한줄요약 : 더욱 Discriminative 하기 위해 아래와 같이 하겠다.
수식은 아래와 같다.
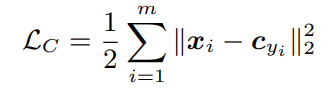
m = mini_batch, c_yi = y_i번째 class의 center, x_i = i번째 feature
mini-batch 내에서 center를 정한 다음, class에 속하는 sample 들을 class center와 가깝게 위치하도록 loss로 잡아줌. (이때 feature가 바뀌게 된다면 center도 새롭게 업데이트 됨.)
원래는 모든 데이터 셋을 가지고 class 별로 center를 구하는게 맞으나 그렇게 된다면 비효율적이며, 비실용적이기 때문에
mini-batch 내에서 center를 구한 다음,
매 iteration 마다 각 클래스 내의 feature들을 평균내서 center를 구함.
x_i에 대한 Lc의 기울기 및 c_yi 값의 update는 아래와 같이 계산됨.
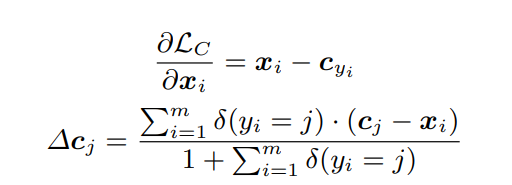
δ는 0~1 사이 값으로 표시되며, 1일때 만족스러운 성능을 낸다.
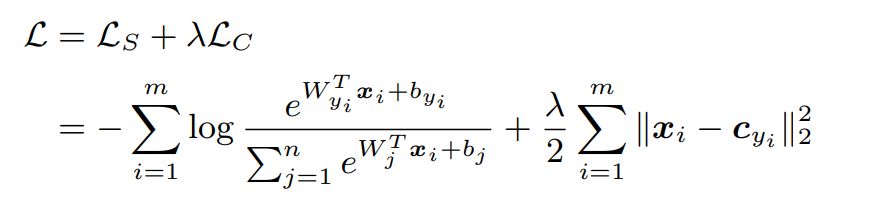
(λ는 다다음 사진에서 설명)
전체적인 디테일은 아래와 같음

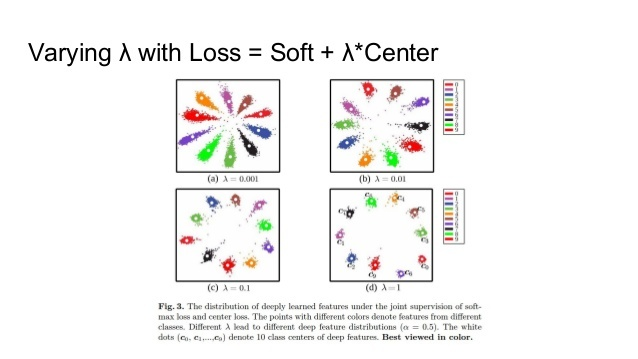
λ의 변화에 따라 미치는 영향은 아래와 같음

암튼 그래서 inter class 간은 최대한 separate 하고, intra 간에 데이터는 compact하게 만듬.
이렇게 데이터를 분류함으로서 조금 더 discrimination 하게 훈련할 수 있지만, 많은 GPU Memory와 각각의 ID에 대한 Training 이 필요함.

개발 잘하고 싶은 동근이의 공부방 (임시글 만수르)
오늘도 감사합니다!