[논문 리뷰]VADOI: VOICE-ACTIVITY-DETECTION OVERLAPPING INFERENCE FOR END-TO-END LONG-FORM SPEECH RECOGNITION
논문 링크 : 링크
안녕하세요, 오늘은 STT, 그 중에서도 ASR에서 쓰이는 추론 방식에 대한 글을 가져와 보았습니다. 이 글에서는 논문에서 제시한 기술에 대해서 알아보고, 해당 기술에 대해서 보다 깊은 이해를 시도해보겠습니다.
목차
1. 논문의 성과 요약(결론)
2. 서론
3. 주요 기술 설명
4. 실험 결과
5. 글을 닫으며
논문 성과 요약
이 파트는 빠르게 내용을 이해하고 넘어가고 싶으신 분들을 위한 파트입니다. 가볍게 이해하고 넘어가고자 하시는 분들이나, 논문에 나온 기술이 필요한지 판단하고 싶으신 분들을 위해 준비했습니다.
문제 제시
End-to-End(E2E) 음성 인식 모델은 장문 발화(long-form speech)에서 성능이 저하되는 문제가 있습니다. 이를 해결하기 위해 오디오를 잘라서 sliding window로 부분적으로 추론하는 중첩 추론(OI)를 도입했지만, 중첩 비율이 높을수록 비용이 올라가는 trade-off가 발생하게 됩니다. 특히, 긴 길이의 오디오을 처리할 때 경계에서 단어 왜곡과 정렬 혼란이 발생하며, 이는 단어 오류율(WER)을 증가시키고 계산 비용을 높이는 원인이 됩니다.
문제 해결 방안
VAD 기반 경계 감지
고정된 길이로 세그먼트를 진행하던 다른 OI 기술과 다르게, VAD를 활용하여 오디오 세그먼트의 경계를 더 정확하게 식별합니다. 이를 통해 단어가 중간에 잘리는 문제를 줄이고, 중첩 영역에서 공통 단어를 늘려 정렬 성능을 향상시킵니다.
소프트 매치(Soft-Match)
유사하지만 동일하지 않은 단어 간의 불일치를 보상합니다. 예를 들어, “hello”와 “helo”와 같이 유사한 단어에 대해 이전에는 보상을 부여받지 못했다면, VADOI는 부분적인 매칭 점수를 부여하여 정렬 혼란을 완화합니다.
비교실험 결과
-
Dataset : Librispeech, Microsoft Speech Language Translation(MSLT)
-
WER : 30%의 중첩 비율에서, 다른 추론 방식이 50%의 중첩 비율을 사용할 때만큼 준수한 성능을 만들어냈습니다.
-
Cost : VADOI는 기존 방법 대비 약 20%의 비용 감소를 달성했습니다.
-
Soft-Match : 소프트 매치 기술을 적용하여 특정 에지 케이스에서 정렬 문제가 완화되었지만, 전반적인 성능 개선은 영향받지 않았습니다.
의의
이 논문에서 제안된 VADOI의 장점은, 특정 환경에서 보여주는 확실한 성능 개선입니다. OI(Overlapping Inferenve) 추론 방식을 사용하는 Speech Recognition에서, 중첩 비율이 50% 이하일 때에도 높은 성능을 보여주기 때문에 학습 속도와 비용을 획기적으로 줄일 수 있습니다. 다만, 중첩 비율이 50% 이상일 때에는 다른 추론 방식과 동일한 성능이 출력되기 때문에, 논문에서 제시한 상황에 정확히 일치할 때에만 유용할 수 있습니다.
이제 글에 대해서 간략하게 알아보았다면, 좀 더 자세히 파고들어 봅시다!
서론
End-to-End(E2E) 모델은 자동 음성 인식(ASR)라는 Task에서 기존의 Hidden Markov Model(HMM)보다 많은 이점을 가지고 있습니다. 성능의 유의미한 향상 뿐만 아니라, 음향 입력 전체를 단일 모델에 매핑함으로써 메모리 사용량의 감소까지 이루어냈거든요. CTC, RNN-T, 그리고 Attention 기반 Encoder-Decoder 모델이 이에 속합니다.
그러나 짧은 길이의 오디오로 학습된 E2E로 학습된 모델들은 도메인 불일치로 인해 장문(long-form)의 음성을 디코딩할 때 상당히 낮은 성능을 보여줍니다. 유일한 해결책은 장문의 음성 데이터셋을 만들어 학습시키는 것인데, 이는 오랜 시간과 비용이 소모되며, 학습 시의 GPU 메모리 제한도 고려해야 하기 때문에 매우 비현실적입니다.
따라서, 연구자들은 기존의 short-form 데이터로 학습된 모델을 활용하기 위한 방법을 모색하게 됩니다. Training 단계에서는 long-form 상황을 시뮬레이션하기 위한 랜덤 샘플링과 Relative Positional Encoding과 같은 기술이 유의미한 효과를 주었습니다.
추론 단계에서도 오디오를 짧은 단위로 중첩되도록 분할하여 디코딩한 후 이어붙이는 중첩 추론(Overlapping Inference) 기술이 제안되었습니다. 그러나, 비중첩 영역에서는 제대로된 추론이 되지 않았기 때문에, 높은 cost를 소모하며 높은 중첩 비율을 유지해야 했고, 중첩 비율을 완화하기 위한 부분 중첩 추론(partial overlapping inference)이 고안되었으나 여전히 낮은 중첩 비율에서는 기술 도입이 불가능할 정도의 성능을 보여줍니다.
이전까지의 연구들은 중첩 비율이 높을수록 성능이 올라가지만 비용도 올라가는 trade-off를 보여줍니다. 이에 논문의 저자들은 낮은 중첩 비율을 유지하면서 성능을 높이기 위한 VADOI를 제시합니다. 결론부터 이야기하자면, 실험 결과 30%의 중첩 비율로 기존 모델의 50% 중첩 비율과 같은 성능을 유지하여 20%의 비용 감소 효과를 이루어냅니다.
주요 기술 설명
VADOI
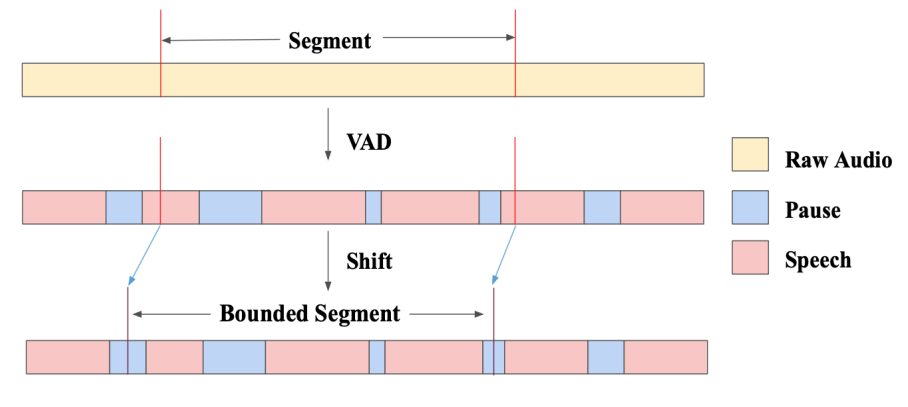
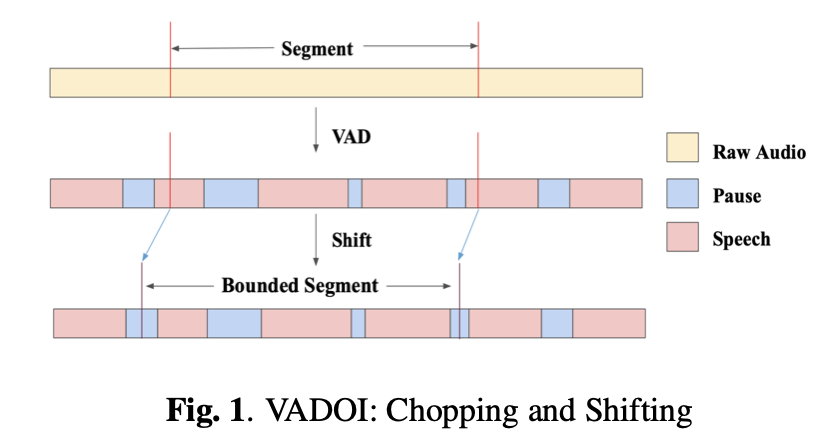
기존의 모델들의 WER 저하의 원인을 분석해본 결과, 세그먼트 간 공유 단어의 부족이 주 원인이었습니다. 분리된 세그먼트의 정렬은 각 세그먼트끼리의 공통 단어를 통한 충분한 매칭 보상이 있을 때에 잘 작동하기 때문에, 중첩 비율이 클 때에만 이 조건이 성립했던 것이죠. 즉, 고정된 길이의 세그먼트 분할 시에 단어가 중간에 잘려서 다르게 인식되는 것이 치명적인 문제로 작용하고 있던 상태였습니다.
VADOI는 이를 방지하기 위해서 1번째로 고정된 길이와 중첩 비율로 세그먼트를 생성한 후, 각 세그먼트에 VAD를 적용합니다. 시작 프레임과 종료 프레임은 각각 VAD로 우리가 원하는 길이로 조정되는데, 이 때 중첩된 부분이 사라지는 것을 방지하기 위해 중첩된 부분의 절반 이하만 조정이 가능하도록 제한해둡니다. 따라서 만약 적절하게 자를(즉 단어가 완결되는) 구간을 찾지 못하면, 각 프레임은 중첩된 부분의 절반만 보존하게 됩니다. 중첩 비율이 40% 이상이라면, 각 세그먼트는 항상 최소 3개의 단어쌍이 중첩되어 보존됩니다. 프레임 단위의 VAD의 비용은 무시할 정도로 낮습니다.
예를 들어서 0~10초와 6~16초가 프레임이라면, 최대 길이로 자른다고 해도 0~8초와 8~16초가 결합되어 손실 없이 완전한 문장이 추론됩니다.
Soft Match
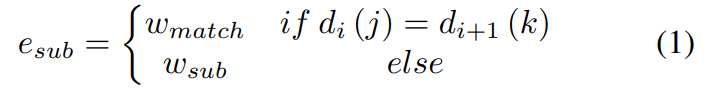
기존에는 정렬(Alignment) 단계에서 연속적인 세그먼트의 공통 단어를 기반으로 매칭 보상을 계산합니다. 그러나 동일한 단어가 다르게 인식될 경우 정렬의 성능이 크게 저하됩니다. 이를 방지하기 위해 Soft Match가 제안되었습니다.
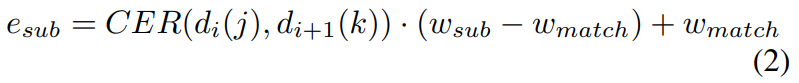
Soft Match는 유사하지만 동일하지 않은 단어 간의 불일치에도 reward를 줍니다. 예를 들어 Hello와 Helo는 다르지만 유사하기 때문에 matching reward를 일부분 받습니다. 이를 구현하기 위해서 고정 대체 비용과 매칭 보상 부분을 수정하여 두 단어 간의 유사도가 임계치보다 높을 경우 보상이 부여되게끔, 유사도 점수를 적용한 가중치를 부여합니다. 이는 전반적인 성능의 향상보다는 특정 엣지 케이스를 해결하기 위해 제안되었습니다.
실험 결과
Dataset
Librispeech : 영어 Audio-Text 데이터 셋
MSLT : 다양한 언어로 된 장문(Long-form) 음성 데이터셋
모델은 Transformer 기반의 ASR 모델을 사용하였으며, OI와 POI, VADOI 3개에 대해서 WER과 Cost를 비교합니다.

먼저 Overview입니다. OI와 POI를 비교해놓은 것입니다.
WER(혹은 CER) / 디코딩 시간 / OI 시간 을 순서대로 나열했는데, OI시간에서 매우 큰 차이가 보이네요! 또한 POI가 50% 중첩 비율에서 WER과 CER에 거의 차이를 보이지 않는 점이 인상 깊습니다.
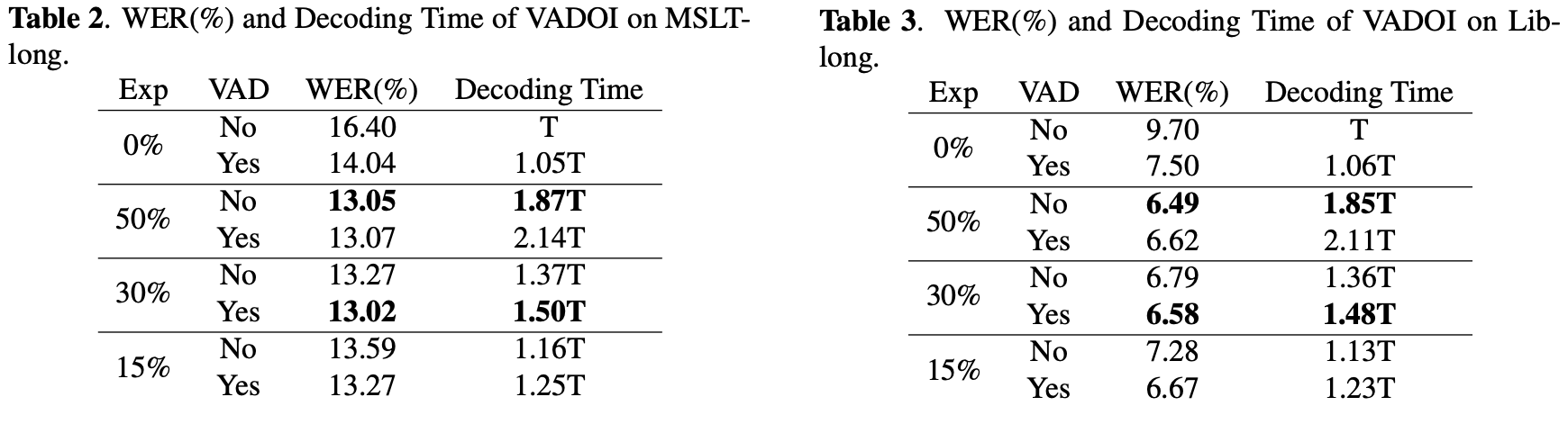
그들이 보여주고자 한 VADOI의 도입 결과입니다. 50%에서는 오히려 VADOI를 도입했을 때 성능이 떨어지는 모습을 보여주네요. 다만 30%에서 오히려 50%보다도 높은 성능을 내는 것으로 보아, 데이터셋 별로 적절한 중첩 비율이 있고 그걸 튜닝해야 할듯합니다.

저자들이 그렇게 강조한대로, Soft Match는 큰 개선을 보이지는 않았습니다. 다만 STT의 성능이 낮아질수록, Alignment에 필요한 중첩 단어들이 불일치할 확률이 높아지기 때문에 더 효과가 좋을듯하네요.
글을 닫으며
이번 글에서는 OI라는 추론 방식 중 하나인 VADOI에 대해서 알아보았습니다. VADOI는 ASR에서 장문의 음성을 처리하는 성능을 높이기 위해 도입할 수 있는 추론 방식으로, 중첩 비율이 낮은 특정 환경에서 높은 개선 효과를 보여줍니다. 특히, 낮은 비용으로도 준수한 성능을 도출할 수 있는 장점이 있습니다. 그러나 이미 높은 중첩 비율과 비용을 사용 중이라면, 이 기술은 사용할 수 없습니다. 최근 STT를 활용한 회의 기록 관련 서비스가 많이 개발되고 있는데, 이 기술을 간단하게 도입하여 더 낮은 비용과 빠른 속도로 모델을 학습시킬 수 있으시다면 좋겠네요.
