NumPy
-
NumPy는 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리 할 수 있도록 지원하는 파이썬의 라이브러리이다.
-
다차원배열을 효과적으로 다루기 위해 ndarray(N-Dimesional Array) 사용
-
ndarray는 Tensorflow Tensor와 pandas DataFrame의 기반
-
설치 및 사용
pip install numpy : 설치
import numpy as np : import numpy로도 가능하지만
코드에서 좀 더 편하게 사용하기 위해 np로 사용하는 것이 좋다.1. numpy 차원
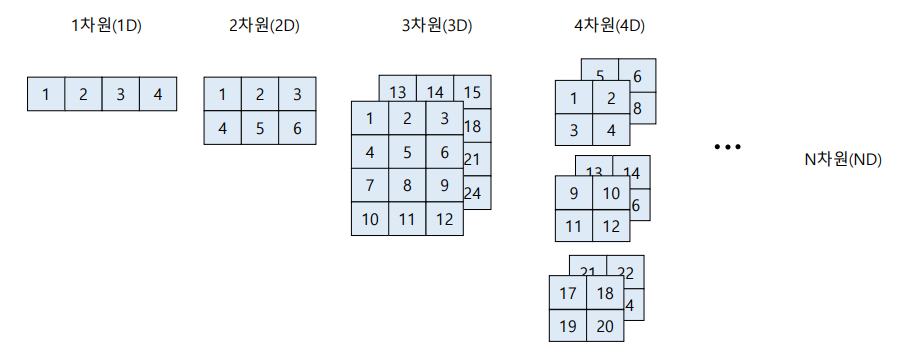
-
1차원은 단독주택이라고 생각하면 된다. flatten 이미지
-
2차원은 하나의 아파트. 흑백이미지 1개
-
3차원은 아파트 여러 동(1동, 2동,,,). 컬러이미지 1개, 흑백이미지 여러개
-
4차원은 아파트 단지(1단지, 2단지, 3단지). 컬러이미지 여러개
2. numpy ndarray사용
- numpy에서는 기본적으로 array 단위(ndarray)로 데이터를 관리하고 연산을 수행한다. 행렬이라는 개념으로 생각하면 된다.
a1 = np.array([1,2,3]) # 1차원 행렬 만들기
-> [1,2,3]
a2 = np.array([[1,2,3], [4,5,6]]) # 2차원 행렬 만들기
-> [[1, 2, 3],
[4, 5, 6]]
a3 = np.array([[[1,2],[3,4]],[[5,6],[7,8]]]) # 3차원 행렬 만들기
-> ([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])대괄호의 개수로 차원을 판단([[ 2개면 2차원, [[[[ 4개면 4차원)
- ndarray 객체 정보 확인
1. a3.ndim # a3의 차원 확인
-> 3
2. a3.shape # a3의 모양(shape) 확인
-> (2, 2, 2) # (채널, 가로(행), 세로(열)) 또는 (가로(행), 세로(열), 채널)
3. a3.size # a3의 크기 확인
-> 8 # size는 shape안의 수를 다 곱한 수 ex) (2, 2, 2) 2*2*2=8
4. a3.dtype # a3의 자료형 확인
-> dtype('int32')- np.arange, np.reshape
ar = np.arange(6) # 파이썬의 for range와 유사 ex) arange(6)면 0 부터 6까지의 숫자를 배열로 만듦
-> array([0, 1, 2, 3, 4, 5])
ar2 = np.arange(1,10,2) # arange(시작 숫자, 끝 숫자, 스텝)
-> array([1, 3, 5, 7, 9])
ar3 = np.arange(6).reshape(2,3) # reshape는 차원을 바꿔준다. 1차원인걸 2차원으로 변경
# 단, 전체 사이즈 수(element수)가 동일해야한다 ex) 6과 2*3=6이 같아야한다.
-> array([[0, 1, 2],
[3, 4, 5]])- np.zeros, np.ones, np.full
# 0으로 채움
1. np.zeros(2) # 1차원
-> [0. 0.]
2. np.zeros((2,3)) # 2차원
-> [[0. 0. 0.]
[0. 0. 0.]]
3. np.zeros([2,2,3]) # 3차원
-> [[[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]]
# 1로 채움
np.ones([2,2,3]) # zeros와 마찬가지로 1로 채움
-> [[[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]]]
# 3. np.full(shape, 채울값)
# shape를 지정하고 전체값을 '채울값'으로 지정
np.full((2,3),100)
-> array([[100, 100, 100],
[100, 100, 100]])행렬의 곱셈
-
element-wise 연산(같은 위치의 값 끼리 연산)
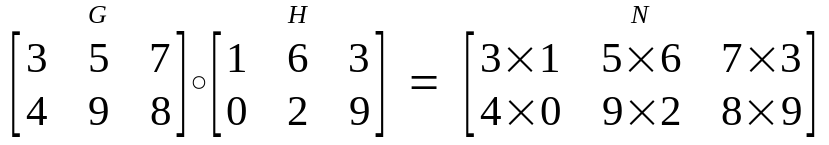
-
행렬 곱셈(matrix multiplication)
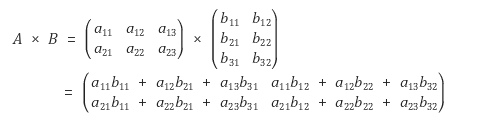
(A 행렬의 열의 개수) = (B 행렬의 행의 개수) 일 때만 곱셈 가능
A 행렬의 i행 성분과 B 행렬의 j열 성분을 차례대로 곱하여 더한 값이 (i,j)성분
Broadcasting
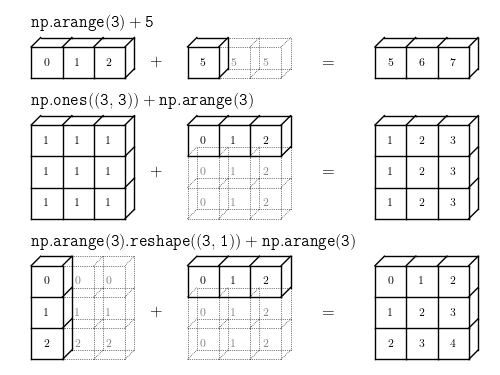
행렬의 모양(shape)이 다른경우 shape를 맞춘 후 연산
연산이 가능한 형태로 자동 reshape한 후, 반복된 값으로 자동 할당하여 연산을 수행
프로젝트
- 프로젝트 시 기획의도, 목적을 명확하게 정하는 것이 중요!
- 발표할 때 평상시 톤으로 발표하기!, 톤을 높이면 긴장하는 것이 티가 날 수 있음(평소 톤으로 긴장하지 않고 발표하는 연습하기)
** 참고
