딥러닝 모델, 특히 인공신경망은 숫자의 크기에 매우 민감하다.
왜 스케일링이 필요한가?
우리가 사용하는 데이터를 보면:
- time_input: 0에서 24사이 (시간 단위)
- is_multi_learner: 0아니면 1 (여부 단위)
인공지능 입장에서는 단순히 숫자가 큰 time_input이 훨씬 더 중요한 정보라고 착각하기 쉽다. 축구 경기로 치면, 키가 큰 선수가 무조건 골을 잘 넣을 거라고 판단하는 것과 비슷하다. 모든 선수의 능력을 공평하게 평가하려면 키, 몸무게, 속도를 동일한 기준으로 맞춰줘야 한다.
StandardScaler (표준화)
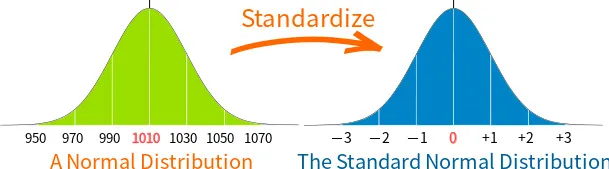
가장 많이 쓰이는 방법으로, 데이터의 평균을 0, 표준편차를 1로 만들어준다. 이렇게 하면 모든 변수가 '평균에서 얼마나 떨어져 있는가'라는 동일한 저울 위에서 평가받게 된다.
import pandas as pd
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.preprocessing import StandardScaler
class ScaledDeepLearningPredictor:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
self.features = ['time_input', 'total_class_count', 'is_multi_learner', 'job']
self.target = 'completed'
self.df = self.df[self.features + [self.target]].dropna()
def run_scaled_nn(self):
# 1. 인코딩
encoded_df = pd.get_dummies(self.df, columns=['job'])
X = encoded_df.drop(columns=[self.target])
y = encoded_df[self.target]
# 2. 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 스케일링 적용
scaler = StandardScaler()
# 학습 데이터로 기준을 잡고 변환
X_train_scaled = scaler.fit_transform(X_train)
# 테스트 데이터는 학습 데이터의 기준으로 변환
X_test_scaled = scaler.transform(X_test)
# 스케일링된 데이터로 모델 학습
model = MLPClassifier(hidden_layer_sizes=(16, 8), max_iter=1000, random_state=42)
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
print(f"--- 스케일링 적용 후 딥러닝 분석 결과 ---")
print(f"전체 정확도(Accuracy): {accuracy_score(y_test, y_pred): .4f}")
print("\n[혼동 행렬(Confusion Matrix)]")
matrix = confusion_matrix(y_test, y_pred)
print(matrix)
actual_positive_hits = matrix[1, 1]
print(f"\nAI가 실제로 찾아낸 수료자 수: {actual_positive_hits}명")
# --- 실행부 ---
predictor = ScaledDeepLearningPredictor('train.csv')
predictor.run_scaled_nn()
fit_transform vs transform: 학습 데이터로 저울의 기준(fit)을 잡고 변환(transform)하는 것이다. 테스트 데이터는 이미 만들어진 저울에 올리기만 하면 된다.
max_iter는 인공지능이 데이터를 최대 몇 번 반복해서 학습할지 정하는 숫자이다.
- 비유: 시험을 앞둔 학생이 문제집을 최대 몇 회독 할지 정하는 것과 같다.
- 작동 원리: 딥러닝 모델은 한 번에 정답을 맞히지 못한다. 처음에 틀린 부분을 수정하면서 점점 정답에 가까워지는데, 이 수정을 최대 max_iter 횟수만큼 반복한다.
- 너무 작으면?: 공부를 하다 말고 시험장에 들어가는 것과 같아서 성능이 충분히 나오지 않는다 (미수렴).
- 너무 크면?: 공부를 아주 꼼꼼히 하겠지만, 시간이 너무 오래 걸리거나 문제집 자체를 통째로 외워버리는 과적합(Overfitting)이 발생할 수 있다.

AI/ML Engineer 🧑💻