쓰게된 계기
- 사내 프로젝트에서 보안이 매우 중요한 라이센스 키 관리 프로젝트를 맡게 되었다.
- 설계, 개발, 유지보수까지 모두 참여할 수 있는 좋은 기회라 프로젝트를 즐겁게 개발하고 있는데, 갑자기 문뜩 보안이 매우 중요한건데 이렇게 개발해도 되는걸까? 라는 생각을 하게 되었다.
- 일단 가장 먼저 고려했던 사항은 SQL Injection이었다.
- 왜냐하면 가장 접근하기 쉽고 ID 값으로만 유추할 수 있는 데이터가 많았기에 이 부분을 어떻게 해야할까 고민을 하게 되고 실제로 프로젝트에 도입한 것 까지 경험을 정리하게 되었다.
JPA의 기본 키 생성 전략과 각 전략의 특징 및 단점
JPA (Java Persistence API)는 객체 관계 매핑 (ORM)을 위한 표준 Java API로, 다음과 같은 네 가지 기본 키 생성 전략을 제공한다:
AUTO:- 특정 데이터베이스에 맞는 기본 키 생성 전략을 자동으로 선택한다. 사용되는 전략은 다음과 같다:
- MySQL:
AUTO_INCREMENT - PostgreSQL:
SERIAL - Oracle: 시퀀스 사용
- SQL Server:
IDENTITY
- MySQL:
- 데이터베이스 변경 시 코드 수정 없이 자동으로 적절한 키 생성 전략이 적용되지만, 대량 데이터 처리 시 성능 문제가 발생할 수 있다.
- 특정 데이터베이스에 맞는 기본 키 생성 전략을 자동으로 선택한다. 사용되는 전략은 다음과 같다:
IDENTITY:- 데이터베이스의
AUTO_INCREMENT,SERIAL,IDENTITY컬럼을 사용하여 PK를 자동으로 증가시킨다. - 엔티티 저장 시 즉시
INSERTSQL이 실행되어야 하며, 특히 대량 데이터 처리 시 데이터베이스와의 지속적인 I/O로 인해 성능 저하가 발생할 수 있다. IDENTITY전략 사용 시, 엔티티가 데이터베이스에 삽입될 때까지 ID 값이 생성되지 않아, 트랜잭션 내에서 ID에 접근하기 어렵다.
- 데이터베이스의
SEQUENCE:- 데이터베이스 시퀀스를 사용하여 PK를 생성한다. 시퀀스 값은 데이터베이스에서 관리되며, 일반적으로 Oracle, PostgreSQL에서 사용된다.
- 트랜잭션 시작 시 미리 시퀀스 값을 가져오므로, 데이터베이스 I/O를 줄일 수 있어 대량의 데이터 처리 시 성능이 향상된다.
- 그러나 일부 데이터베이스(예: MySQL)에서는 네이티브 시퀀스를 지원하지 않아 사용할 수 없다.
TABLE:- 키 생성 전용 테이블을 사용하여 PK를 생성한다. 이 방식은 모든 데이터베이스에서 사용 가능하며, 다양한 데이터베이스 시스템 간 이식성이 높다.
- 하지만, 매번 사용자 생성 시 키 생성 테이블을 조회하고 업데이트해야 하므로 대용량 트래픽이 발생하는 경우 병목 현상이 발생할 수 있으며, 전체 시스템의 성능 저하를 초래할 수 있다.
JPA 기본 키 생성 전략의 단점
IDENTITY전략의 단점- 성능 저하
- 온라인 상점에서 대규모 상품 목록을 데이터베이스에 삽입하는 상황을 가정해 보겠다.
- 이 상점의 데이터베이스는
IDENTITY전략을 사용하여 각 상품의 ID를 자동으로 증가시키고 있다.@Transactional public void batchInsertProducts(List<Product> products) { for (Product product : products) { entityManager.persist(product); // 각 상품 삽입마다 데이터베이스는 AUTO_INCREMENT 값을 찾아서 업데이트합니다. } } - 만약 이 리스트에 수천 개의 상품이 있고, 모든 상품을 순차적으로 삽입해야 한다면, 데이터베이스는 각 삽입 연산마다
AUTO_INCREMENT값을 업데이트하기 위해 해당 테이블을 조회해야 한다. - 이런 방대한 양의 삽입이 일어날 때, 데이터베이스 서버에는 큰 부하가 걸리고, 결과적으로 상품 삽입 처리 시간이 매우 길어지는 성능 저하를 겪게 된다.
- 트랜잭션 범위 내 ID 접근 불가
- 한 트랜잭션에서 사용자와 사용자의 계정을 생성하는 경우를 생각해보자.
- 사용자 ID가 생성되고 나서야, 해당 ID를 사용하여 계정을 생성해야 한다.
@Transactional public void createUserAndAccount(UserDTO userDTO) { User user = new User(); user.setName(userDTO.getName()); userRepository.save(user); // 이 시점에서 user.getId()는 null이 될 수 있다. Account account = new Account(); account.setUserId(user.getId()); // user ID가 필요하다. accountRepository.save(account); // user ID는 삽입 이후에야 사용 가능하다. } IDENTITY전략을 사용하면user엔티티가 실제로 데이터베이스에 삽입될 때까지 ID가 생성되지 않는다.- 이는 JPA가
user엔티티를 영속성 컨텍스트에 추가하고 트랜잭션을 커밋하는 시점까지 기다려야 한다는 것을 의미한다. - 따라서
account엔티티에user의 ID를 설정하기 전에는user가 실제로 데이터베이스에 삽입되었는지 확인하기 어렵다. - 이는 특히 계정 생성 로직이
user엔티티의 ID에 의존하는 경우 문제가 될 수 있다.
- 성능 저하
SEQUENCE전략의 단점
- MySQL 데이터베이스를 사용 중인데, 시스템의 일부를 PostgreSQL로 마이그레이션하면서
SEQUENCE전략을 도입한다는 가정 - PostgreSQL은
SEQUENCE객체를 네이티브로 지원하지만, MySQL은SEQUENCE객체를 네이티브로 지원하지 않다. - 따라서 MySQL 데이터베이스를 사용하는 환경에서는
SEQUENCE전략을 사용할 수 없다.
- MySQL 데이터베이스를 사용 중인데, 시스템의 일부를 PostgreSQL로 마이그레이션하면서
TABLE전략의 단점TABLE전략을 사용하여 사용자 테이블에 대한 PK를 관리하고 있다.- 이 전략은 키 생성 전용 테이블을 두어 PK 값을 관리한다.
- 매번 사용자를 생성할 때마다 키 생성 테이블을 조회하고 업데이트해야 한다.
- 대용량 트래픽이 발생하는 경우, 이 테이블이 병목 지점이 될 수 있고, 결국 전체 시스템의 성능 저하를 초래할 수 있다.
AUTO전략의 단점- 어떤 회사에서 여러 데이터베이스 시스템을 사용한다고 가정하겠다. (예: Oracle, MySQL, PostgreSQL).
- 개발 팀은 어플리케이션 내에서 JPA
AUTO전략을 채택하였다. - 개발 팀이 공통된 코드 베이스를 사용하여 플랫폼을 개발했음에도 불구하고, 각 데이터베이스에서
AUTO전략이 다르게 동작하는 것 발견함. - 예를 들어, Oracle은
SEQUENCE를 사용하는 반면, MySQL은IDENTITY를 사용한다. - 이로 인해 개발 및 테스트 단계에서 예상치 못한 성능 차이가 발생함.
UUID 키 생성 전략
- UUID (Universally Unique Identifier)는 표준화된 128비트의 숫자를 사용하여 전 세계적으로 고유한 ID를 생성하는 방법이다.
- UUID는 다음과 같은 형식을 갖는다.
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx, 여기서 각 x는 16진수다.
- UUID 생성 전략의 장점은 어떠한 환경에서도 고유한 값을 생성할 수 있다는 것이다.
- 장점
- 전 세계적으로 고유한 값을 생성할 수 있으며 충돌 확률이 매우 낮다.
- UUID는 순차적이지 않아서, 식별자의 순서로부터 어떠한 정보도 유추할 수 없어 보안 측면에서 유리할 수 있다.
- 생성시에 외부 상태에 의존하지 않아서 별도의 관리 없이 독립적으로 생성이 가능하다. → DB 확장성 측면에서 고려해야할 사항들이 줄어듬.
- 단점
- UUID는 128비트 길이로 이루어져 있으며, 이는 기본적인 정수 기반의 ID보다 상당히 길다.
- 대규모 테이블에서는 UUID가 차지하는 저장 공간이 문제가 될 수 있으며, Auto Increment 정수 기반의 키에 비해 약 4배 더 많은 공간을 차지합니다.
- UUID는 생성 시 시간에 기반한 순차성을 가지지 않는다. 이는 특히 B+Tree 인덱스를 사용하는 SQL 데이터베이스에서 단점이 될 수 있다.
- 또한, 쿼리 조회시 정렬이 반 필수적으로 이뤄진다.
- UUID는 문자열로 표현되기 때문에, 데이터베이스에서 정수와 비교할 때 더 많은 시간이 소요된다. 문자열 비교는 정수 비교보다 성능이 약 2.5배에서 28배 정도 저하될 수 있다.
- 관계형 데이터베이스에서 클러스터링된 프라이머리 키를 사용할 경우, 새로운 행이 삽입될 때마다 데이터베이스 엔진이 행을 재정렬해야 합니다. UUID의 무작위성으로 인해 인덱스 페이지 분할과 재정렬이 빈번하게 발생하여 성능이 저하될 수 있습니다.
UUID 키 생성 전략(코드)
- UserUUID
@Entity public class UserUUID { @Id @GeneratedValue(generator = "uuid") @GenericGenerator(name = "uuid", strategy = "uuid2") private UUID id; private String name; private String email; }
ULID 키 생성 전략
- ULID(Universally Unique Lexicographically Sortable Identifier)는 UUID의 대안으로 제안된 식별자이다.
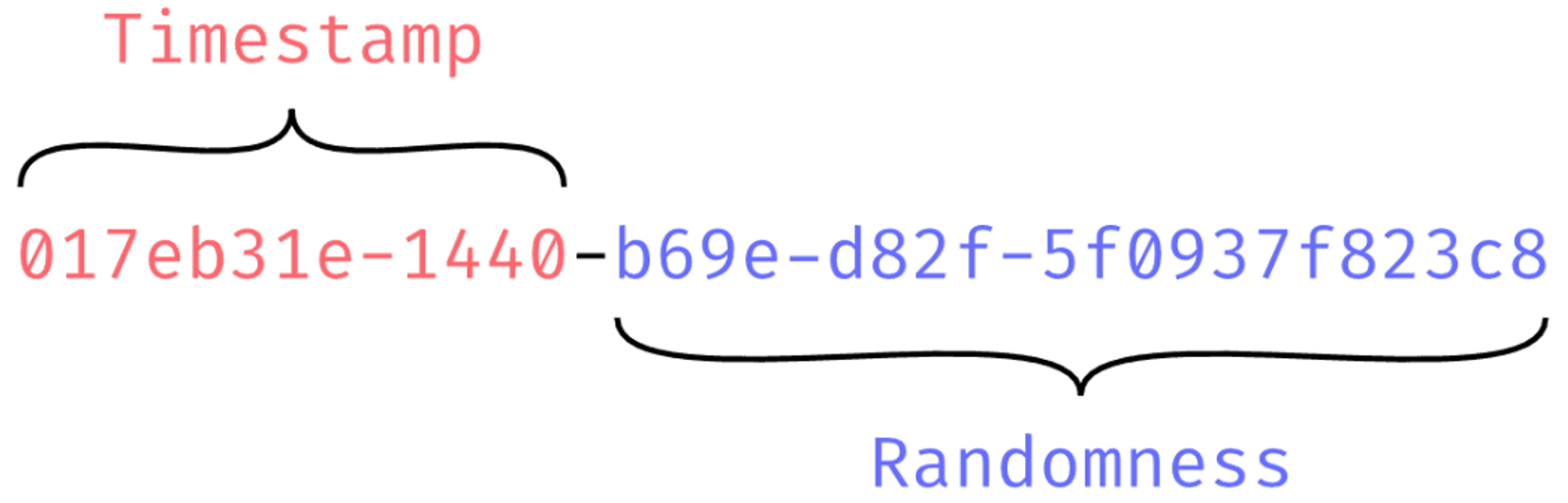
- 장점
- ULID는 시간 기반의 식별자로, 시간에 따른 정렬이 가능하다.
- 이진 형식으로 저장될 때 더 효율적입니다.
- UUID에 비해 정렬이나 검색 성능이 좋기에 인덱스의 순차성을 유지하므로 데이터베이스 성능에 덜 부담을 준다.
- 생성시에 외부 상태에 의존하지 않아서 별도의 관리 없이 독립적으로 생성이 가능하다. → DB 확장성 측면에서 고려해야할 사항들이 줄어듬.
- 단점
- UUID에 비해 상대적으로 새로워서 지원하지 않는 시스템이 있을 수 있다. → 아직은 못 본 문제
- ULID 생성과 처리를 위해서는 추가적인 라이브러리 필요하다.
ULID 키 생성 전략(코드)
- UserULID
@Entity public class UserULID { @Id @GeneratedValue(generator = "ulid-generator") @GenericGenerator(name = "ulid-generator", strategy = "com.example.demo.ulid.ULIDGenerator") private String id; } - ULIDGenerator
public class ULIDGenerator implements IdentifierGenerator { @Override public Serializable generate(SharedSessionContractImplementor session, Object object) { return UlidCreator.getUlid().toString(); } } - build.gradle
dependencies { // ULID implementation 'com.github.f4b6a3:ulid-creator:5.2.3' }
JPA 기본 키 생성 전략 vs UUID(ULID) 키 생성 전략 선택의 기준
- JPA 기본 키
- 테이블이 주로 서버 내부에서 참조되며 클라이언트에게 노출되지 않는 경우, 예를 들어 사용자의 세션 정보나 로그 데이터 등이 이에 해당한다.
- 대규모 데이터를 다루는 서비스에서는 인덱싱 성능이 중요할 수 있으며, Auto Increment Key는 데이터베이스의 B-Tree 구조에 최적화되어 있어 UUID보다 더 빠르게 처리할 수 있다.
- 특정 엔티티를 순차적으로 생성하고 관리할 필요가 있는 경우에 적합하다.
- UUID(ULID) 키
- URL이나 API 응답과 같이 클라이언트에게 노출되고 사용자가 직접 다룰 수 있는 식별자는 UUID를 사용하는 것이 적합하다. 이는 예측이 어렵고, 해킹의 위험을 줄여주기 때문이다. → 예를 들어, 공유된 문서나 공개된 리소스의 식별자로 사용될 수 있다.
- 여러 서버 또는 클라이언트가 동시에 데이터를 생성할 때, UUID는 고유한 값을 보장하기 때문에 충돌 없이 식별자를 생성할 수 있다.
- 사용자 계정, 결제 정보 등과 같이 보안이 중요한 엔티티에는 UUID를 사용하여 예측 불가능하게 만드는 것이 좋다.
각각의 생성 전략의 insert 성능차이는?
- 가장 처음에 성능 테스트를 진행한 건 배치 작업이었다.
- 기존에 알고 있는 내용으로는 JPA 기본 키 생성 전략이 데이터가 많아지면 많아질수록 insert가 느리다고 알고있다.
- 새로운 컬럼이 하나 추가될 때마다 AUTO_INCREMENT 값을 찾아야하고, 업데이트 해줘야하기 때문이다. → DB 병목현상 발생 가능성 농후하다.
- UUID는 비순차적이고 크기가 크기 때문에 B+트리 기반의 인덱스 성능에 영향을 줄 수 있습니다.
- ULID는 순차적인 요소를 도입하여 이러한 문제를 완화하고, B+트리 인덱스의 효율성을 증가시킬 수 있다.
- 그래서 내 예상은 JPA 기본 키 생성 > UUID 기본 키 생성 > ULID 기본 키 생성 순으로 갈 것이라고 예측하였다.
- 대용량(100,000) 데이터 insert 성능 테스트 결과
- JPA 기본 키 생성

- UUID 기본 키 생성

- ULID 기본 키 생성
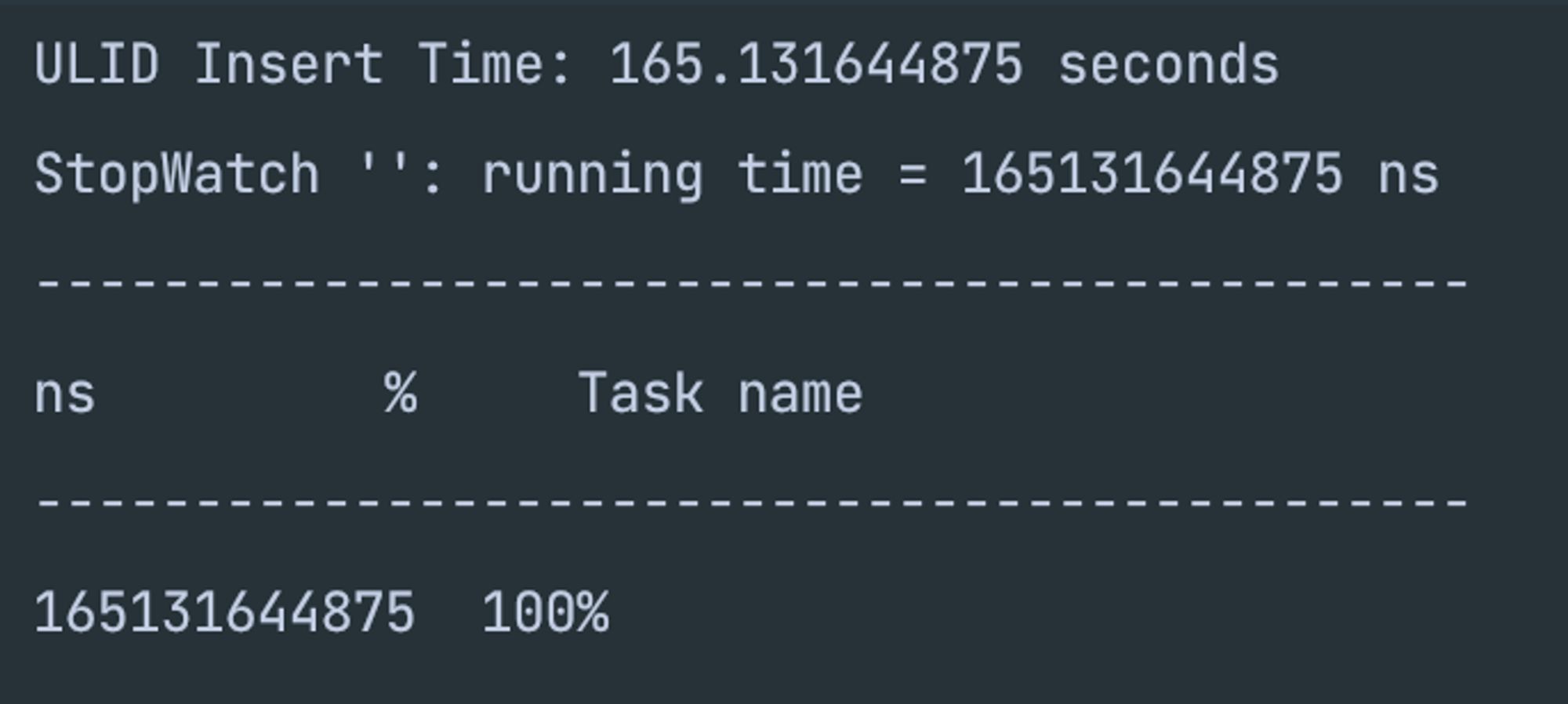
- JPA 기본 키 생성
- 내 생각과는 조금 다르게 결과가 나왔다. → UUID 기본 키 생성 > JPA 기본 키 생성 > ULID 기본 키 생성
- 결과가 조금 다르게 나온 이유는 아마도 B+Tree라고 생각을 한다. → UUID는 B+Tree 기반에서 랜덤하게 index가 들어오면 성능적인 문제가 발생한 것 같다.
- 그리고 당연 ULID가 UUID보다 빠를줄은 알았지만, JPA 기본 키 생성보다 ULID가 월등히 빠를줄은 몰랐다.
- ULID에 대한 마음이 확고해져가는 부분들이다.
각각의 생성 전략의 select 성능차이는?
- 이제는 대용량 insert를 해보았으니, 대용량 select을 해보겠다.
- 기존에 만들어두었던, 100,000건의 데이터를 모두 다 가져온 뒤 순차적으로 조회하는 것으로 성능 테스트를 진행해보았다.
- 일단 내 예상은 UUID 기본 키 생성 > ULID 기본 키 생성 > JPA 기본 키 생성이다.
- 그 이유는 JPA 기본 키 생성은 숫자형 키라 인덱싱 및 데이터의 간단함으로 검색 속도가 제일 빠를 것으로 예상, ULID 기본 키 생성은 UUID보다 문자열 크기가 작기도 하고 부분적으로 순차성이 존재하기에 검색 속도로 따졌을 때는 ULID가 조금 더 빠를 것으로 예상이 된다.
- 대용량(100,000) 데이터 select 성능 테스트 결과
- JPA 기본 키 생성
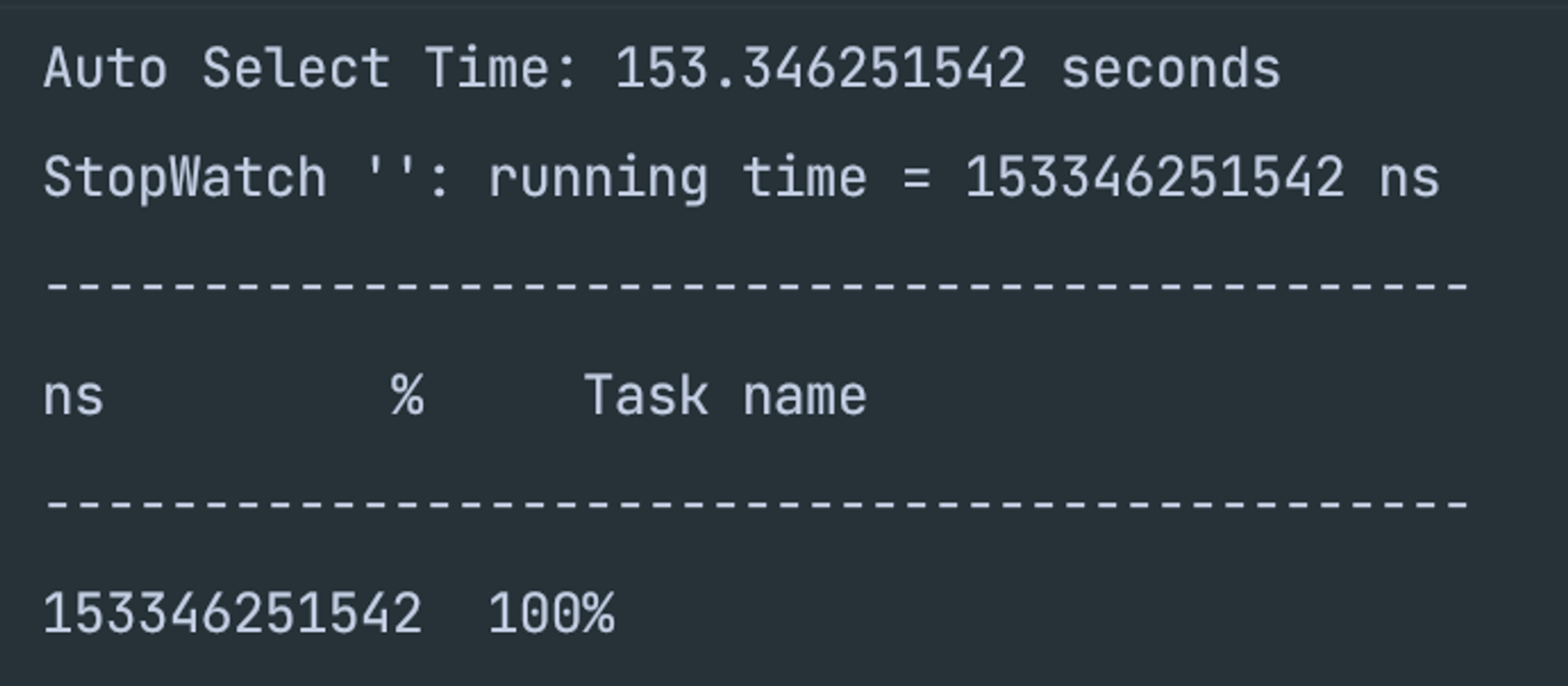
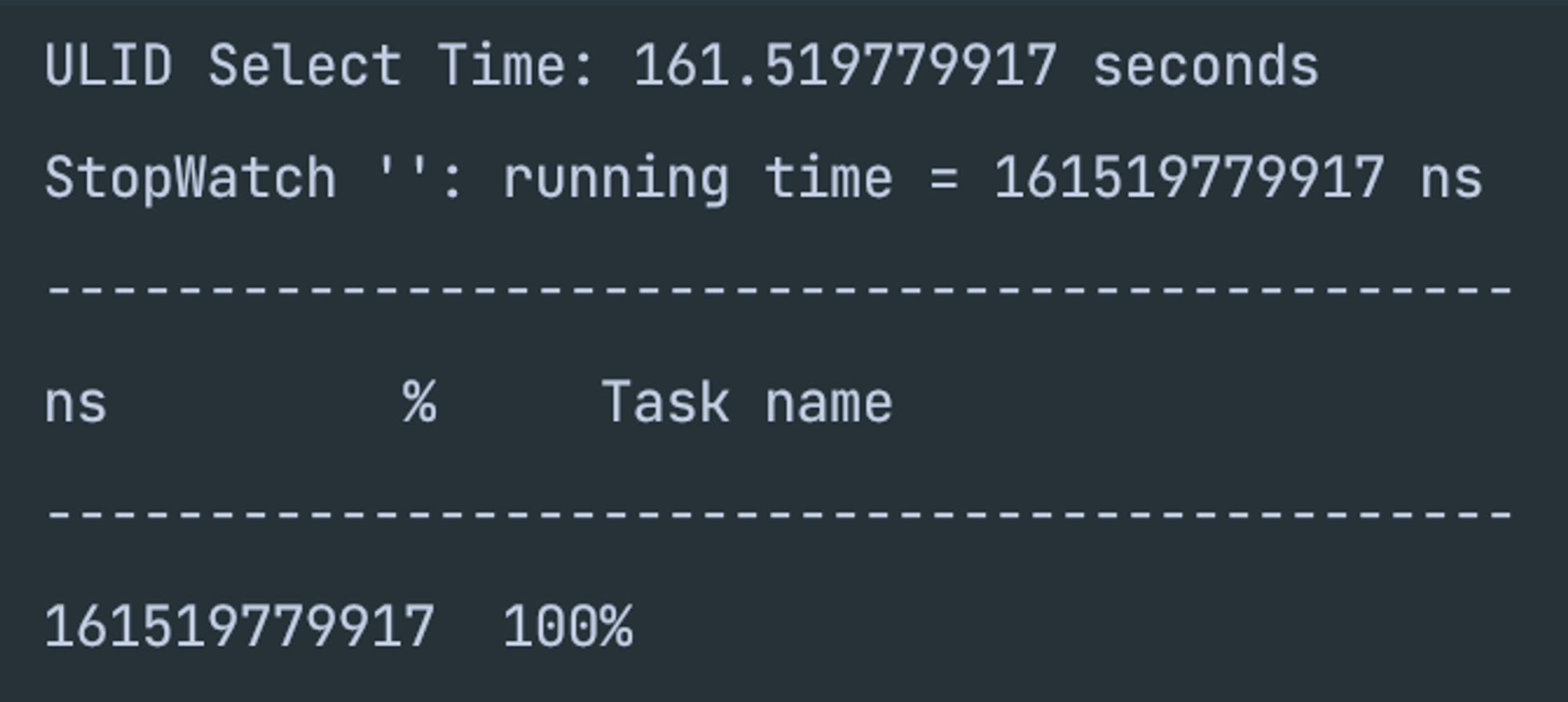
- UUID 기본 키 생성
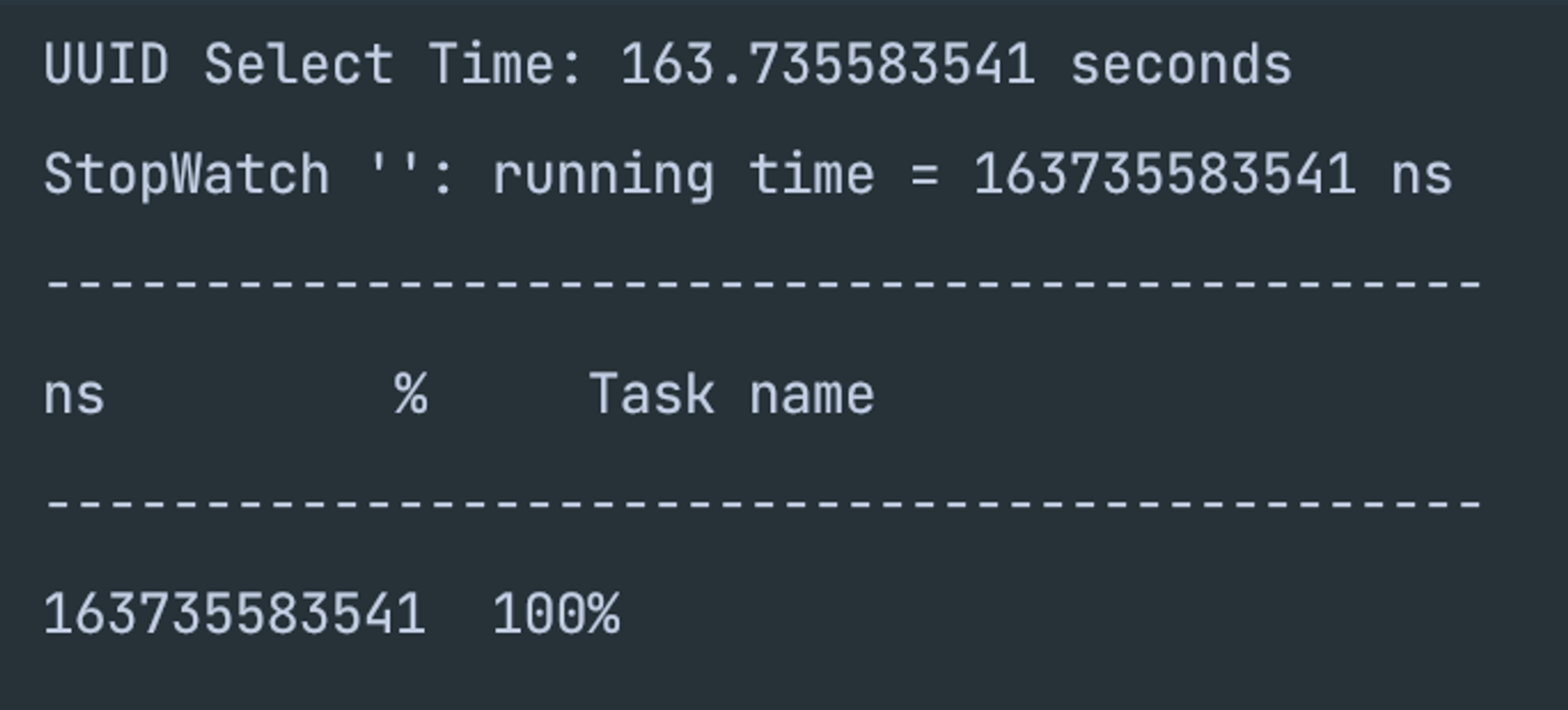
- ULID 기본 키 생성
- JPA 기본 키 생성
- 테스트 결과 내 예상과 동일한 결과로 떨어졌다.
각각의 생성 전략의 random한 select 성능차이는?
- 위에서 한 select은 sort된 테스트 진행 방식이었다.
- 하지만, 운영상에서 누가 index가 정렬된 채로 받고 처리를 하는가? 그렇지 않다고 생각하기에 무작위 정렬을 해둔 뒤 다시 select 하는 성능 테스트를 진행해보았다.
- 이번에도 내 예상은 UUID 기본 키 생성 > ULID 기본 키 생성 > JPA 기본 키 생성이다.
- 랜덤하게 조회를 한다고 해도 인덱스에 대한 키값은 변경되지 않기에 동일한 정렬된 index 조회, 랜덤한 index 조회 둘다 동일한 결과를 띄울것으로 판단이 된다.
- 대용량(100,000) 데이터 random한 select 성능 테스트 결과
- JPA 기본 키 생성
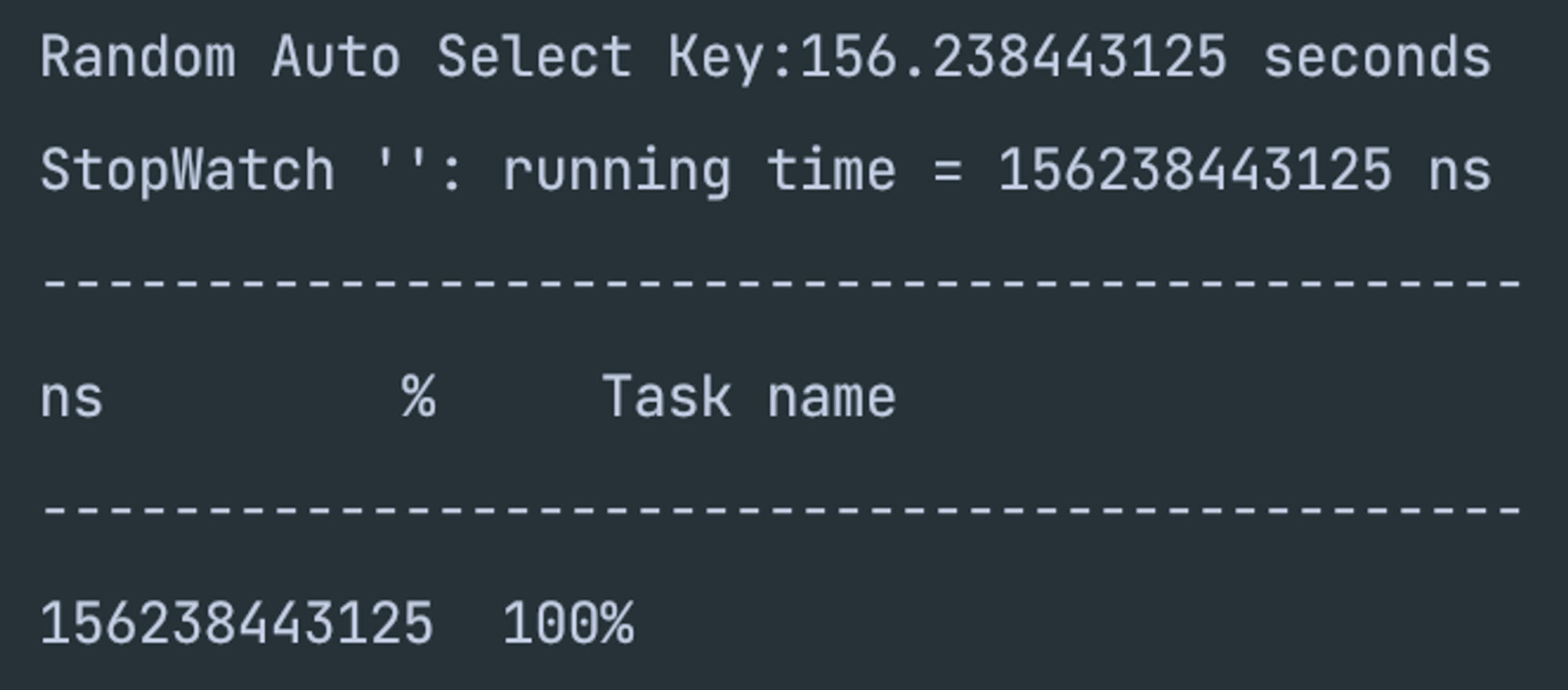
- UUID 기본 키 생성
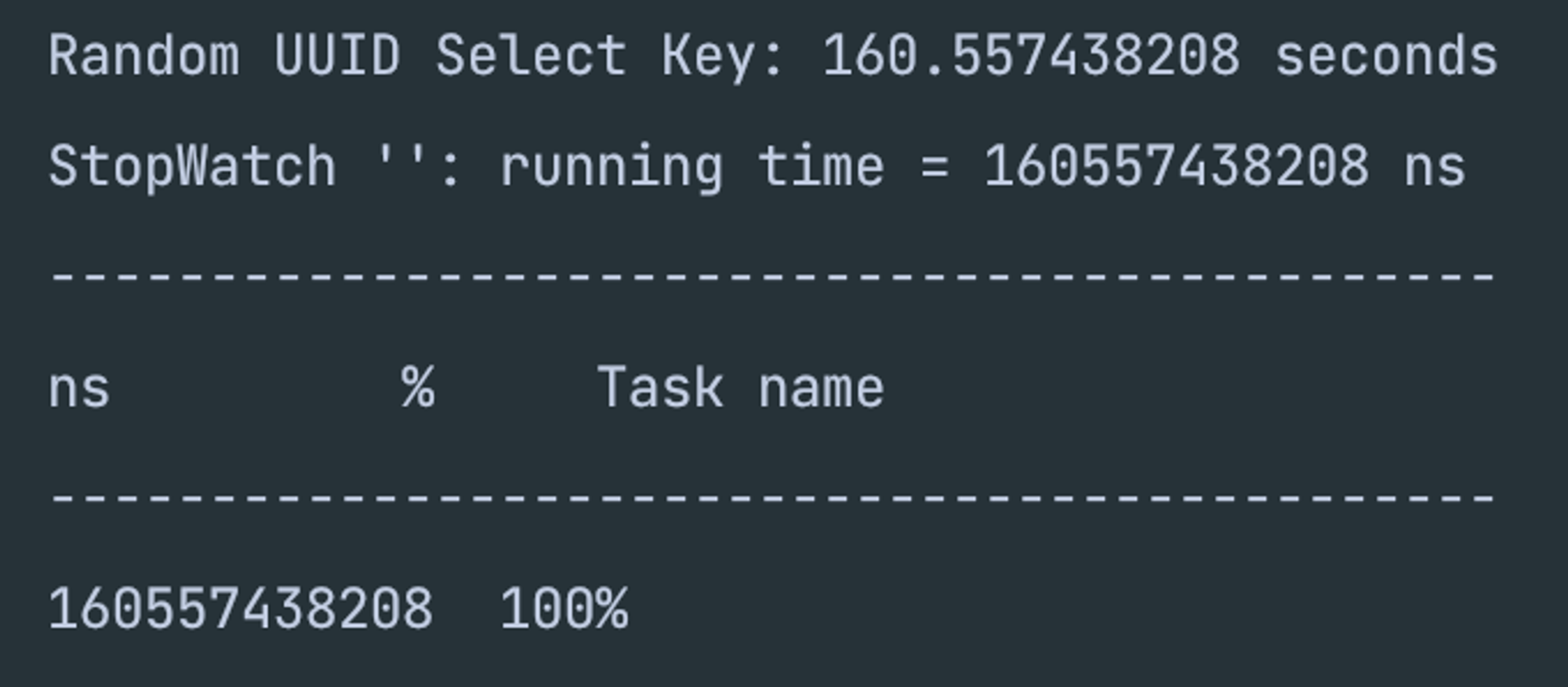
- ULID 기본 키 생성
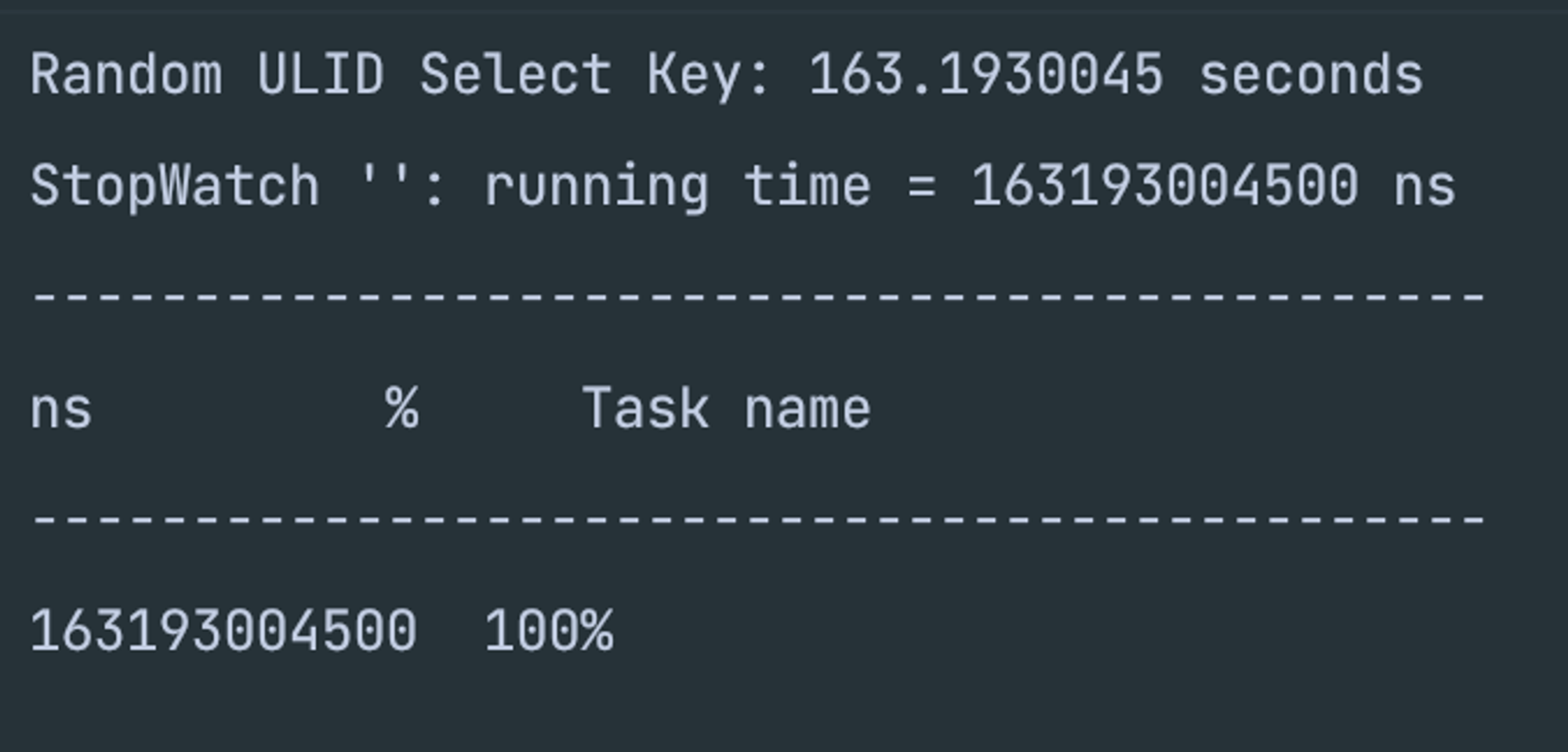
- JPA 기본 키 생성
- 하지만 내 예상과 살짝 벗어나지만, selct은 역시나 JPA 기본 생성자가 가장 빠르고 나머지 UUID, ULID는 거의 비슷한 것 같다.
ULID로의 선택 (결론)
테스트 결과를 종합해보면, ULID가 여러 시나리오에서 균형 잡힌 성능을 보여주는 것으로 나타났다. ULID는 UUID의 고유성과 무작위성을 유지하면서도, 순차적인 요소를 통해 검색 성능과 인덱스 효율성을 향상시키는 이점을 가지고 있다.
- 성능의 균형
- ULID는 JPA 기본 키 생성 전략보다는 일반적으로 삽입 속도에서 뒤처질 수 있지만, 대규모 데이터와 높은 동시성 환경에서는 더 나은 성능을 제공한다.
- 특히, 무작위 접근 패턴에서는 ULID의 순차적 요소가 인덱스 분할 및 재조정 작업을 최소화하여 성능을 향상시킨다.
- 보안성과 고유성
- UUID처럼, ULID도 고유성을 보장하며 예측 불가능한 값을 제공한다.
- 이는 시스템의 보안을 강화하고, 사용자 데이터와 같은 중요 정보에 대한 악의적인 접근을 어렵게 만든다.
- 확장성과 이식성
- ULID는 서버와 클라이언트 간, 또는 분산 시스템 내에서 ID 충돌 없이 사용할 수 있어, 시스템의 확장성을 높인다.
- 이는 클라우드 기반 서비스, 마이크로서비스 아키텍처 및 글로벌 애플리케이션에 특히 중요하다.
- 응용 프로그램 호환성
- ULID는 문자열 기반으로 다루어지기 때문에 다양한 프로그래밍 언어와 프레임워크에서 쉽게 사용할 수 있으며, RESTful API와 같은 인터페이스를 통해 클라이언트에게 노출될 때도 안전하게 사용할 수 있습니다.
이러한 이유로, ULID는 보안이 중요하고, 높은 동시성을 요구하며, 확장성이 중시되는 현대적 애플리케이션 설계에 매우 적합한 기본 키 생성 전략으로 권장된다.
따라서, ULID를 적용함으로써 성능과 보안, 확장성을 모두 만족시키는 효과적인 솔루션을 구현할 수 있다.

지나가는 개발자
설명이 잘 된 글인 것 같습니다!