DB
1.MariaDB Replication 1부
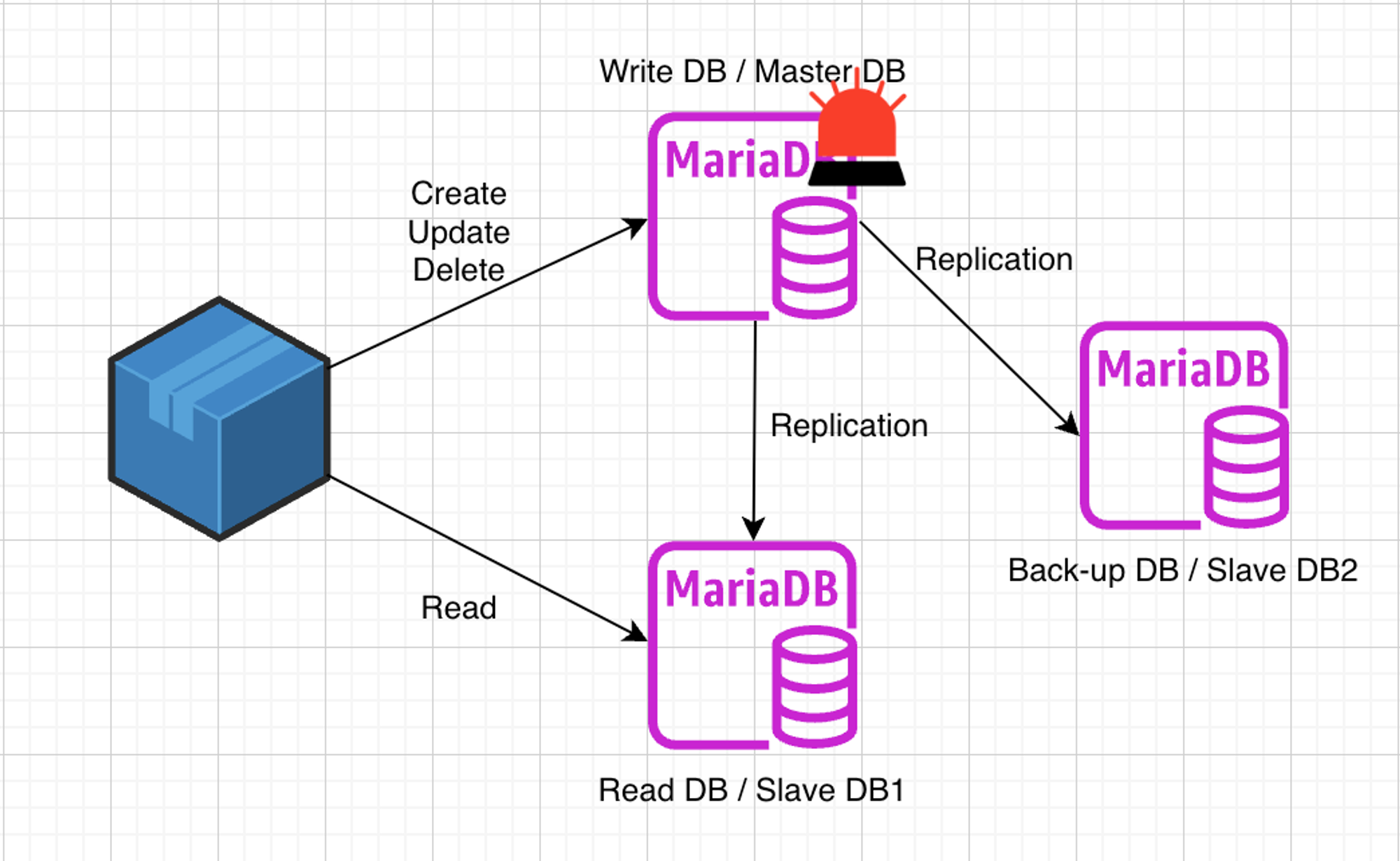
회사에서 지금 진행하고 있는 프로젝트에서는 하나의 서버와 하나의 DB로 구성이 되어있다. 하나의 DB에서 CRUD 연산 작업을 모두 수행하고 있다.본능적으로 뭔가 위험해 보인다고 생각은 하긴 했다…아니나 다를까 프로젝트에 분석 모델이 들어가고 연말에 데이터가 급수적으
2.MariaDB Replication 2부
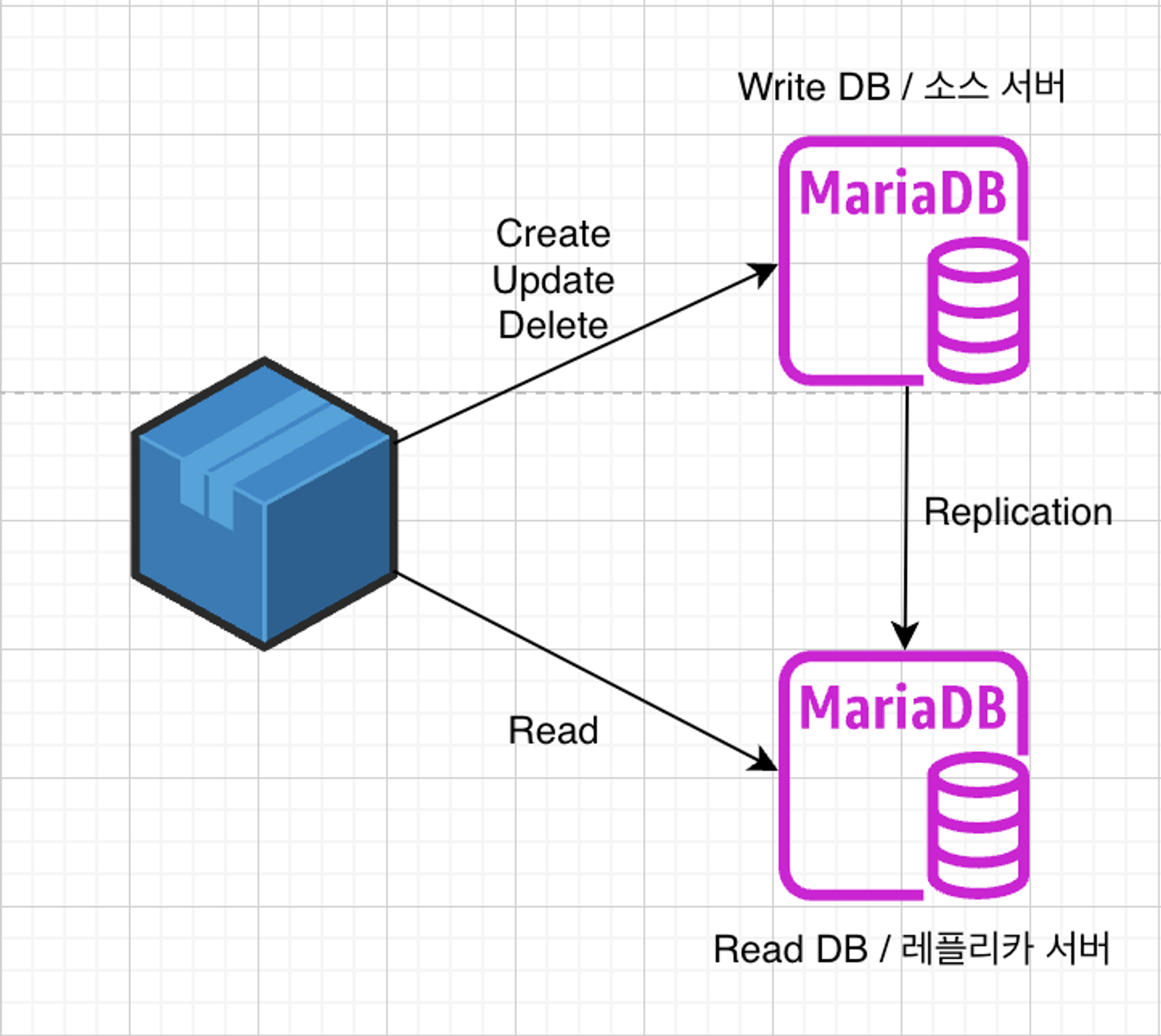
원래 2부를 쓸까 말까 하다가 Replication Topology에 대해 설명과 내가 어떤 구조를 왜 선택했는지 쓰면 좋을 것 같아서 쓰게 되었다.아마 긴글이 되진 않을 것 같긴한데, 누군가에게 도움이 됐으면 하는 바람이다.모든 내용은 Real MySQL 8.0(2)
3.간접 매핑과 DDD

엔티티 간의 관계 설정은 해당 엔티티들이 같은 라이프 사이클을 공유하는지 여부에 따라 달라질 수 있다.여기서 라이프 사이클을 공유한다는 것은 엔티티들이 생성, 수정, 삭제 등의 생명주기를 함께한다는 의미다.반면, 공유하지 않는다면 각 엔티티는 독립적으로 생명주기를 가진
4.우당탕 DB Index 이해하기
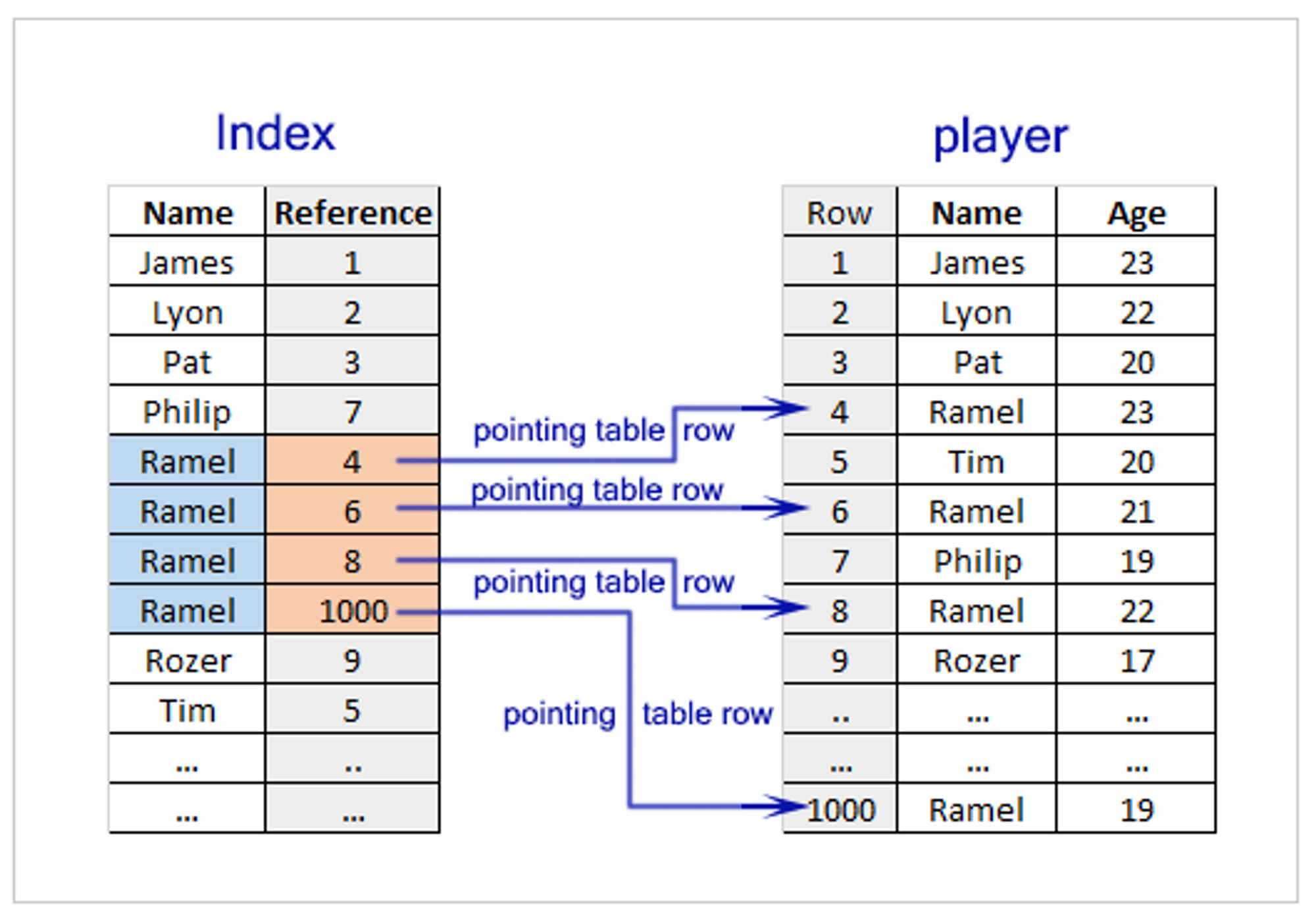
인덱스는 데이터베이스 분야에서 테이블의 검색 속도와 레코드 접근 효율을 높여주는 자료 구조이다.주로 테이블 내의 하나 이상의 컬럼을 기준으로 생성되며, 이를 통해 고속의 검색 동작 및 효율적인 데이터 정렬과 접근을 가능하게 한다.인덱스는 책의 목차와 유사한 역할을 하여
5.DB PK ID 전략
JPA (Java Persistence API)는 객체 관계 매핑 (ORM)을 위한 표준 Java API로, 다음과 같은 네 가지 기본 키 생성 전략을 제공합니다:AUTO:특정 데이터베이스에 맞는 기본 키 생성 전략을 자동으로 선택합니다. 사용되는 전략은 다음과 같습니