AWS를 활용한 인공지능 모델 배포
1. 클라우드 기초
-
Before Cloud computing
- 과거에는 인터넷 환경에서 서비스를 제공하기 위해 서비스 제공하는 서비스 호스팅에 필요한 모든 것을 직접 구축
- 하지만 서버를 직접 구축하고 운영하는 자원과 인력 비용이 크고, 운영 상황의 변화에 능동적으로 대응하기가 어려움 -
IDC의 등장
- IDC: Internet Data Center
- 서버 운영에 필요한 공간, 네트워크, 유지 보수 등의 서비스 제공
- 서버 임대를 통해 자원을 효율적으로 이용하고 비용을 줄일 수 있었지만, 대부분의 IDC 서버 임대는 계약을 통해 일정 기간 임대를 하는 유연성이 떨어지는 구조
-
온디맨드 수요 증가
- 인터넷 사용자가 크게 증가하고 다양한 서비스를 제공하게 되면서 필요한 때에 필요한 만큼 서버를 증설하기 원함

Cloud Computing
클라우드라고 부르기도 하며 "인터넷 기반 컴퓨팅의 일종"
-
AWS(Amazon Web Services)
- 아마존의 클라우드를 통한 저장공간 및 연산 자원 제공 서비스
- 클라우드 컴퓨팅을 클라우드 서비스 플랫폼에서 컴퓨팅 파워, DB 저장공간, 애플리케이션 및 기타 IT 자원을 필요에 따라 인터넷을 통해 제공하고 사용한 만큼만 비용을 지불하는 것으로 정의 -
Features of Cloud Computing
1. 속도 - 주문형 셀프서비스
- 클라우드 제공자와 별도의 커뮤니케이션 없이 원하는 클라우드 서비스를 바로 이용 가능
2. 접근성
- 인터넷을 통해 사용자의 위치, 시간과 관계없이 어떤 디바이스로도 접근 가능
3. 확장성
- 갑작스러운 이용량 증가나 변화에 신속하고 유연하게 추가 확장이 가능
4. 생산성
- 하드웨어, 소프트웨어 설치에 들어가는 시간과 비용 절감으로 핵심업무에 집중
5. 보안, 안정성
- 클라우드 공급자가 전체적으로 보안이나 안정성에 대해 준비
6. 측정가능성
- 분초단위로 사용자가 클라우드 서비스를 사용한 만큼만 계량하여 과금
-
클라우드 컴퓨팅 운용 모델: 구축 및 배포 유형에 따라 세 가지 형태로 구분
- 퍼블릭(Public): 서비스 유지를 위한 모든 인프라와 IT 기술을 클라우드에서 사용, IT 관리 인력이나 인프라 구축 비용이 없는 경우에 유용
- 프라이빗(Private): 고객이 자체 데이터센터에서 직접 클라우드 서비스를 구축하는 형태로, 내부 계열사나 고객에게만 제공하여 인프라 확충은 쉬우나 IT 기술 확보가 어려운 단점이 있음
- 하이브리드(Hybrid): 고객의 핵심 시스템은 내부에 두면서도 외부의 클라우드를 활용하는 형태로, IT 기술은 클라우드에서 받고 서비스 유지를 위한 인프라는 고객의 것을 혼용하여 퍼블릭의 경제성과 프라이빗의 보안성을 모두 고려
-
클라우드 서비스 제공 모델
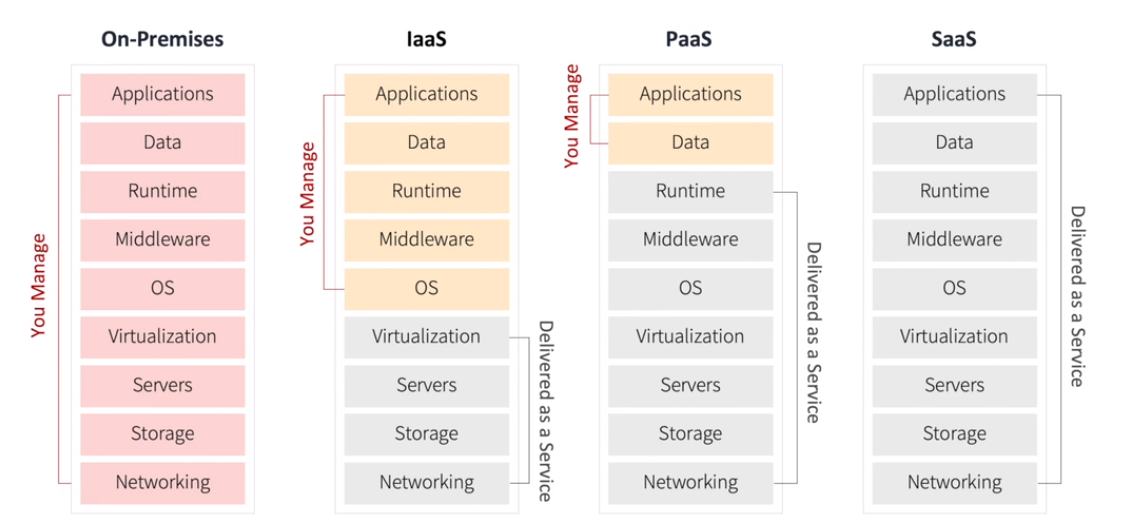
- On-Premises: A-Z까지 모든걸 직접 구축하고 관리하는 형태
- IaaS(Infra as a Service): 네트워크/스토리지/서버 등 인프라만 클라우드를 빌려서 사용
- PaaS(Platform as a Service): 서비스를 개발할 수 있는 안정적인 환경(platform)과 그 환경을 이용하는 응용프로그램을 개발할 수 있는 API까지 제공하는 형태
- SaaS(Software as a Service): 클라우드 환경에서 동작하는 응용프로그램을 서비스 형태로 제공하는 것
2. 실습: AWS & 실습 환경 세팅
AWS와 SSH를 처음 사용하면서 정말 해결해야할 이슈가 너무너무 많았다.
-
사용자 폴더명이 한글이기 때문에 어김없이 문제가 발생했다. 분명히 어딘가에서 막힐 것을 알았지만 포맷을 미뤄왔던 나... 결국 백업 후 윈도우를 아예 다시 깔았고 모든 개발환경 세팅을 다시 하는데 하루가 꼬박 걸린 것 같다.
-
AWS EC2 인스턴스 생성
I. AMI 선택

II. 인스턴스 유형 선택 및 보안 그룹 설정
인스턴스 유형은 프리티어에서 사용할 수 있는 't2.micro' 선택
사용자 지정 TCP 추가한 후 포트 범위 5000, 소스 0.0.0.0/0 입력
III. 키 페어 생성 및 인스턴스 시작
새 키 페어를 생성하고 키 페어를 다운로드 받자. 이 키 페어는 이후 인스턴스에 접속하기 위해 꼭 필요하다!
IV. 탄력적 IP 생성 및 인스턴스에 연결 -
VS Code로 환경 테스트
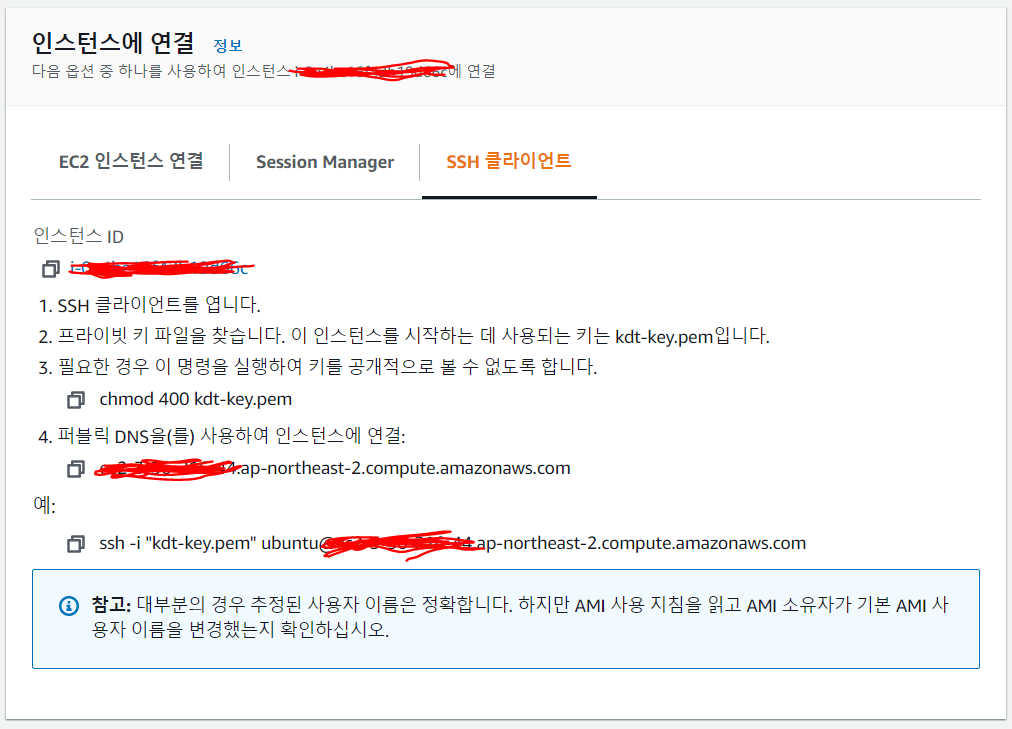
I. 인스턴스 연결 초기화
Window의 경우 PowerShell로 진행 가능하다.
키 페어를 Users\사용자폴더.ssh 하위에 위치시킨 후 접속하자.
II. 원격 접속 및 개발을 위한 VS Code 플러그인 설치
VS Code Extension에서 Remote-SSH 및 Remote Development를 설치한다.
III. 인스턴스에 접속
Remote-SSH: Connect Current Window to Host ... 선택
ssh -i "키 페어 파일 절대경로"ubuntu@public-ip-address 입력 후 Add New SSH Host까지
RemoteSSHPlatform으로 Linux 선택
3. API to serve ML model
-
Architecture of API to serve ML model
AWS EC2와 Python Flask 기반 모델 학습 및 추론을 요청/응답하는 API 서버 개발

-
API란?
- Application Programming Interface
- 기계와 기계, 소프트웨어와 소프트웨어 간의 커뮤니케이션을 위한 인터페이스를 의미
- 노드와 노드 간 데이터를 주고 받기 위한 인터페이스로, 사전에 정해진 정의에 따라 입력이 들어왔을 때 적절한 출력을 전환해야 함
-
RESTful API
- REST 아키텍처를 따르는 API로 HTTP URI를 통해 자원을 명시하고 HTTP Method를 통해 필요한 연산을 요청하고 반환하는 API를 지칭
- for ML/DL model inference: 일반적으로 데이터 값을 담아 요청하고 모델이 추론한 결과에 대한 return을 json 형태로 반환하도록 설계 -
Model Serving
- 학습된 모델을 REST API 방식으로 배포하기 위해서 학습된 모델의 Serialization과 웹 프레임워크를 통해 배포 준비 필요
- 모델을 서빙할 때는 학습 시의 데이터 분포나 처리 방법과의 연속성 유지 필요
- 모델을 배포하는 환경에 따라 다양한 Serving Framework를 고려하여 활용

-
Serialization & De-serialization
- 학습된 모델의 재사용 및 배포를 위해서 저장하고 불러오는 것
- Serialization을 통해 ML/DL model object를 disk에 write하여 어디든 전송하고 불러올 수 있는 형태로 반환
- De-Serialization을 통해 Python 혹은 다른 환경에서 model을 불러와 추론/학습에 사용
- 모델을 배포하는 환경을 고려해 환경에 맞는 올바른 방법으로 Serialization을 해야 De-Serialization이 가능 -
Model Serving을 위한 다양한 Frameworks
- TensorFlow serving, TorchServe, TensorRT
- Flask와 같은 웹프레임워크는 클라이언트로부터의 요청을 처리하기 위해 주로 사용
- 별도의 모델 추론을 위한 AP 서버를 운용하여 내부 혹은 외부 통신을 통해 예측/추론값 반환
4. 실습: Serialization & De-serialization
-
실습 환경 세팅
conda activate pytorch_p36# 아나콘다 가상환경 실행
git clone <소스코드가 저장된 git repository url># 소스코드 다운로드
cd ./kdt-ai-was# 해당 폴더로 이동
pip install -r requirements.txt -
머신러닝 모델 학습
python train_ml.py
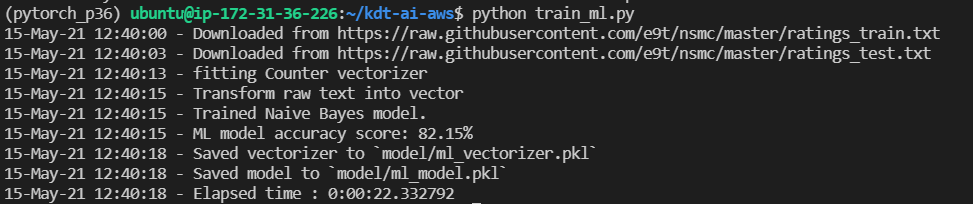
joblib을 이용해 serialization 된 것을 확인(serialization과 de-serialization방법은 동일해야 함!)
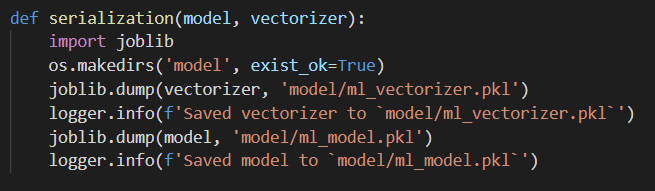
-
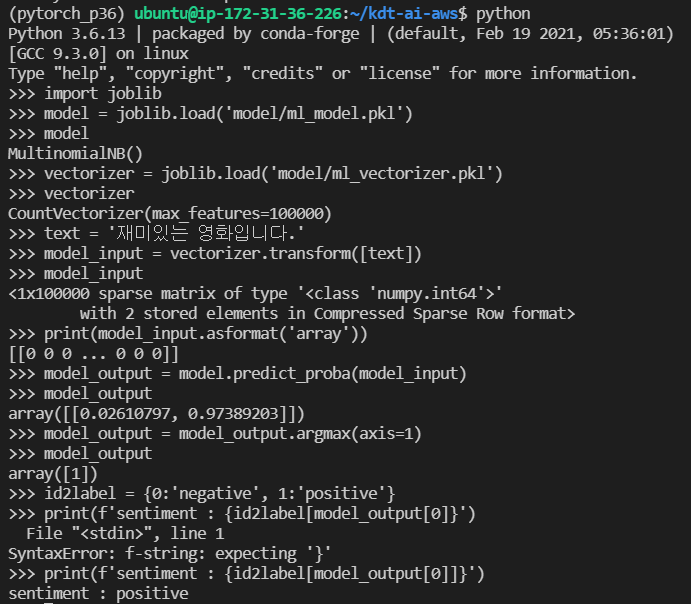
De-serialization
저장된 모델을 불러와 특정 입력 값에 대한 예측 수행
5. 실습: Inference를 위한 model handler 개발
-
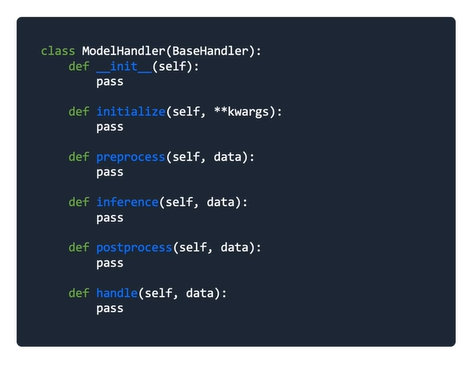
Skeleton of model handler to serve model
-
handle(): 요청 정보를 받아 적절한 응답을 반환
1. 정의된 양식으로 데이터가 입력됐는지 확인
2. 입력값에 대한 전처리 및 모델에 입력하기 위한 형태로 변환
3. 모델 추론
4. 모델 반환값의 후처리 작업
5. 결과 반환

-
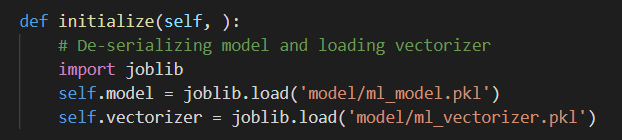
initialize(): 데이터 처리나 모델, configuration 등 초기화
1. Configuration 등 초기화
2. (Optional) 신경망을 구성하고 초기화
3. 사전 학습한 모델이나 전처리기 불러오기 (De-serialization)
- 모델은 전역변수로 불러와야 함. 만약 inference를 할 때마다 모델을 불러오도록 한다면 시간이나 자원의 낭비.
- 일반적으로 요청을 처리하기 전에 모델을 불러 둔다.
-
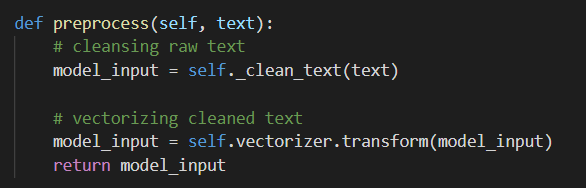
preprocess(): Raw input을 전처리 및 모델 입력 가능 형태로 변환
1. Raw input 전처리
데이터 클린징의 목적과 학습된 모델의 학습 당시 scaling이나 처리 방식과 맞춰주는 것이 필요
2. 모델에 입력가능한 형태로 변환
vectorization, converting to id 등의 작업
-
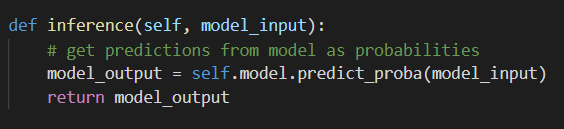
inference(): 입력된 값에 대한 예측/추론
1. 각 모델의 predict 방식으로 예측 확률분포 값 반환
-
postprocess(): 모델의 예측값을 response에 맞게 후처리 작업
1. 예측된 결과에 대한 후처리 작업
2. 보통 모델이 반환하는 건 확률분포와 같은 값이기 때문에 response에서 받아야 하는 정보로 처리하는 역할을 많이 함

-
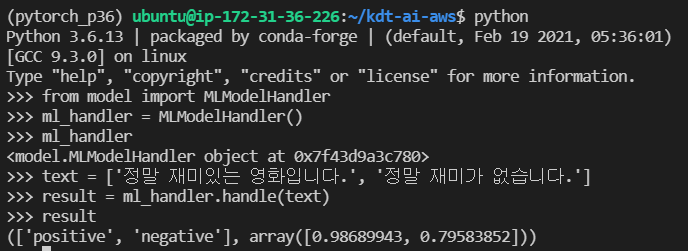
Model handler 사용하기
6. Flask 기반 감성분석 API 개발
-
API 정의
- key:value 형태의 json 포맷으로 요청을 받아 text index 별로 key:value로 결과를 저장한 json 포맷으로 결과 반환
- post 방식으로 predict 요청
- do_fast를 true로 할 경우 머신러닝 모델로, false의 경우 딥러닝 모델로 추론 -
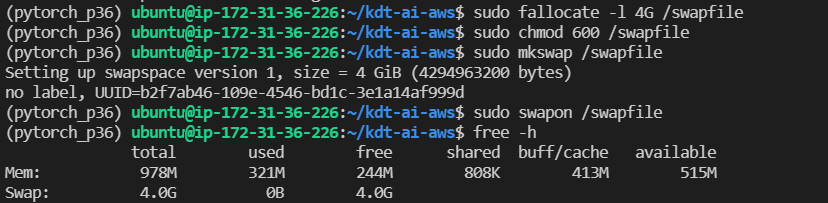
가상메모리 추가
용량 문제 때문에 unittest가 되지 않는다는 이슈가 있었는데, 아래와 같은 명령어를 입력하여 swap memory를 만들 수 있다.
-
Unittest model handlers

-
Flask API 개발 & 배포
Model을 전역변수로 불러오고 요청된 텍스트에 대해 예측 결과를 반환하는 코드 입력 -
Test API on remote
원격에서 서버로 API에 요청하여 테스트 수행
host: EC2 인스턴스 생성 시에 받은 퍼블릭 IP 주소 또는 직접 할당한 탄력적 IP 주소 (ex. 54.83.1.129)
port: EC2 인스턴스 생성 시에 설정했던 port 번호 (ex.5000)

