손실(Loss)이란?
모델이 내놓은 예측값과 실제 정답 사이의 '틀린 정도'를 숫자로 표현한 것이다. 학습의 목표는 이 Loss 값을 0에 가깝게 만드는 것이다.
손실 곡선(Loss Curve)을 보는 이유
- 학습 확인: 그래프가 매끄럽게 아래로 내려가고 있다면 공부를 아주 잘하고 있는 것이다.
- 학습 중단 시점 파악: 그래프가 더 이상 내려가지 않고 평평해진다면, "아, 이제 더 가르쳐봐야 성적이 안 오르겠구나"라고 판단할 수 있다.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.preprocessing import StandardScaler
class VisualizedDeepLearningPredictor:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
self.features = ['time_input', 'total_class_count', 'is_multi_learner', 'is_extra_class', 'job']
self.target = 'completed'
self.df = self.df[self.features + [self.target]].dropna()
def run_and_plot(self):
# 1. 전처리 (인코딩 및 스케일링)
encoded_df = pd.get_dummies(self.df, columns=['job'])
X = encoded_df.drop(columns=[self.target])
y = encoded_df[self.target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 2. 모델 설정 및 학습
model = MLPClassifier(
hidden_layer_sizes=(64, 32, 16),
activation='relu',
max_iter=1000,
random_state=42
)
model.fit(X_train_scaled, y_train)
# 3. 결과 출력
y_pred = model.predict(X_test_scaled)
print(f"--- 시각화 포함 분석 결과 ---")
print(f"전체 정확도: {accuracy_score(y_test, y_pred): .4f}")
print("\n[혼동 행렬]")
print(confusion_matrix(y_test, y_pred))
# 손실 곡선
plt.figure(figsize=(10, 5))
plt.plot(model.loss_curve_)
plt.title("Model Learning Process (Loss Curve)")
plt.xlabel("Iterations (Learning Steps)")
plt.ylabel("Loss (Error Amount)")
plt.grid(True)
plt.savefig("loss_curve.png")
print("\n학습 과정 그래프가 'loss_curve.png'로 저장되었습니다.")
# --- 실행부 ---
predictor = VisualizedDeepLearningPredictor('train.csv')
predictor.run_and_plot()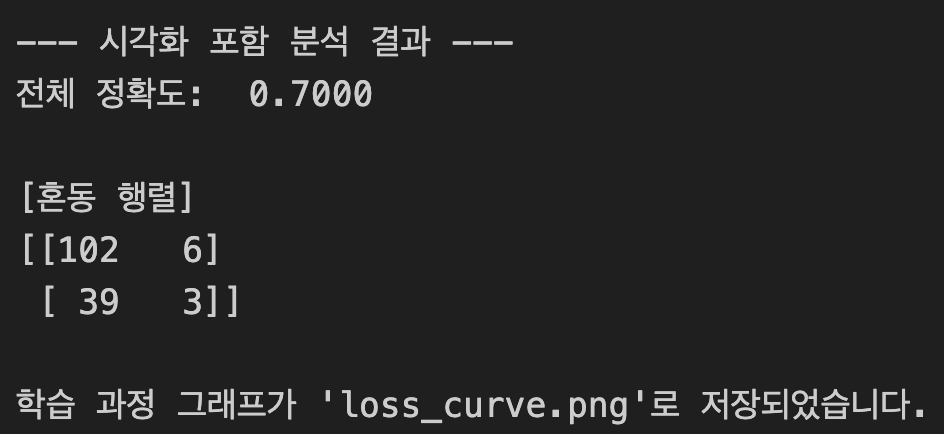
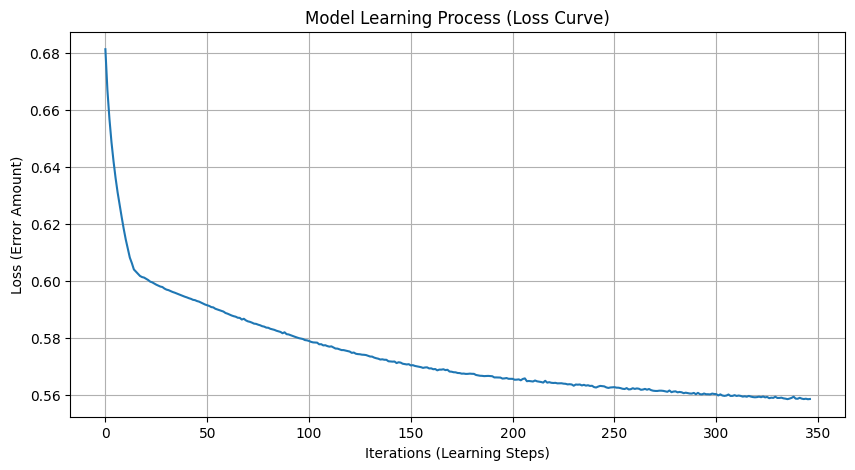
- 그래프의 모양: 초반에는 뚝 떨어지다가 완만하게 수렴하는 곡선이 나오면 아주 건강한 학습이다.
- 진동 여부: 만약 그래프가 위아래로 심하게 요동친다면 학습률(Learning Rate)이나 전처리에 문제가 있다는 신호이다.

AI/ML Engineer 🧑💻