1. 인덱스 기초
인덱스란?
- 인덱스는 데이터베이스 분야에서 테이블의 검색 속도와 레코드 접근 효율을 높여주는 자료 구조이다.
- 주로 테이블 내의 하나 이상의 컬럼을 기준으로 생성되며, 이를 통해 고속의 검색 동작 및 효율적인 데이터 정렬과 접근을 가능하게 한다.
- 인덱스는 책의 목차와 유사한 역할을 하여, 대량의 데이터 속에서도 원하는 정보를 빠르게 찾을 수 있도록 도와준다.
인덱스의 필요성
- 데이터베이스 내에서 원하는 데이터를 검색할 때, 조건에 맞는 컬럼에 인덱스가 없다면 데이터베이스 시스템은 테이블 전체를 순차적으로 탐색(Full Table Scan)해야 한다.
- 이는 많은 양의 데이터를 처리할 때 상당한 시간이 소요될 수 있다.
- 인덱스를 적용하면, 검색 쿼리의 성능이 크게 향상되며, 이는 데이터 접근 시간의 단축을 의미한다.
인덱스 표 예시
SELECT * FROM PLAYER WHERE NAME = ?- 만약 데이터베이스의 특정 테이블에서 데이터를 조회할 때 조건절에 사용된 컬럼에 인덱스가 없다면, 데이터베이스는 필요한 데이터를 찾기 위해 테이블의 모든 행을 처음부터 끝까지 전부 확인해야 한다.
- 이를 전체 테이블 탐색, 즉 풀 스캔이라고 한다.
- 책에 목차가 없는 상황을 생각해보면 이해하기 쉽다.
- 특정 내용을 찾고자 할 때, 목차가 없으면 책의 매 페이지를 뒤져야 하듯이, 데이터베이스도 비슷한 방식으로 원하는 정보가 나올 때까지 모든 데이터를 살펴봐야 한다.
- 테이블에 데이터가 많을수록 이런 검색 과정에 소요되는 시간은 더욱 길어지게 된다.
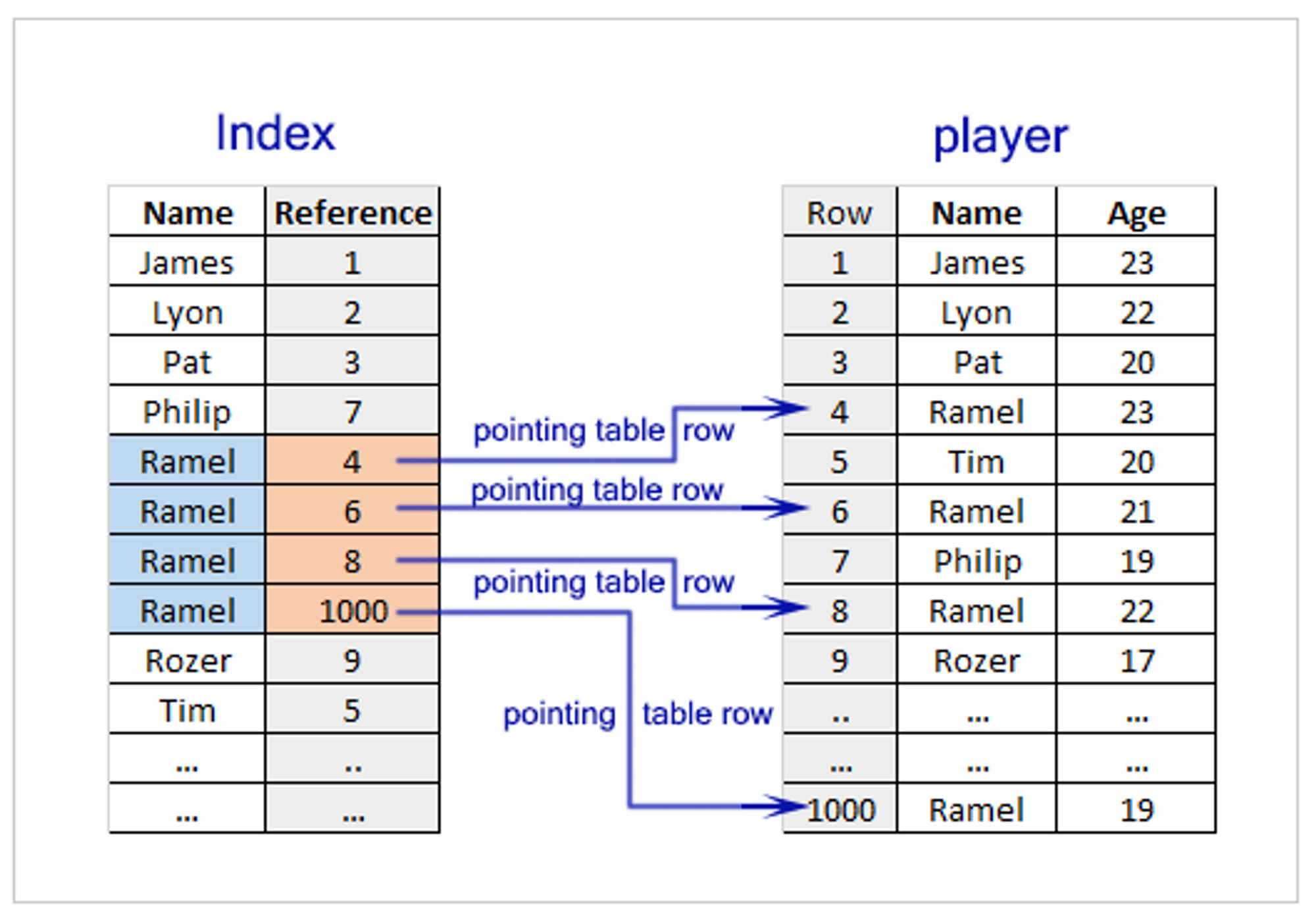
CREATE INDEX PLAYER_NAME_INDEX ON USER(NAME);- Index는 데이터의 주소값을 저장하는 별도의 특별한 자료 구조이다.
- PLAYER 테이블의
NAME컬럼에 대한 Index가 존재한다면, 예시 쿼리를 수행할 때 테이블 전체를 탐색하지 않고 해당 Index를 바탕으로 원하는 데이터의 위치를 빠르게 검색한다. - Index는 테이블에 있는 하나 이상의 컬럼으로 생성이 가능하.
2. 인덱스의 종류
B-Tree 인덱스
- 구조 및 원리
- 균형잡힌 트리 구조: B-Tree(Balanced Tree) 인덱스는 각 노드가 여러 개의 키를 포함할 수 있는 균형 잡힌 트리 구조입니다. 이 구조는 데이터를 빠르게 찾을 수 있도록 하며, 각 노드의 키는 정렬된 상태를 유지한다.
- 키와 포인터: B-Tree의 각 노드는 키와 이 키에 해당하는 값의 위치를 가리키는 포인터들을 포함한다. 노드 내의 키는 왼쪽에서 오른쪽으로 오름차순으로 정렬되어 있으며, 키 사이의 포인터는 해당 키값을 경계로 하는 데이터를 가리킨다.
- 장점
- 효율적인 검색, 삽입, 삭제: B-Tree 구조는 데이터의 삽입, 검색, 삭제 연산을 로그 시간 복잡도로 처리할 수 있어 대용량 데이터를 효율적으로 관리할 수 있다.
- 범위 검색에 유리: B-Tree는 키 값의 범위 검색에 효율적이며, 순차적인 데이터 접근이 가능하다. 이는 트리의 순회를 통해 자연스럽게 정렬된 순서대로 데이터를 검색할 수 있음을 의미한다.
- 사용 사례
- 관계형 데이터베이스 시스템: 대부분의 SQL 기반 데이터베이스 시스템에서 기본 인덱스 구조로 사용된다. 복잡한 쿼리 조건과 다양한 데이터 액세스 패턴을 지원해야 하는 시스템에 적합하다.
- 예시 : Index가 1부터 14까지 있는 B-Tree이다.
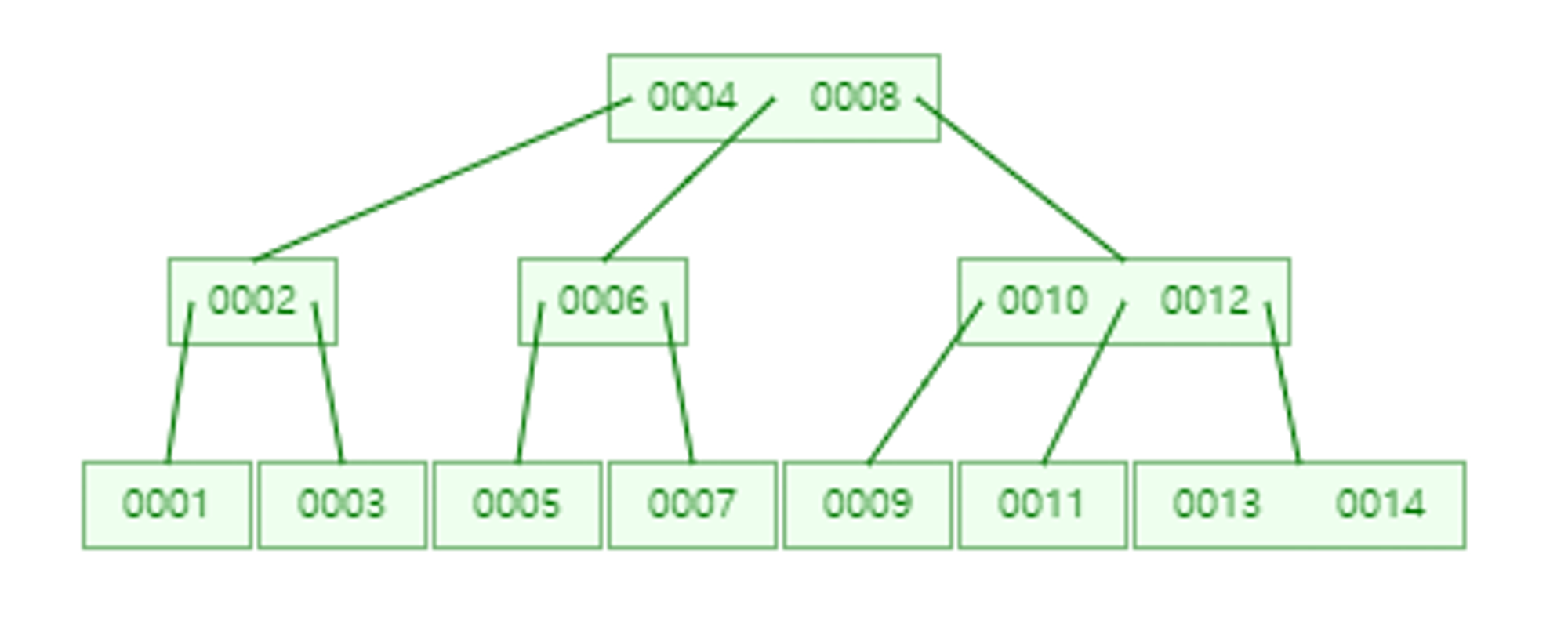
- 기존 B-Tree가 이렇게 구성이 되어 있을 때, 이제 15 Index를 추가하면 아래와 같이 된다.
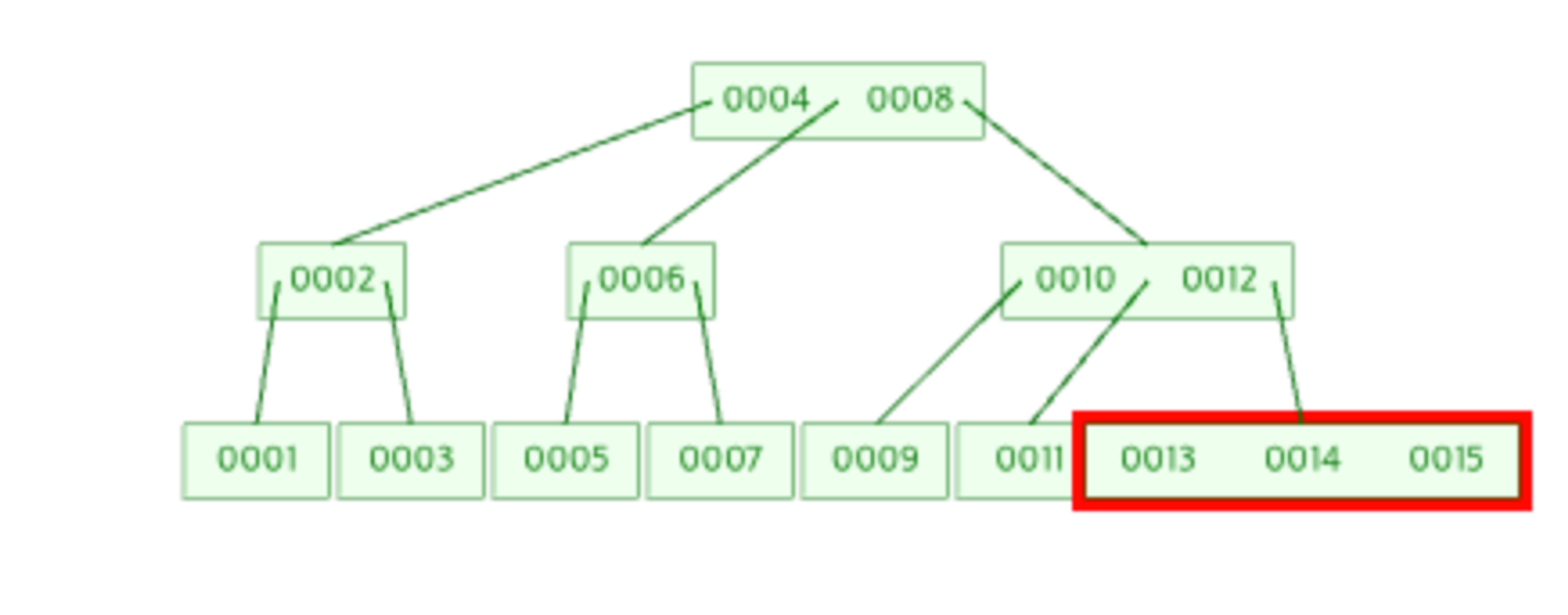
- Index 15는 8보다 크고 12보다 크고 14보다 크므로 14의 오른쪽 node로 추가가 된다.
- 하지만 이진 트리이기에 13, 14, 15중에 가운데인 14가 승격한다.
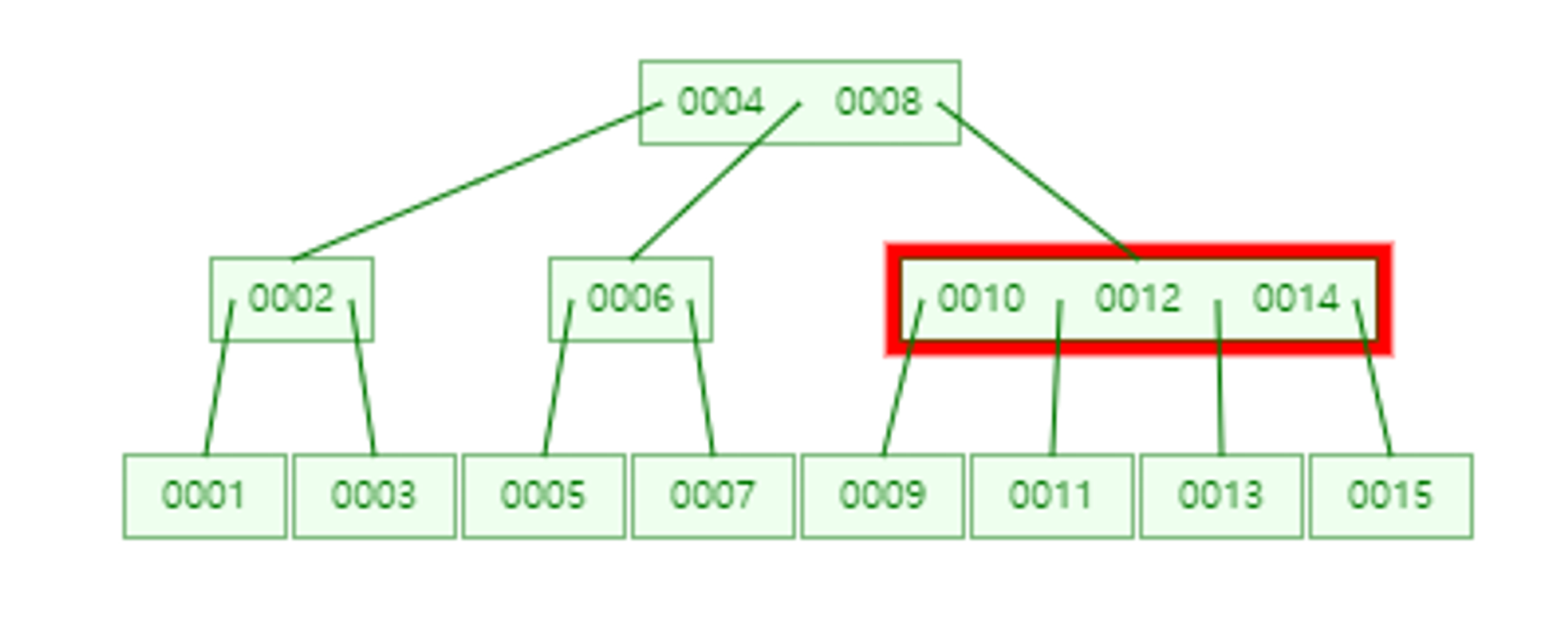
- 또다시 10, 12, 14에서 중간인 12가 다시 승격한다.
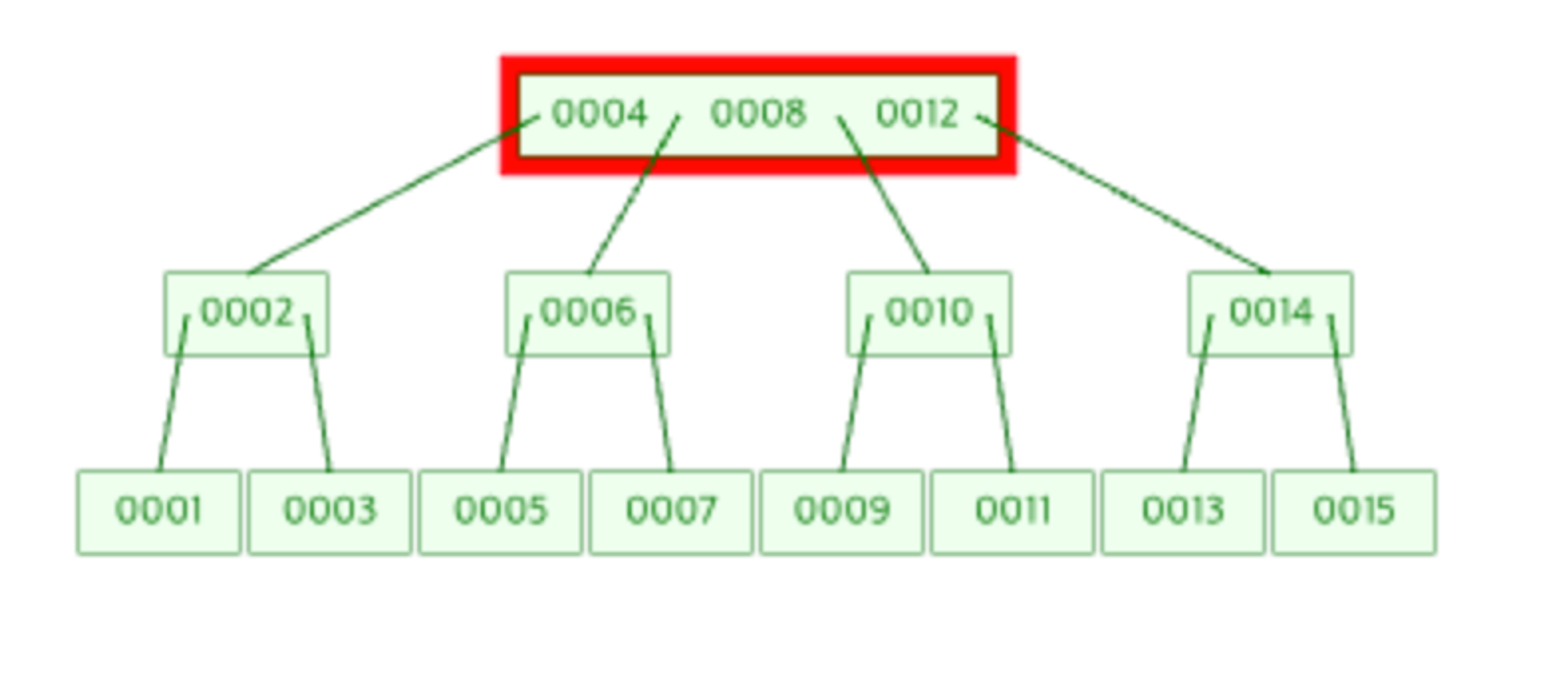
- 또다시 4, 8, 12에서 중간인 8이 승격하여 Root Node가 된다.
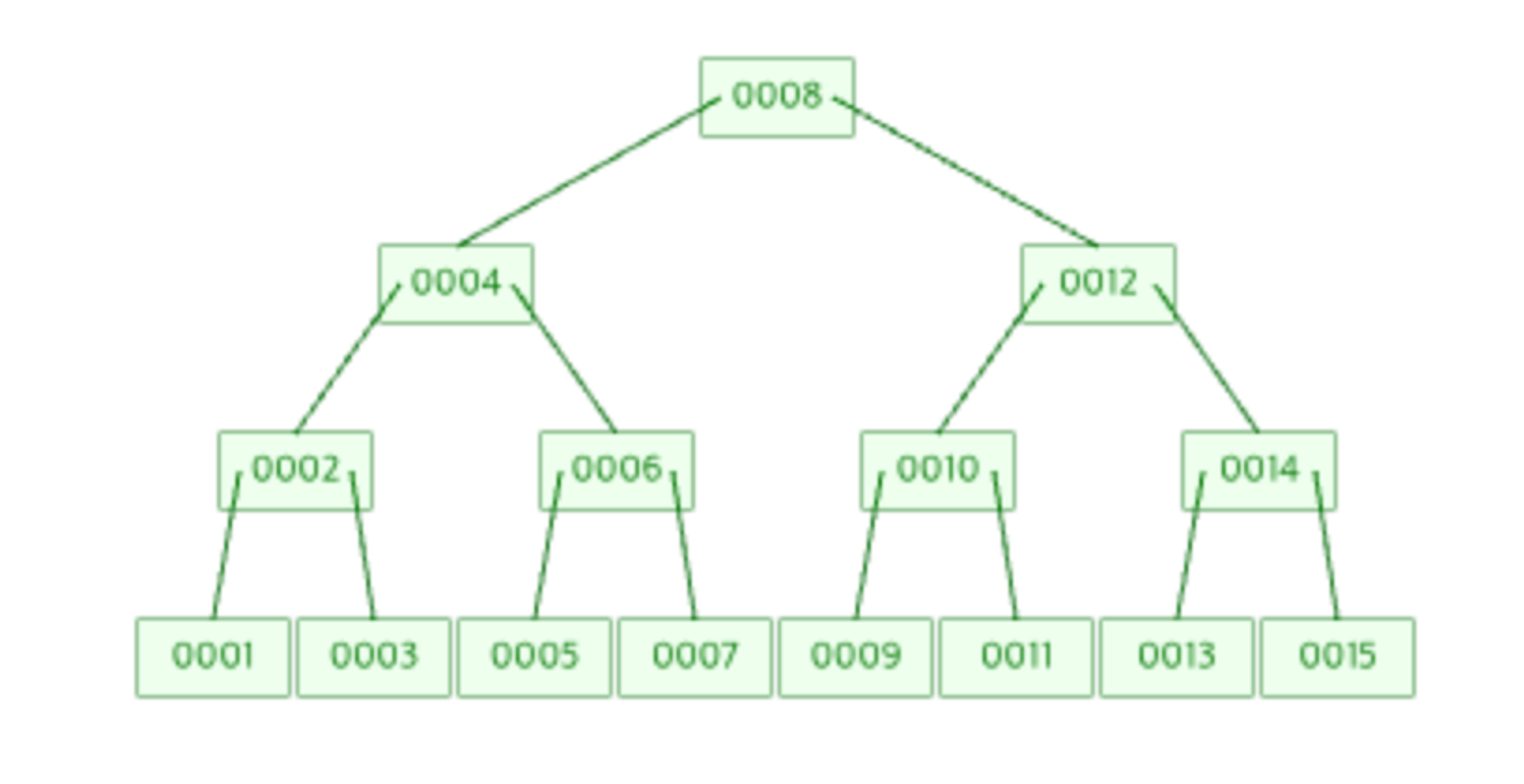
- 위 B-Tree를 체험해볼 수 있는 링크는 아래와 같다.
- 기존 B-Tree가 이렇게 구성이 되어 있을 때, 이제 15 Index를 추가하면 아래와 같이 된다.
Hash 인덱스
- 구조 및 원리
- 해시 테이블 기반: Hash 인덱스는 키를 해시 함수에 입력하여 반환된 해시 값에 따라 데이터의 위치(값)를 저장하는 구조이다. 내부적으로 버켓 또는 슬롯이라고 불리는 배열을 사용하여 해시 값에 해당하는 인덱스에 데이터를 위치시킨다.
- 해시 충돌: 두 개 이상의 키가 동일한 해시 값을 가질 경우, 해시 충돌이 발생한다. 이를 해결하기 위해 연결 리스트나 개방 주소법 같은 기법을 사용할 수 있다.
- 장점
- 빠른 접근 속도: 일반적으로 해시 인덱스는 특정 키 값에 대한 데이터 접근을 상수 시간(O(1)) 내에 수행할 수 있어 매우 빠르다.
- 정확한 일치 검색에 최적화: 해시 인덱스는 키 값의 정확한 일치 검색에 최적화되어 있으며, 이 경우 매우 높은 성능을 보인다.
- 사용 사례
- 메모리 내 데이터베이스: Redis와 같은 메모리 기반 데이터베이스에서 주로 사용된다. 또한, 특정 키 값의 정확한 일치를 찾는 쿼리가 많은 애플리케이션에 적합하다.
3. 성능테스트
customerId(중복된 데이터) + createDate를 인덱스로 한 경우
- Order.java
@Entity @Builder @AllArgsConstructor @NoArgsConstructor @Table(indexes = {@Index(name = "idx_customer_order", columnList = "customerId, createDate DESC")}) public class Order { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(nullable = false) private Long customerId; @Column(nullable = false) private LocalDateTime createDate; }@Table어노테이션은Order엔티티가 데이터베이스 내에서 어떤 테이블과 매핑될 것인지를 지정한다.- 특히
indexes속성을 통해,customerId와createDate컬럼을 기준으로 내림차순 정렬된 인덱스idx_customer_order를 생성하도록 한다. - 이 인덱스는 데이터 조회 시 성능을 향상시키기 위해 사용되며, 특정 고객의 주문을 빠르게 찾거나 최근 주문부터 조회할 때 유용하다.
- OrderRepositoryTest1.java
@SpringBootTest class OrderRepositoryTest { @Autowired private OrderRepository orderRepository; @BeforeAll static void setUp(@Autowired OrderRepository orderRepository) { Random random = new Random(); // 주문 데이터 100만 건 생성 및 저장 for (int i = 0; i < 1000000; i++) { Long customerId = (long) (random.nextInt(100) + 1); // 1부터 100 사이의 고객 ID LocalDateTime createDate = LocalDateTime.now().minusDays(random.nextInt(365 * 2)); // 지난 2년간 랜덤 날짜 orderRepository.save( Order.builder() .customerId(customerId) .createDate(createDate) .build() ); } } @Test void performanceTestWithIndex() { StopWatch stopWatch = new StopWatch(); // 특정 고객의 최근 주문 조회 Long targetCustomerId = 100L; stopWatch.start(); orderRepository.findByCustomerIdOrderByCreateDateDesc(targetCustomerId); stopWatch.stop(); System.out.println("Query time with index: " + stopWatch.getTotalTimeSeconds() + " seconds"); System.out.println(stopWatch.prettyPrint()); } }- 임의로 100만건 데이터를 추가하여 쿼리를 조회해보았다.
- 인덱스가 걸려있지 않은 쿼리 속도
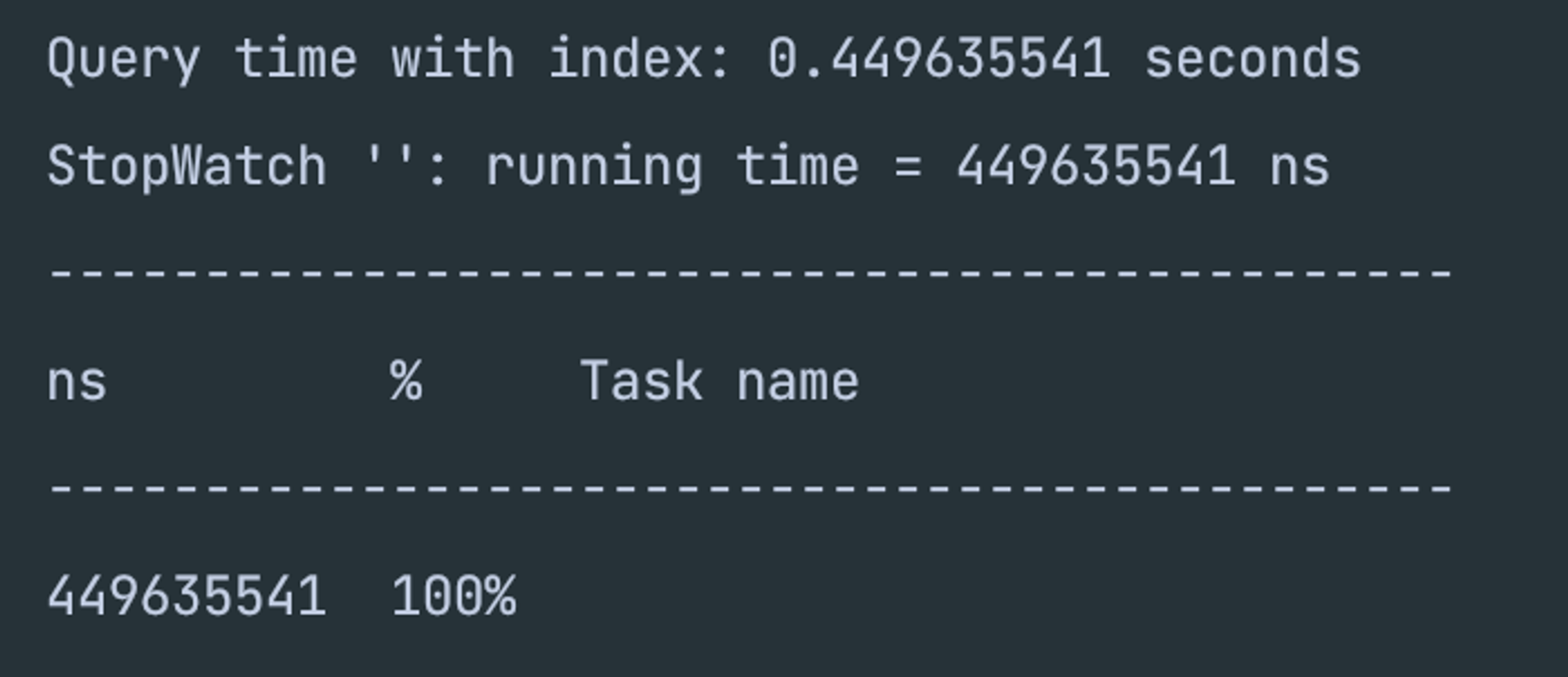
- 0.44ms의 속도를 보여주고 있다.
- 인덱스가 걸려있는 쿼리 속도
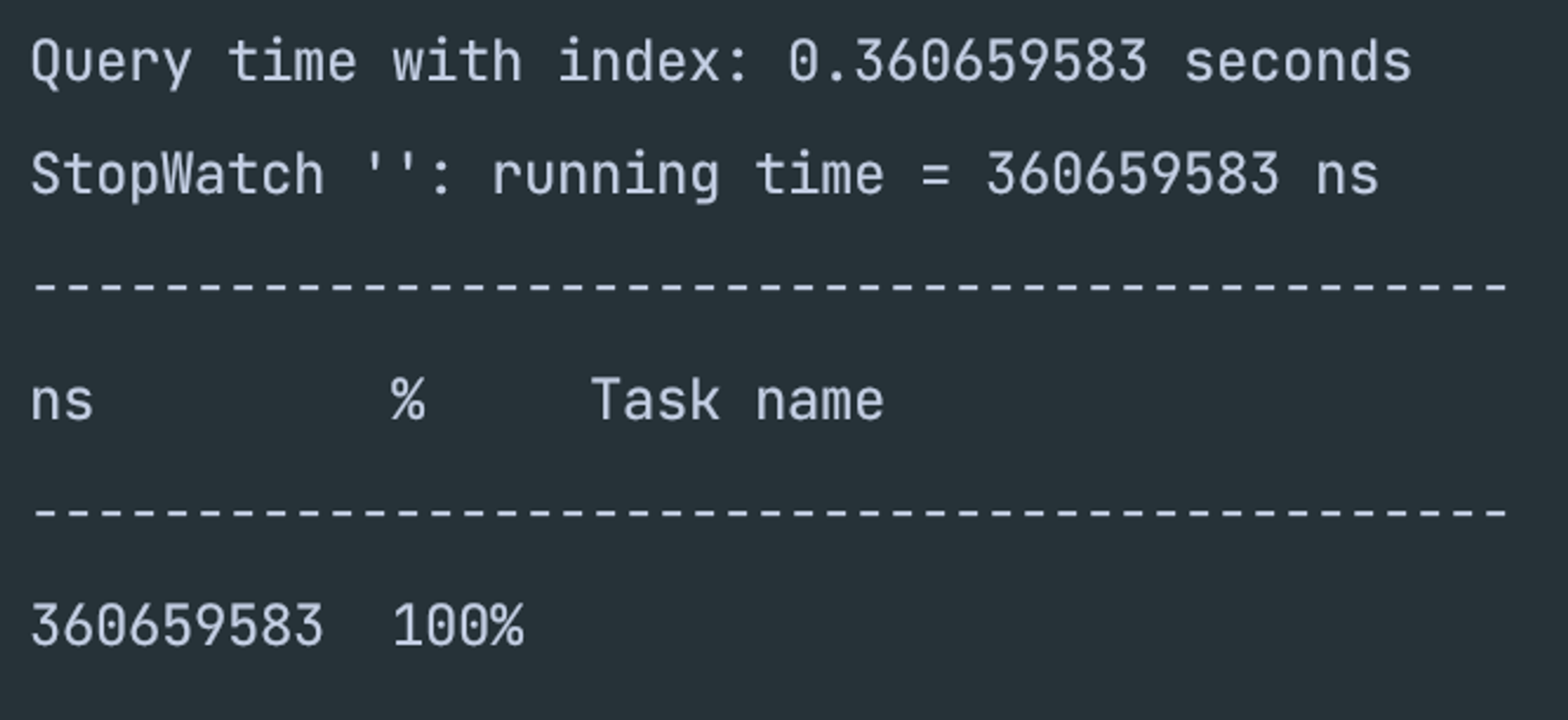
- 0.36ms의 속도를 보여주고 있다.
- 두 속도차이는 그렇게 큰 속도차이는 아니지만 100만건 조회 치고는 나쁘지 않은 성능을 보이고 있다.
- 단, 우리가 간과한 부분이 있다.
- customerId를 1~100 사이에 값을 중복되게 저장하였는데, 이런 경우 인덱스를 통해 데이터를 찾아낼 때 많은 레코드가 조건에 해당하기 때문에 실제로 데이터를 찾는 과정에서의 효율성이 떨어진다.
- 이는 인덱스를 통한 검색 속도의 개선이 덜하게 되며, 결국 전체 데이터를 스캔하는 것과 비슷한 성능을 보일 수 있어 인덱스의 장점을 살리기 어렵게 된다.
- 따라서, customerId를 중복되지 않게 하기 위해 테스트 코드를 수정하였다.
customerId(중복되지 않은 데이터) 인덱스로 한 경우
- Order.java
@Entity @Builder @AllArgsConstructor @NoArgsConstructor @Table(indexes = {@Index(name = "idx_customer_order", columnList = "customerId")}) public class Order { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(nullable = false) private Long customerId; @Column(nullable = false) private LocalDateTime createDate; }- 이번에는 customerId 한개로만 인덱스를 두었고, 밑에 테스트 코드를 보면 알수 있듯이 customerId에 대한 중복을 제거 하였다.
- OrderRepositoryTest2.java
@SpringBootTest class OrderRepositoryTest2 { @Autowired private OrderRepository orderRepository; @BeforeAll static void setUp(@Autowired OrderRepository orderRepository) { Random random = new Random(); // 주문 데이터 10만 건 생성 및 저장 for (int i = 0; i < 100000; i++) { LocalDateTime orderDate = LocalDateTime.now().minusDays(random.nextInt(365 * 2)); // 지난 2년간 랜덤 날짜 orderRepository.save( Order.builder() .customerId((long) (i)) .createDate(orderDate) .build() ); } } @Test void performanceTestWithIndex() { StopWatch stopWatch = new StopWatch(); // 특정 고객의 최근 주문 조회 Long targetCustomerId = 100L; stopWatch.start(); orderRepository.findByCustomerId(targetCustomerId); stopWatch.stop(); System.out.println("Query time with index: " + stopWatch.getTotalTimeSeconds() + " seconds"); System.out.println(stopWatch.prettyPrint()); } }- 이번엔 10만건 데이터를 추가하여 쿼리를 조회해보았다.
- 인덱스가 걸려있지 않은 쿼리 속도
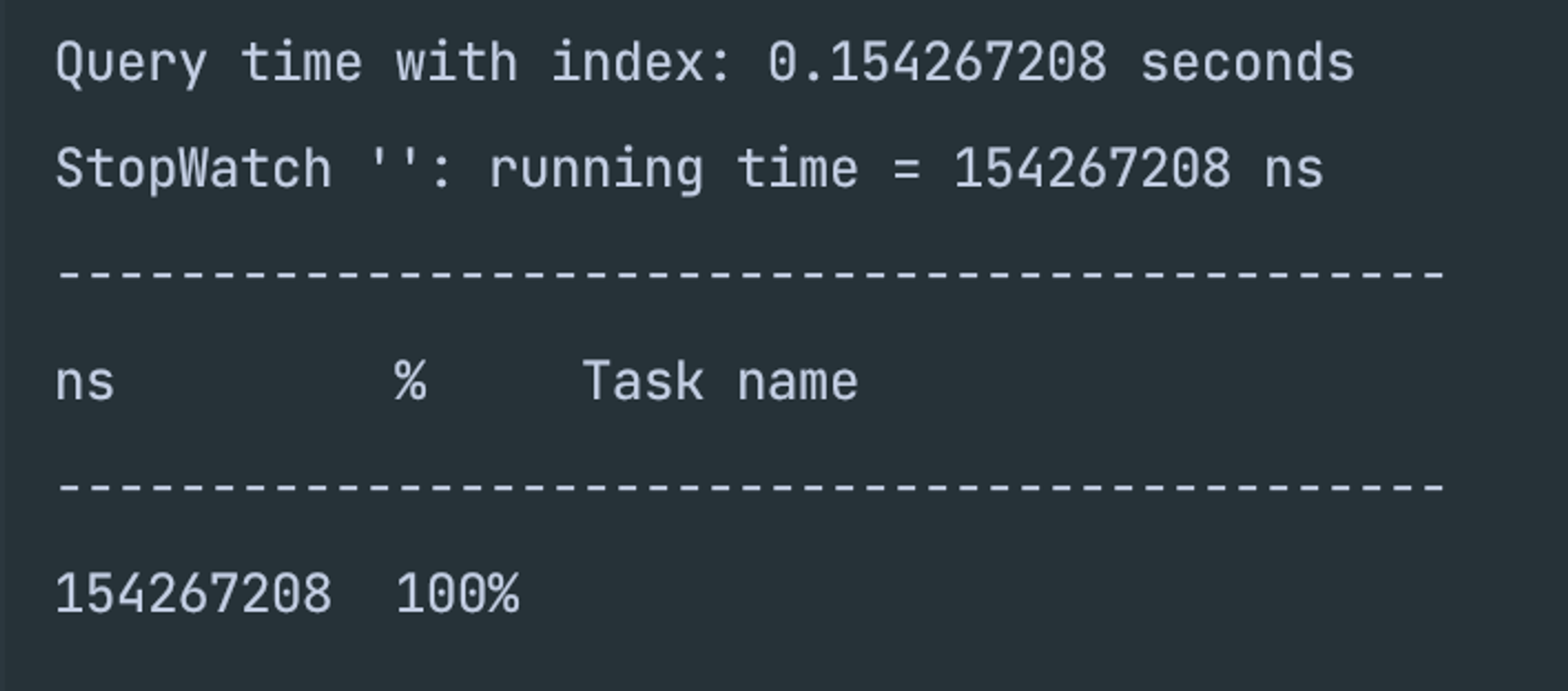
- 0.15ms의 속도를 보여주고 있다.
- 인덱스가 걸려있는 쿼리 속도
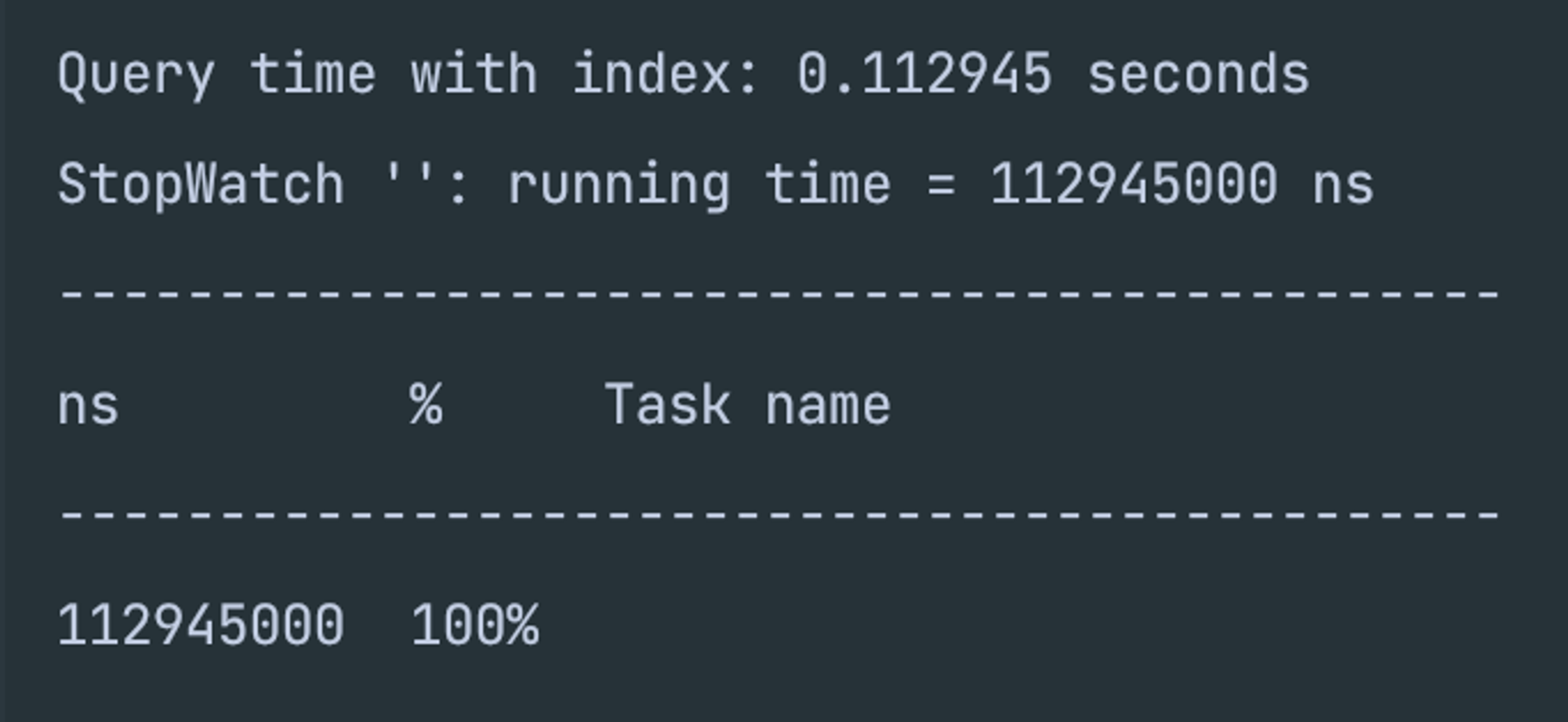
- 0.11ms의 속도를 보여주고 있다.
- 이번엔 아까보다 더 유의미한 결과를 보여주고 있다. 대충 계산해보면 30% 이상의 효율을 보여주는 것 같다.
- 심지어 아까는 100만 Row였고 지금은 10만 Row였는데도 이런 유의미한 차이를 내는걸 보아 데이터가 많아질수록 더 큰 이점을 보일 것으로 예상이든다.
4. 인덱스 동작 원리
인덱스 구조
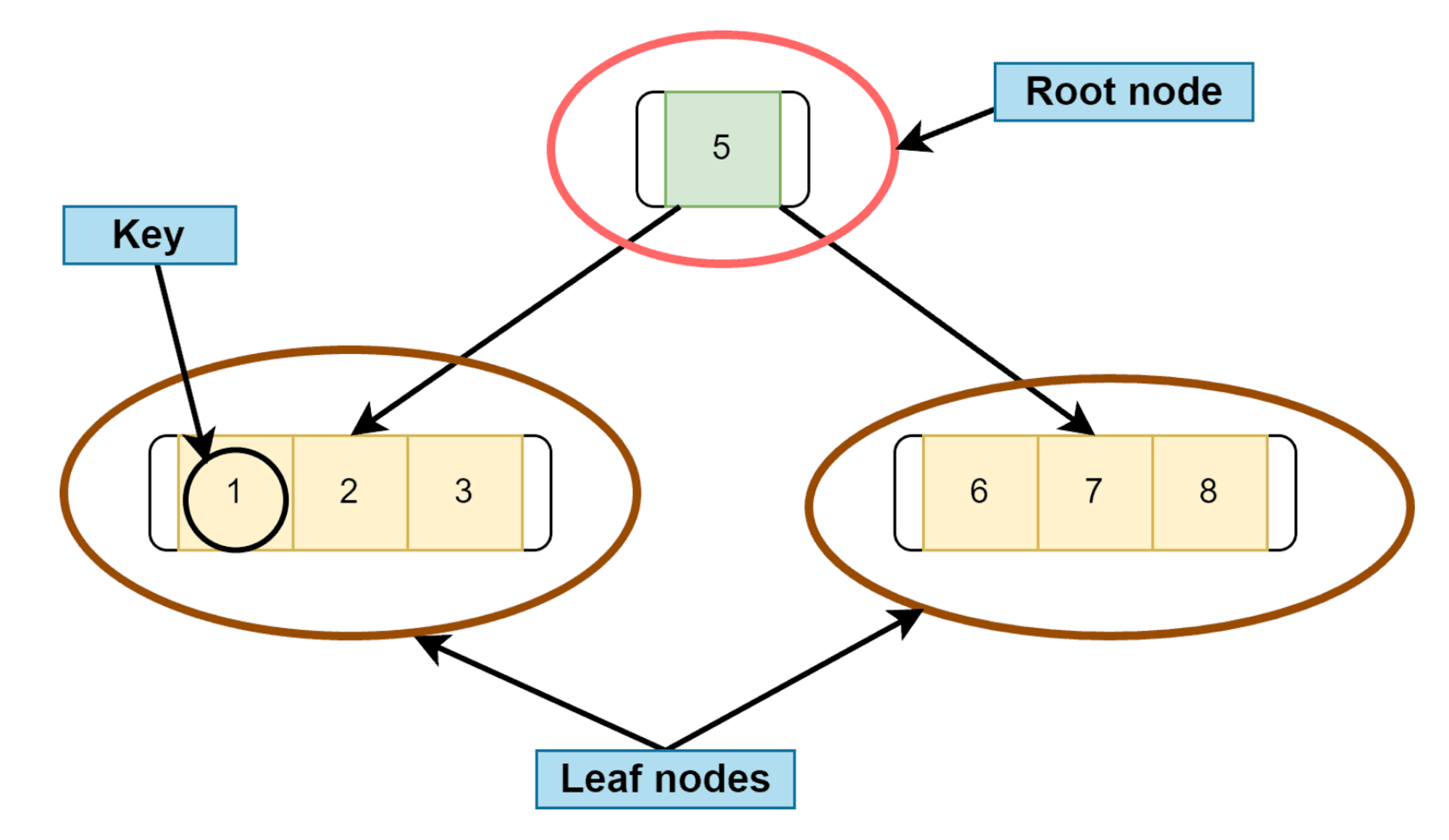
- 노드와 키: 인덱스는 키와 포인터로 구성된 노드들의 집합으로, 키는 데이터를 정렬하고 탐색하는 기준이 되며, 포인터는 실제 데이터 또는 다음 노드를 가리킨다.
- 리프 노드와 내부 노드: B-Tree 인덱스에서 리프 노드는 실제 데이터의 위치를 가리키는 포인터를 포함하고, 내부 노드는 트리의 탐색 경로를 결정하는 데 사용된다.
인덱스를 통한 데이터 검색
- 탐색 과정: 키 값을 기준으로 인덱스를 탐색하는 과정은 루트 노드에서 시작하여, 해당 키 값과 일치하거나 범위에 속하는 리프 노드를 찾을 때까지 계속된다.
- 효율성: 인덱스의 계층적 구조 덕분에 대량의 데이터에서도 로그 시간 복잡도로 검색을 수행할 수 있다.
인덱스 관리
인덱스는 항상 최신의 정렬된 상태를 유지해야 한다. 이를 위해 DBMS는 인덱스에 대한 삽입, 삭제, 갱신 연산 시 추가 작업을 수행해야 하며, 이 과정에서 오버헤드가 발생한다.
- INSERT: 새로운 데이터에 대한 인덱스를 추가한다. 이 과정에서 인덱스 페이지가 꽉 찼을 경우, 페이지 분할이 발생할 수 있다.
- DELETE: 삭제된 데이터의 인덱스를 무효화한다. 실제 데이터는 삭제되지만, 인덱스는 '사용하지 않음'으로 표시될 수 있다.
- UPDATE: 기존 인덱스를 무효화하고 갱신된 데이터에 대한 새로운 인덱스를 추가한다.
인덱스의 장점
- 인덱스는 데이터베이스가 대용량의 데이터 속에서도 필요한 레코드를 정교하게 찾아내는 능력을 갖추게 한다. 인덱스가 있는 컬럼에서 검색이 이루어질 경우, 해당 컬럼에 맞춰 최적화된 검색 경로를 통해 쿼리 수행 시간을 대폭 줄일 수 있다.
- 캐시 메모리는 자주 접근하는 데이터를 빠르게 읽기 위해 사용된다. 인덱스를 사용하면 데이터 접근 패턴이 예측 가능해져 캐시의 효율성이 증대되며, 이는 시스템 부하를 줄이고 전체적인 처리 능력을 개선한다.
인덱스를 사용하는 주요 경우
- Order.java → 인덱스가 없는 엔티티로 밑에 번호에 따른 인덱스를 설정해둘 것 이다.
@Entity @Table(name = "orders") public class Order { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(nullable = false) private Long customerId; @Column(nullable = false) @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") private LocalDateTime createDate; @Column(nullable = false) private Double amount; @Column(nullable = false, length = 20) private String status; }
- 대량의 데이터 검색
- 상황: 데이터베이스에 저장된 데이터의 양이 방대할 때, 특정 조건에 부합하는 데이터를 찾아야 하는 경우가 있다.
- 인덱스:
@Index(name = "idx_customerId", columnList = "customerId") - 쿼리:
SELECT * FROM Order WHERE customerId = :customerId; - 이점: 인덱스는 대량의 데이터 중에서도 필요한 정보를 빠르게 찾아내는 메커니즘을 제공한다. 전체 데이터를 순차적으로 스캔하는 것보다 효율적으로 검색하여 처리 시간과 리소스 사용을 최소화한다.
- 정렬된 데이터 출력
- 상황: 사용자가 요청한 기준에 따라 데이터를 정렬하여 출력해야 할 때이다.
- 인덱스:
@Index(name = "idx_createDate", columnList = "createDate DESC") - 쿼리:
SELECT * FROM Order ORDER BY orderDate DESC; - 이점: 인덱스는 미리 정렬된 상태로 데이터를 관리하기 때문에, 별도의 정렬 과정 없이도 빠르게 정렬된 데이터를 제공할 수 있다.
- 조인 연산 최적화
- 상황: 두 테이블 또는 그 이상을 조인하여 새로운 데이터 세트를 생성할 때이다.
- 인덱스:
@Index(name = "idx_customerId", columnList = "customerId") - 쿼리:
SELECT Order.*, Customer.name FROM Order JOIN Customer ON Order.customerId = Customer.id; - 이점: 인덱스는 조인 연산에 필요한 테이블 간의 매칭 과정을 효율적으로 수행하여, 조인 작업의 속도를 크게 향상시킨다.
- 유니크한 값 검색
- 상황: 중복되지 않는 고유한 데이터 값을 검색해야 할 때이다.
- 인덱스: 주문 ID는
@Id어노테이션을 통해 이미 유니크 인덱스가 자동으로 생성된다. - 쿼리:
SELECT * FROM Order WHERE id = :orderId; - 이점: 인덱스는 유니크 제약 조건이 있는 필드에 대해 효과적으로 작동하여, 중복 없는 값을 신속하게 찾아낼 수 있다.
- 높은 검색 빈도
- 상황: 일부 데이터 또는 필드가 사용자 쿼리에 자주 등장하여, 반복적으로 접근되는 경우이다.
- 인덱스:
@Index(name = "idx_status", columnList = "status") - 쿼리:
SELECT * FROM Order WHERE status = 'pending'; - 이점: 빈번하게 조회되는 필드에 인덱스를 적용하면, 검색 시간을 대폭 단축시킬 수 있다.
인덱스를 사용하면 무조건 성능이 좋아질까? (단점)
- 성능 저하: 인덱스는 삽입(INSERT), 삭제(DELETE), 수정(UPDATE) 같은 데이터 조작 언어(DML) 작업에 취약하다. 데이터가 변경될 때마다 인덱스도 업데이트되어야 하므로, 이로 인한 추가적인 정렬과 저장 작업이 필요하다. 특히, 데이터 수정이 잦은 테이블의 경우 이러한 작업들이 누적되어 시스템에 부담을 줄 수 있다.
- 추가 저장 공간 필요: 인덱스는 추가적인 저장 공간을 요구한다. 일반적으로 데이터베이스의 10% 정도의 공간이 인덱스 관리를 위해 필요하며, 이는 많은 양의 데이터를 처리하는 시스템에서 상당한 저장 공간을 차지할 수 있다.
- 인덱스의 비대화: 데이터가 수정될 때마다 '사용하지 않음'으로 처리되고 인덱스가 삭제되지 않는 경우가 많다. 결과적으로 수정 작업이 많은 시스템에서는 실제 데이터에 비해 인덱스의 크기가 불필요하게 커질 수 있으며, 이는 전체적인 데이터베이스 성능에 부정적인 영향을 미칠 수 있다.

지나가는 개발자