기존 softmax는 학습은 class를 대표하는 w들을 잘 representation 되게 학습하는 것임.
잘 training 됐다면 아래와 같이data와 각이 가까운 w들이 나오게 됨.
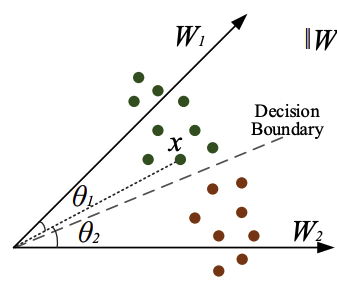
위의 그림을 본다면 class data에 각 편차를 최대한 줄인 w1, w2가 나온것을 알 수 있음.
위의 이미지에서 x는 w1에 속할 확률이 높을 것임.
하지만 이런식으로는 Decision Boundary(경계) 가 거의 분리되어있지 않기 때문에 다른 클래스로 분류될 확률이 큼.
- L-softmax
한줄 요약 : softmax + margin
그래서 아래와 같이 margin을 두어 차이를 벌림
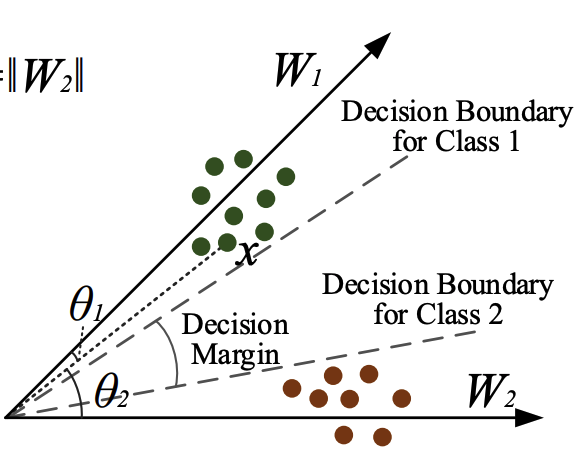
또한 이렇게 각만 영향을 미치는것이 아닌, 단순하게 w의 크기도 영향을 받음
무식하게 큰 w1 있다 가정한다면 x는 w1에 속할 확률이 커짐.
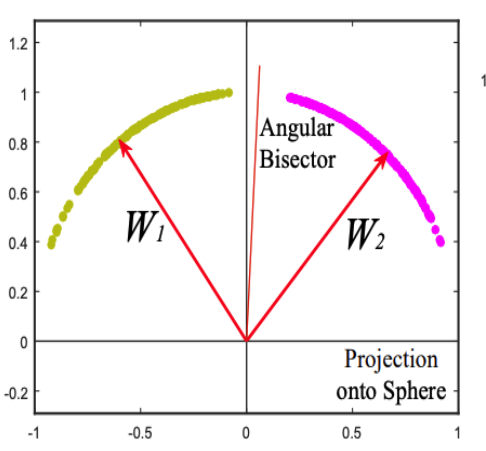
- A-softmax
한줄요약 : softmax + margin + fix w size
그렇기 때문에 w의 크기를 모두 같게 고정해버리고 오직 각으로만 분류 하겠다는 아이디어. (물론 margin도 줌)

개발 잘하고 싶은 동근이의 공부방 (임시글 만수르)
오늘도 좋은 정보 감사합니다!