[논문 리뷰] Dolphin: A Large-Scale Automatic Speech Recognition Model for EasternLanguages
오늘은 Dolphin이라는 ASR 모델에 대해서 알아보겠습니다.
Dolphin은 한마디로, 오픈소스인 whisper가 서양권 언어에서만 높은 성능을 보이는 점에 착안하여 동양권 언어에서도 준수한 성능을 보여주게끔 발전시킨 모델입니다.
짧은 요약
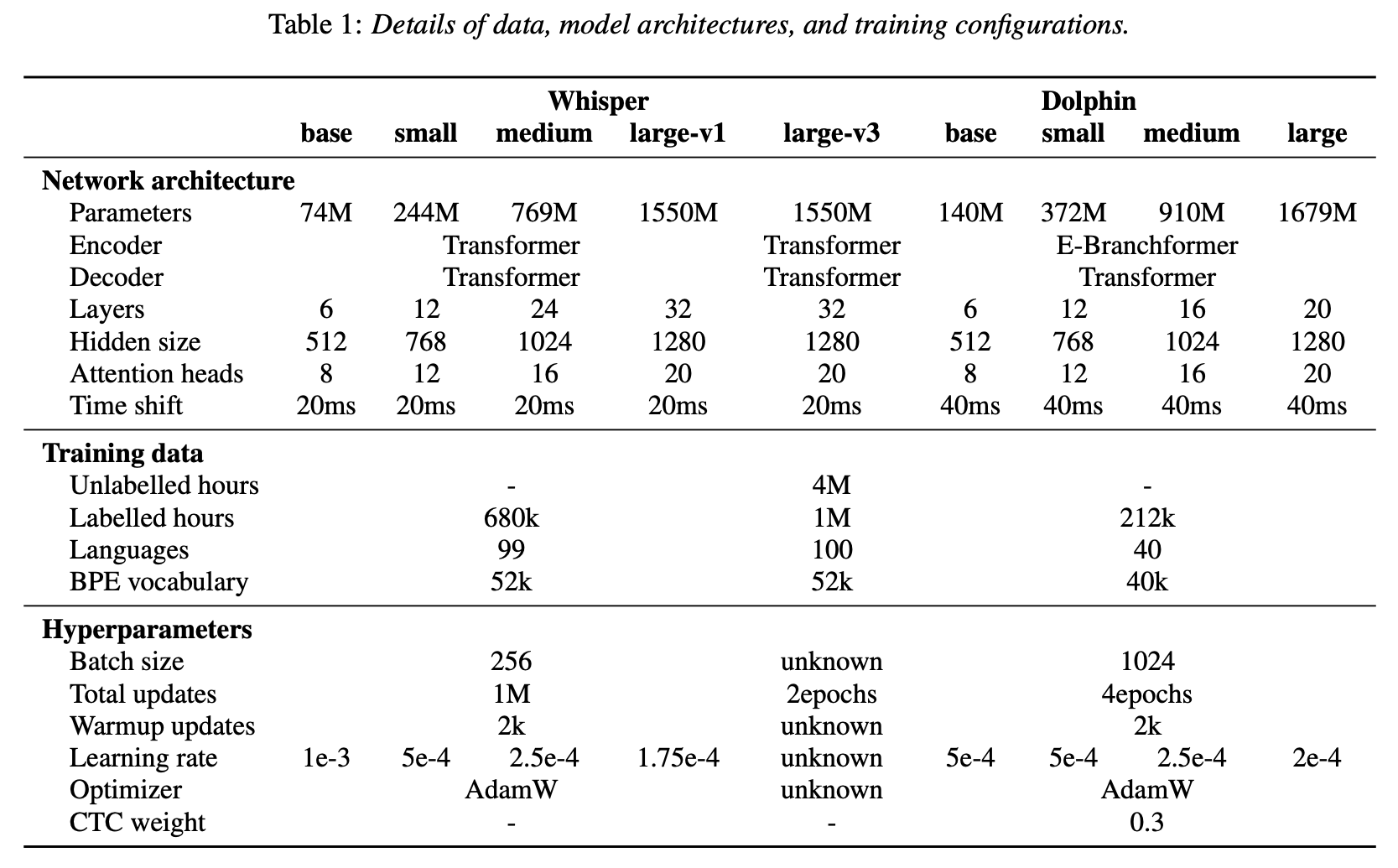
논문에서 Whsiper와 비교하여 보기 좋은 표를 제공해주네요.
Encoder 모델의 변경과, CTC-어텐션 결합 아키텍처, 그리고 다단계 언어 토큰 시스템을 통한 방언 임베딩이 주목할만한 기술이라고 볼 수 있겠습니다.
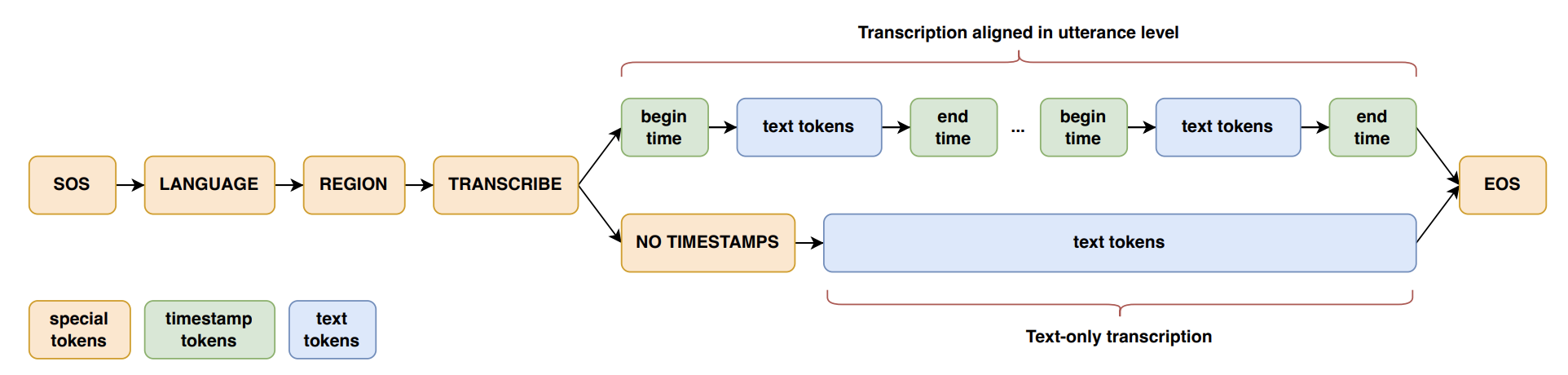
문제 제시
dolphin에서는 Whisper가 다국어 음성 인식에서 뛰어난 성능을 보이지만, 높은 정확도를 보이는 서양권 언어에 비해서 동양권 언어에 대한 성능은 낮다는 점에 주목했습니다. 논문 저자가 중국인이기에 방언이 많은 중국어에서 이러한 점이 더 부각되었을 거 같네요.
도입 기술
1. E-branchformer Encoder
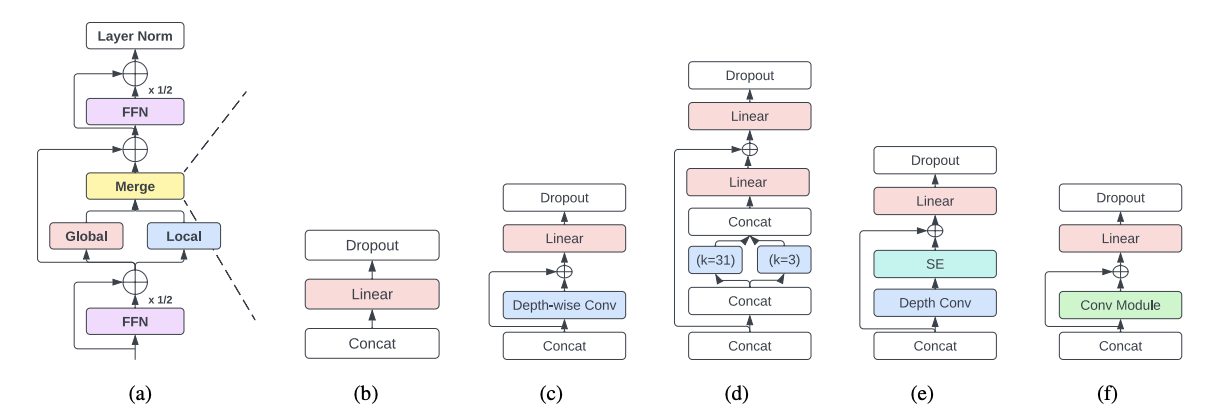
“OWSM v3.1: Better and faster open whisper-style speech models based on e-branchformer.” 라는 이름의 논문을 참고하여, decoder는 기존의 Transformer를 유지한 채로 Encoder만 E-branchformer로 변경하였습니다.
E-branchformer는 짧게 설명드리자면, self-attention을 통해 전체(global) 의존성만을 학습하는 기존의 Transformer와 다르게, Parallel branch structure라는 구조를 도입하여 지역(local) 의존성과 전체(global) 의존성을 동시에 학습하여 병렬 처리 후 merge합니다. 이 방법을 통해 짧은 기간에 대해서 더 세부적인 의존 관계를 포착할 수 있습니다.
2. joint CTC-Attention Architecture
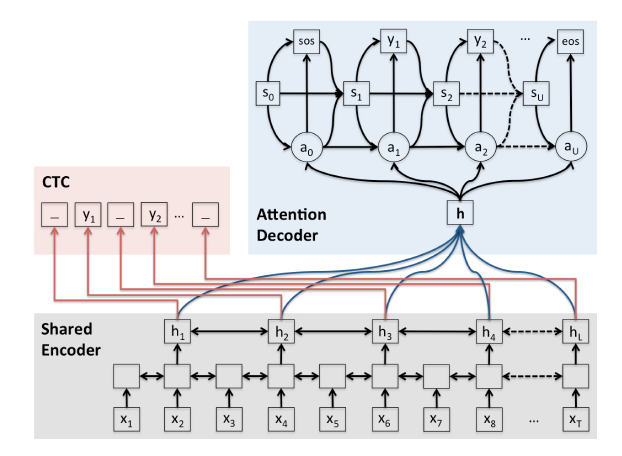
빠르고 효율적이지만 맥락 포착에 한계가 있는 CTC(Connectionist Temporal Classification) 방식과 전체 맥락을 파악하는 Attention을 결합한 구조입니다. 주로 멀티태스크 학습을 위해서 사용하며, Dolphin에서는 다양한 억양과 방언을 인지하기 위해서 도입한 것 같네요.
3. 다단계 언어 토큰 시스템
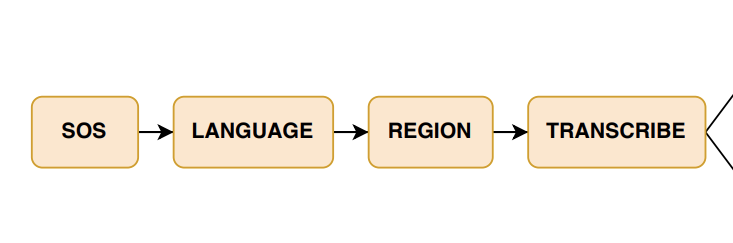
그저 나라(country)만을 인식하는 토큰에서, 지역을 인식하는 토큰을 추가한 2단계 언어 토큰 시스템을 도입했습니다.
예를 들어서, 한국의 경우라면 사투리를 읽었을 때 [서울]-[전라도] 토큰을, 중국의 경우는 [중국]-[사천] 같은 방법으로 방언을 인식합니다.
이에 따라서 50개 이상의 방언이 존재하는 중국어에서 눈에 띄는 성능 향상을 보였습니다.
4. 4배 다운샘플링 layer
논문에서는 "4배 다운샘플링 층을 썼다."라고만 나와있기에 개인적인 추측으로 내용을 작성하였습니다.
Convolution이나 Max pooling 같은 방법을 통해서 입력 시퀀스를 압축했을 것입니다. whisper의 구조를 가져왔다고 했으니 wav파일로 저장된 음성을 멜 스펙트로그램으로 변환한 후에 학습할 것이므로,
[ wav -> mel spectogram -> down sampled spectrogram ]
형태로 전처리를 진행하고 모델에 입력했겠죠?
5. 수작업으로 정제된 데이터셋
데이터셋을 수작업으로 2차 정제하여 더 적지만 더 정확한 데이터셋을 학습에 사용하였습니다. 또한, 길이가 짧은 음성을 결합하여 약 30초 길이의 long-form 데이터도 생성하여 추가하였습니다.
6. 간소화된 ASR
기존 Whisper의 멀티태스크 구조를 사용하되 언어 번역과 같은 기능을 제거하여 모델을 간소화하였습니다.
결과
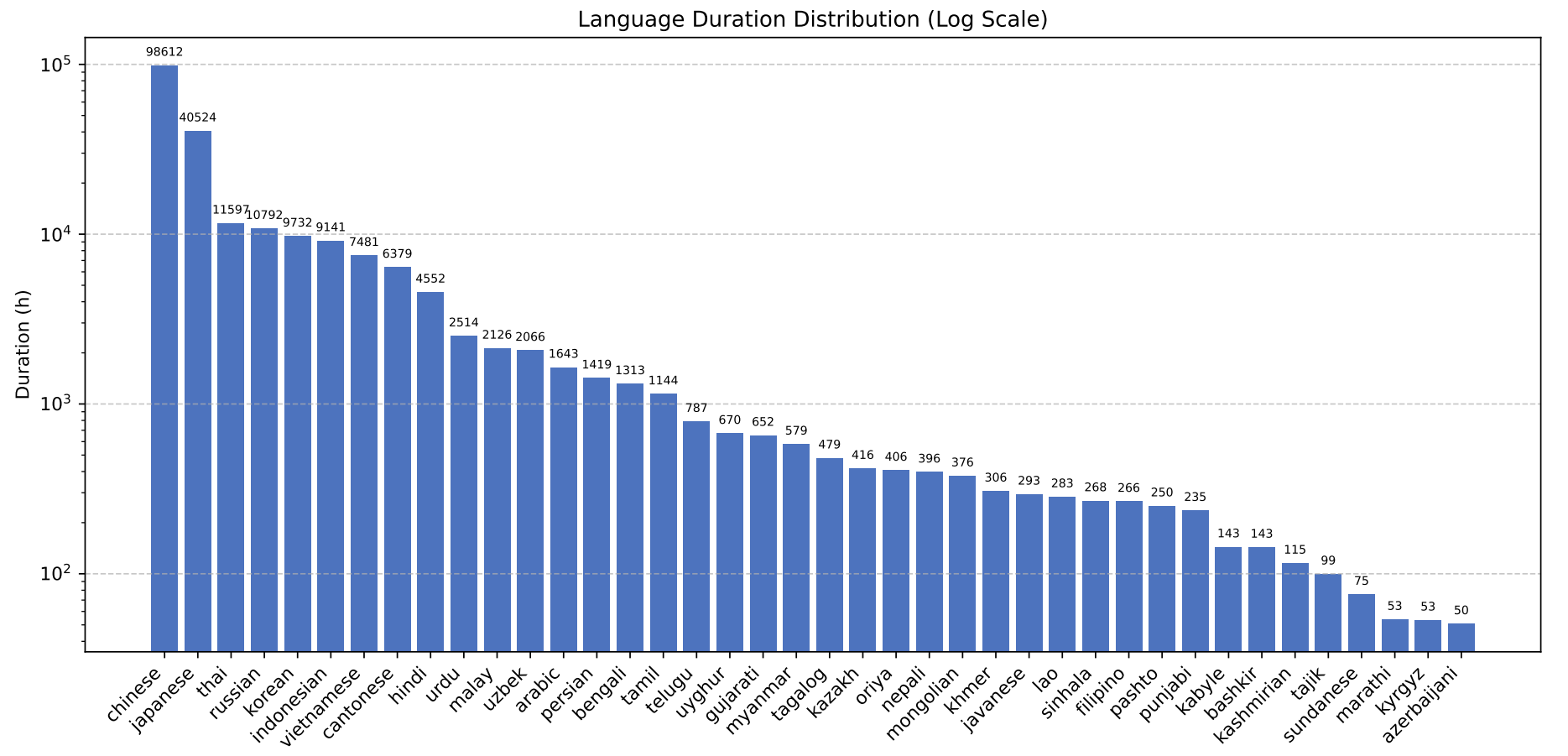
학습에 사용한 오디오의 양입니다. 중국어 약 10만 시간, 일본어 약 4만 시간, 그리고 나머지 언어는 약 1만 시간 혹은 그 이하로 학습하였네요.
실험의 제원입니다.(해보실게 아니라면 무시하고 넘어가셔도 됩니다)
80채널 Log Mel-Scale Filter Bank Energies를 사용하였고,
frame length 25Ms, frame shift 10ms를 사용하였습니다.
증강 및 정규화는 SpecAugment와 글로벌 정규화를 적용하였습니다.
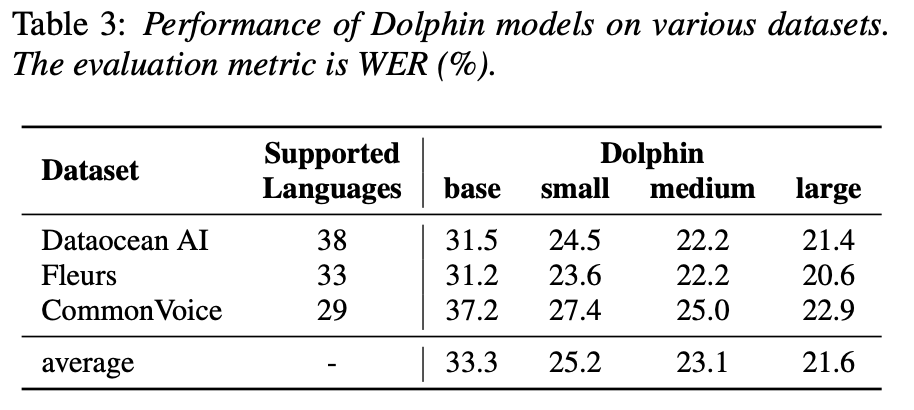
Dolphin 모델을 사용하여 학습과 연관 없는 데이터셋에 대해서 테스트한 결과입니다.
"WER가 21.6%면 5개 중 1개는 틀린다는 거 아니야? 안 좋은거 같은데..."
라고 생각하실 여러분을 위해 준비했습니다. 아래는 whisper가 여러 언어에 대해서 보여주는 WER의 통계입니다.
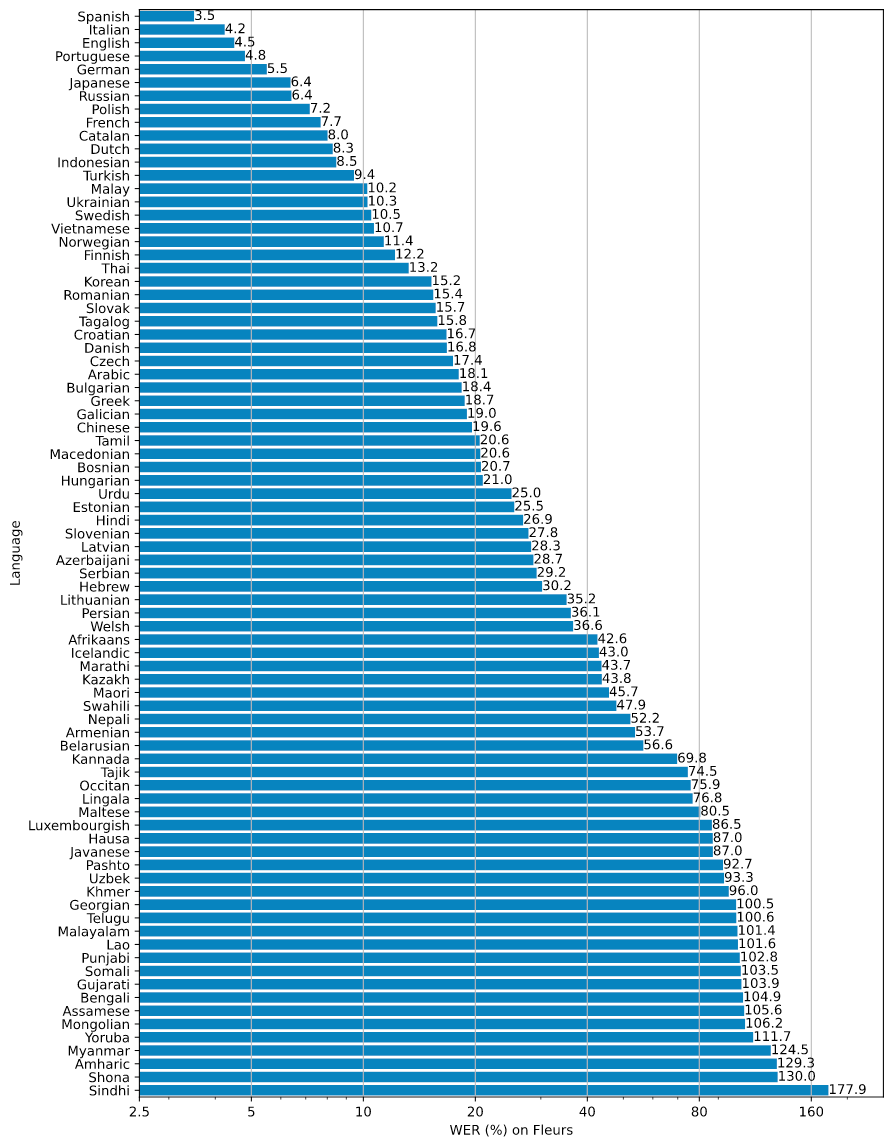
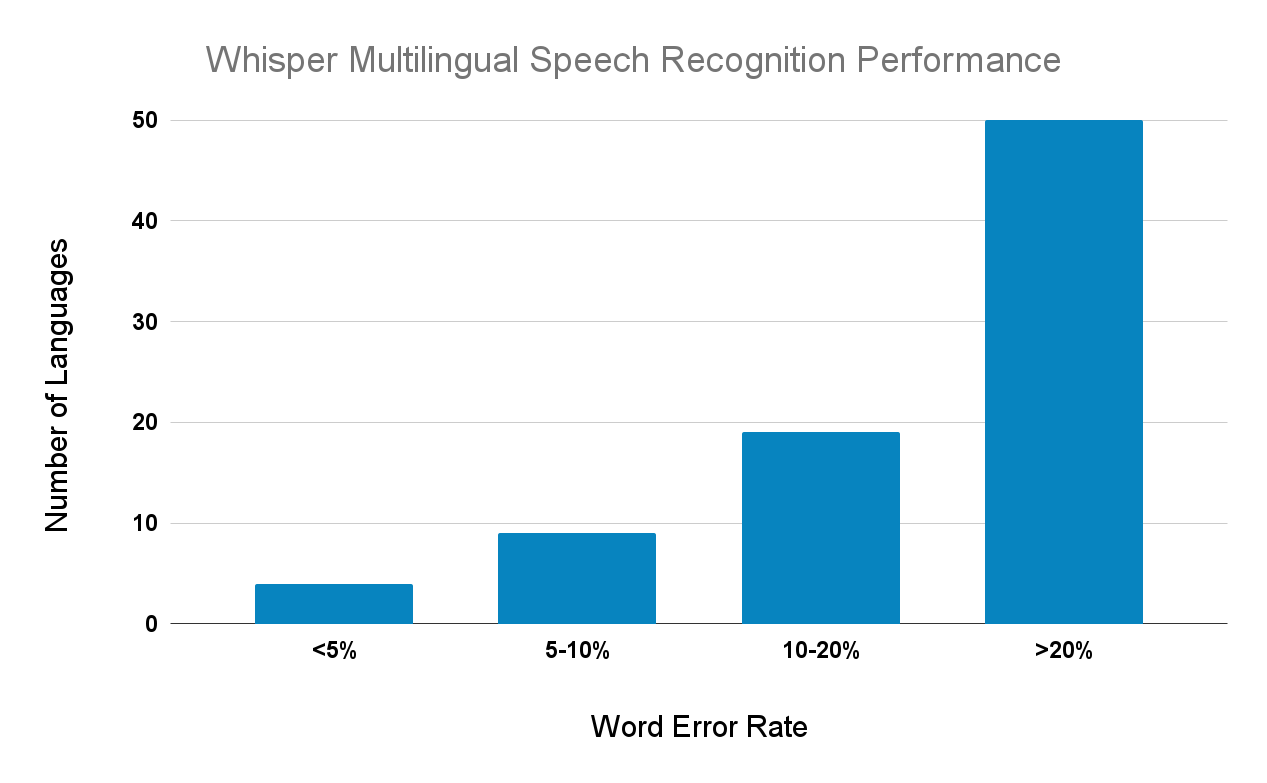
영어나 한국어, 독일어, 이탈리아어 등에서는 높은 성능을 보여주지만, 약 15개의 언어를 제외하면 대부분 15%가 넘습니다. 그에 반해, dolphin은 약 30개의 언어에 대한 평균 WER이 21.6%인 것이니, 중국어를 포함한 여러 아시아권 언어에서는 Dolphin이 Whisper에 비해 압도적인 성능을 보여준다고 할 수 있겠네요!
결론
Dolphin 모델은 동양권 언어에 대한 성능을 서양권 언어와 유사한 수준으로 향상시켰다는 점에서 큰 의의를 갖습니다. Whisper와 같은 기존 모델들이 서양권 언어에서는 낮은 WER(단어 오류율)를 보여주었지만, 동양권 언어와 방언에서는 여전히 성능 격차가 존재했음을 감안할 때, Dolphin은 이러한 한계를 효과적으로 극복했습니다.
다만, Dolphin 모델은 영어, 한국어와 같은 서양권 및 일부 고성능 언어에서는 Whisper 대비 큰 이점이 없는 점도 주목할 필요가 있습니다. 예를 들어, Whisper는 이미 이러한 언어들에서 5% 미만의 WER로 우수한 성능을 보여주고 있기 때문에, 추가적인 성능 향상이 필요한 상황이 아닙니다. 따라서 Dolphin은 특히 동양권 언어와 저자원 언어에서 강력한 도구로 자리 잡을 가능성이 높습니다.
결론적으로, Dolphin은 글로벌 다국어 음성 인식 기술을 언어적 다양성을 존중하는 방향으로 발전시켰으며, 특히 방언 인식 및 언어적 격차를 줄이는 데 중요한 기여를 했습니다. 앞으로 Dolphin은 저자원 언어 및 실시간 성능 최적화를 통해 더 넓은 언어 범위와 실제 환경에 적용될 가능성이 기대됩니다.
