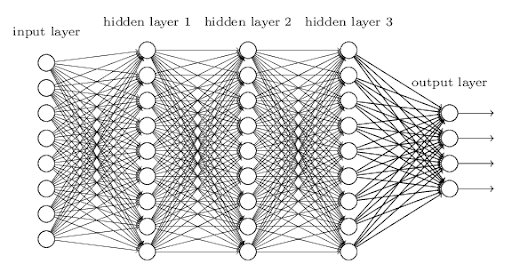
활성화 함수 (Activation Function)
뉴런이 다음 층으로 신호를 보낼 때 사용하는 필터이다.
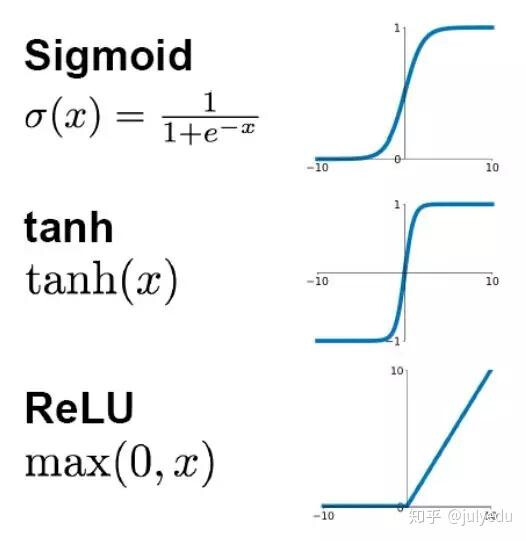
- ReLU: 최근 가장 많이 쓰이는 함수로, 복잡한 데이터 학습 속도가 빠르다.
- Tanh / Sigmoid: 데이터의 특성에 따라 가끔 더 좋은 성능을 내기도 한다.
import pandas as pd
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.preprocessing import StandardScaler
class DeepNetworkPredictor:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
self.features = ['time_input', 'total_class_count', 'is_multi_learner', 'is_extra_class', 'job']
self.target = 'completed'
self.df = self.df[self.features + [self.target]].dropna()
def run_tuned_nn(self):
encoded_df = pd.get_dummies(self.df, columns=['job'])
X = encoded_df.drop(columns=[self.target])
y = encoded_df[self.target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model = MLPClassifier(
hidden_layer_sizes=(64, 32, 16),
activation='relu',
max_iter=1000,
random_state=42
)
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
print(f"--- 튜닝 후 딥러닝 분석 결과 ---")
matrix = confusion_matrix(y_test, y_pred)
print(f"전체 정확도: {accuracy_score(y_test, y_pred): .4f}")
print(f"\n[혼동 행렬]")
print(matrix)
print(f"\nAI가 찾아낸 수료자 수: {matrix[1, 1]}명")
# --- 실행부 ---
predictor = DeepNetworkPredictor('train.csv')
predictor.run_tuned_nn()
MLPClassifier의 디폴트 활성화 함수
별도로 지정하지 않았을 때의 디폴트 값은 'relu'이다.
- 왜 ReLU가 기본일까?
- 학습 속도가 매우 빠르다: 계산이 단순( 이면 , 아니면 )해서 컴퓨터가 아주 좋아한다.
- 기울기 소실 방지: 신경망이 깊어져도 신호가 약해지지 않고 끝까지 잘 전달되는 특성이 있다.

AI/ML Engineer 🧑💻