TIL
1.[TIL Day1] 어서와! 자료구조와 알고리즘은 처음이지? (1)

'K-Digital Training: 프로그래머스 인공지능 데브코스 2기' 첫 날.그리고 배움기록 첫 날.velog도 slack도 모든 것이 서툴고 어색하지만, 언제나 그랬듯 이또한 익숙해질 것이라 믿는다 :>
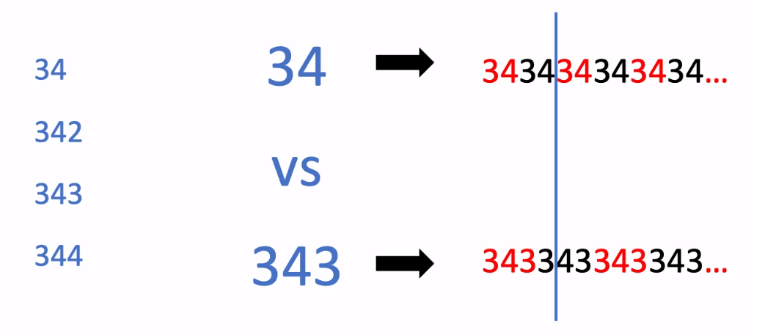
2.[TIL Day2] 어서와! 자료구조와 알고리즘은 처음이지? (2)
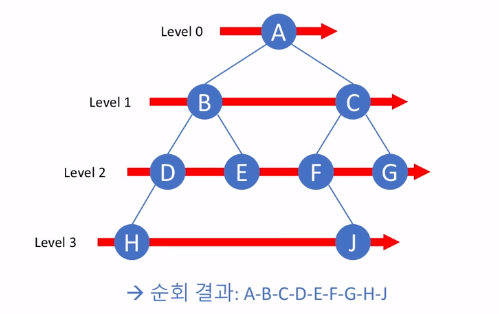
수식의 후위 표기법 후위 표기법(postfix notation): 연산자가 피연산자들의 뒤에 위치 괄호가 필요하지 않으며 앞에서부터 순서대로 연산 가능
3.[TIL Day3] 파이썬을 무기로, 코딩테스트 광탈을 면하자! (1)
유형별 코딩 테스트 대표 문제 1. 해시(Hash) 완주하지 못한 선수 문제에서 선수의 이름이 주어졌다 -> 문자열로 접근할 수 있는 좋은 자료구조는 무엇일까?
4.[TIL Day4] 파이썬을 무기로, 코딩테스트 광탈을 면하자! (2)

최소/최대 원소를 빠르게 꺼낼 수 있으면 좋겠다! -> 최소/최대 힙
5.[TIL Day5] 코딩테스트 더 풀어보기 (1)
문제 풀이 과정 줄을 서 있는 사람들이 구매하려는 좌석의 좌표를 중복되지 않게 세어야 한다.사전 자료형을 이용하자.
6.[TIL Day6] 코딩테스트 더 풀어보기 (2)
BFS 풀이 정확도가 50점이 나왔다. 다른 도시를 거쳐가는 것이 바로 가는 도로보다 비용이 더 싼 경우가 있을 수 있다.
7.[TIL Day7] 인공지능 수학 - 선형대수
terminal 명령어 \- dir: 현재 디렉토리에 있는 파일, 폴더 확인 \- cd 디렉토리 이름: change directory \- cd ..: 상위 디렉토리로 이동 \- mkdir 디렉토리 이름: make directory
8.[TIL Day8] 인공지능 수학 - 미적분
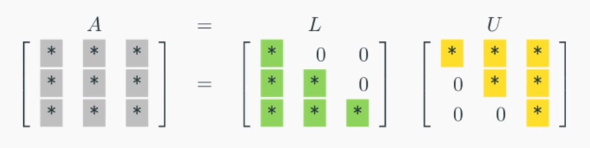
LU분해 주어진 행렬을 특정한 형태를 가지는 두 행렬의 곱으로 나누는 행렬분해이다.
9.[TIL Day9] 인공지능 수학 - 자료의 정리
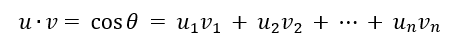
벡터의 내적 \- 두 벡터 u, v 간의 내적이 0이면 두 벡터는 직교(orthogonal)이다. \- 직교의 물리적 의미: uㅗv일 때, u방향으로의 전진은 v방향에서 전혀 측정되지 않는다.
10.[TIL Day10] 라이브 세션 - 코딩테스트 문제 같이 풀기
문제 설명 \- 빙고 게임 보드에 적힌 숫자가 담겨있는 배열 board, 게임 보드에서 순서대로 지운 숫자가 들어있는 배열 nums가 매개변수로 주어진다.
11.[TIL Day11] 인공지능 수학 - 확률과 확률분포
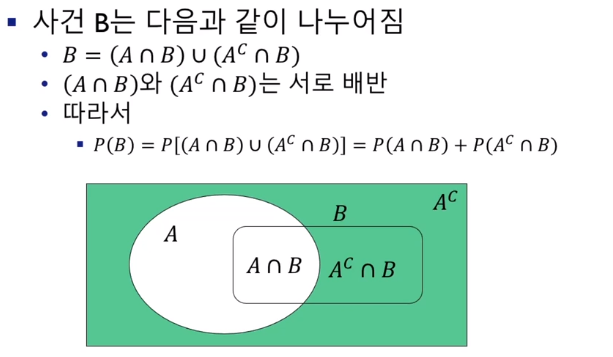
인공지능 수학 - 확률과 확률분포 > ### 확률(Probability) 상대 도수에 의한 정의 똑같은 실험을 무수히 많이 반복할 때 어떤 일이 일어나는 비율
12.[TIL Day12] 인공지능 수학 - 추정, 검정, 엔트로피
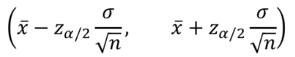
표본조사 표본조사를 통해 파악하고자 하는 정보는 '모수'(모평균, 모분산, 모비율 등) 모수를 추정하기 위해 표본을 선택하여 표본평균이나 표본분산 등 계산
13.[TIL Day13-1] Git 사용법 알아보기
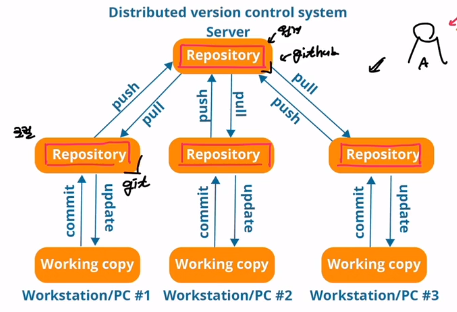
Git이란 무엇인가? 분산 버전관리 시스템! Git 시작하기 저장소에서의 파일의 상태와 명령어 알기
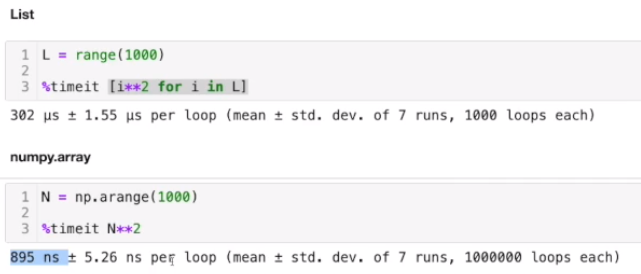
14.[TIL Day13-2] Python으로 데이터 다루기 I - Numpy
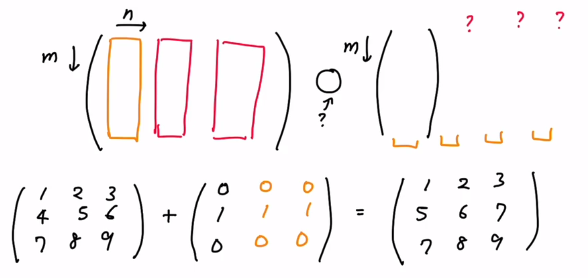
Python으로 데이터 다루기 I - Numpy
15.[TIL Day14] Python으로 데이터 다루기 II - Pandas
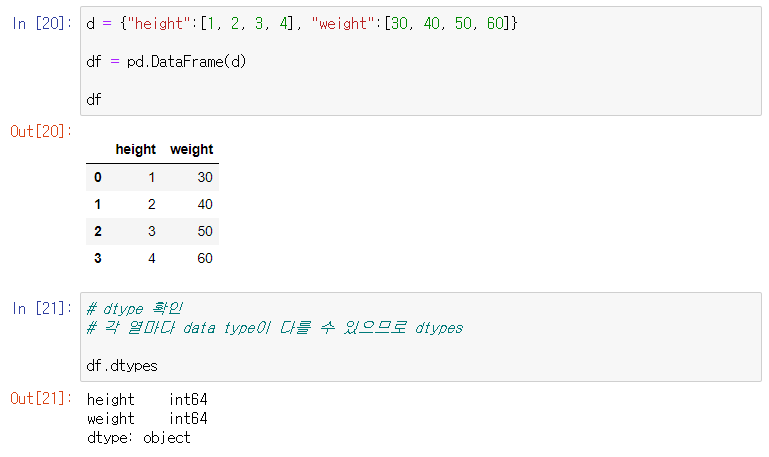
Python으로 데이터 다루기 II - Pandas Series? 1-D labeled array 인덱스를 지정해줄 수 있음
16.[TIL Day15] Python으로 시각화하기 - Matplotlib
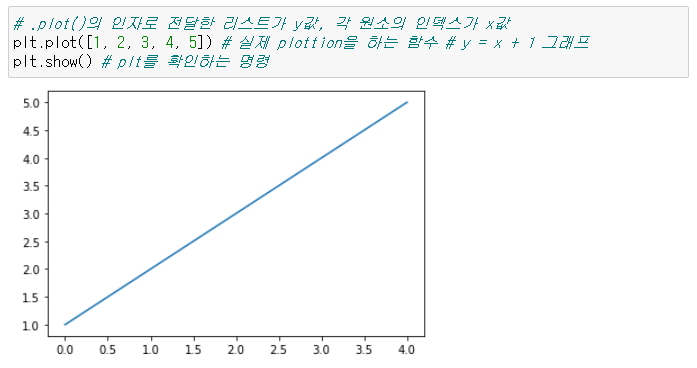
파이썬의 데이터 시각화 라이브러리
17.[TIL Day16] Python으로 시각화 프로젝트
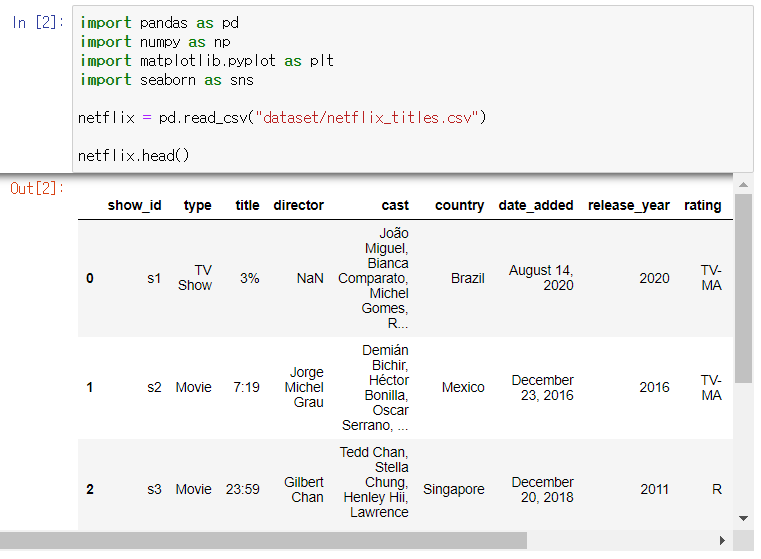
넷플릭스 데이터셋으로 다음 문제를 해결해주세요.
18.[TIL Day17] Web Application with Flask
Flask? Python 기반 마이크로(essential!) 웹 프레임워크
19.[TIL Day19] 데이터 씹고 뜯고 맛보고 즐기기 - EDA
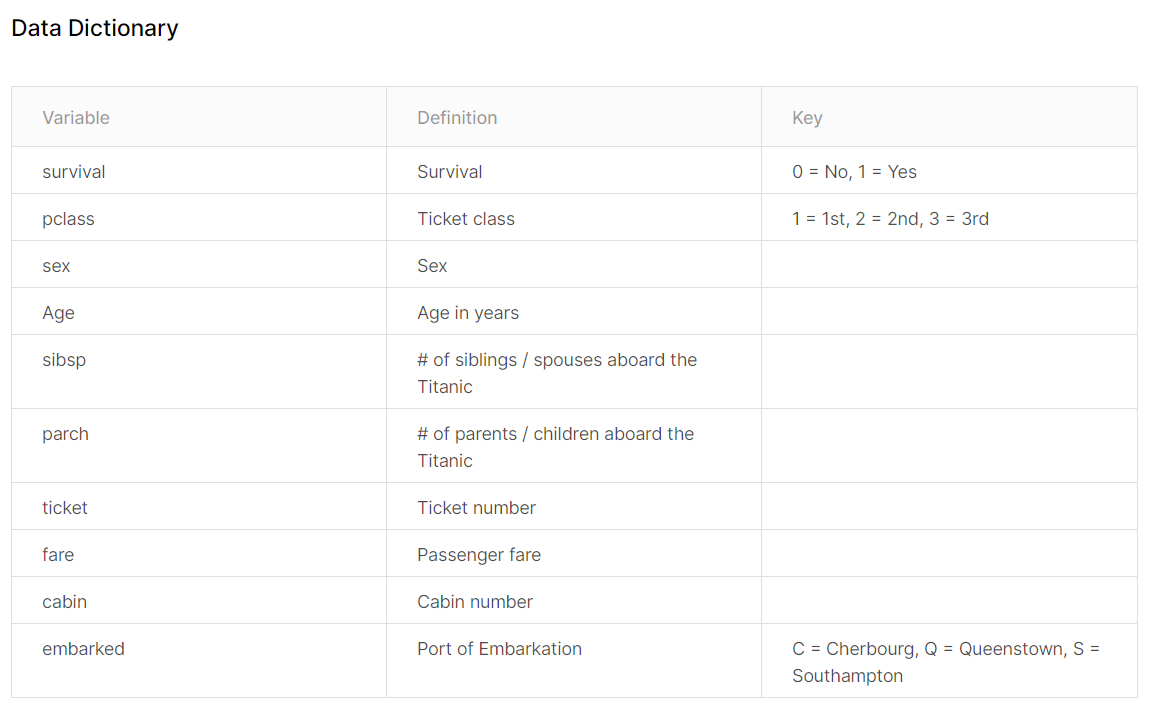
탐색적 데이터 분석(EDA): 데이터 그 자체만으로부터 인사이트를 얻어내는 접근법!
20.[TIL Day18] 클라우드를 활용한 머신러닝 모델 Serving API 개발

AWS를 활용한 인공지능 모델 배포
21.[TIL Day20] Web Application with Django

Web Application with Django 1. django 시작하기 2. View로 Request Handling하기 3. Template로 보여줄 화면 구성하기
22.[TIL Day21] Django로 동적 웹 페이지 만들기
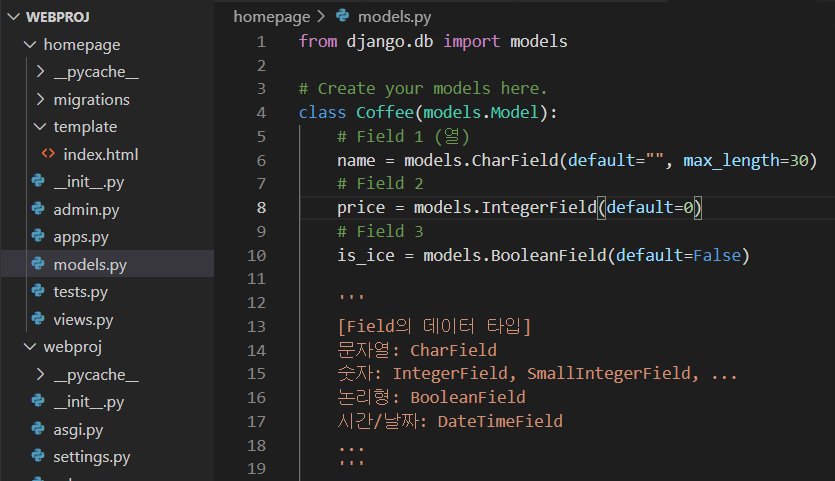
Django로 동적 웹 페이지 만들기
23.[TIL Day22] 데이터 시각화 웹 페이지 만들기
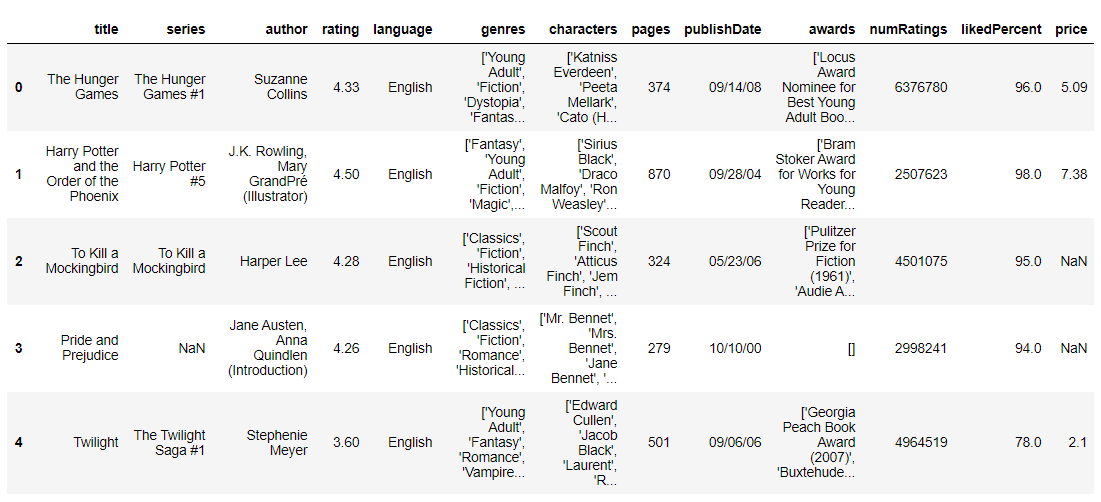
1. 탐색적 데이터 분석 2. Flask 웹 만들기 3. pythonanywhere로 웹 페이지 배포하기
24.[TIL Day23] Machine Learning 기초 - Probability
- 확률이론(probability theory): *예측값의 불확실성을 정량화*시켜 표현할 수 있는 수학적인 프레임워크 제공 - 결정이론(decision theory): 확률적 표현을 바탕으로 최적의 예측을 수행할 수 있는 방법론 제공
25.[TIL Day24] Machine Learning 기초 - Decision Theory & Linear Regression
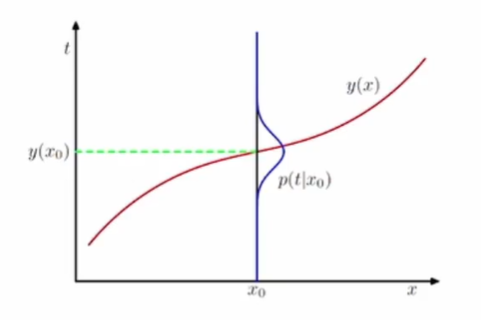
1. 결정이론(Decision Theory) 결정이론이란? 새로운 값 x가 주어졌을 때 확률모델 p(x, t)에 기반해 최적의 결정을 내리는 것
26.[TIL Day25] E2E 머신러닝 프로젝트
End-to-End 머신러닝 프로젝트 부동산 회사에 막 고용된 데이터 과학자라고 가정하고 예제 프로젝트를 진행해보자. 캘리포니아 주택 가격 데이터셋을 사용한다.
27.[TIL Day26] Machine Learning 기초 - Linear Algebra
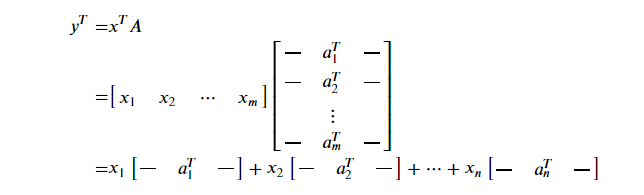
선형대수와 행렬미분의 기초를 배우고 간단한 머신러닝 알고리즘(PCA)을 유도해보고자 한다.
28.[TIL Day27] ML 기초 실습 과제
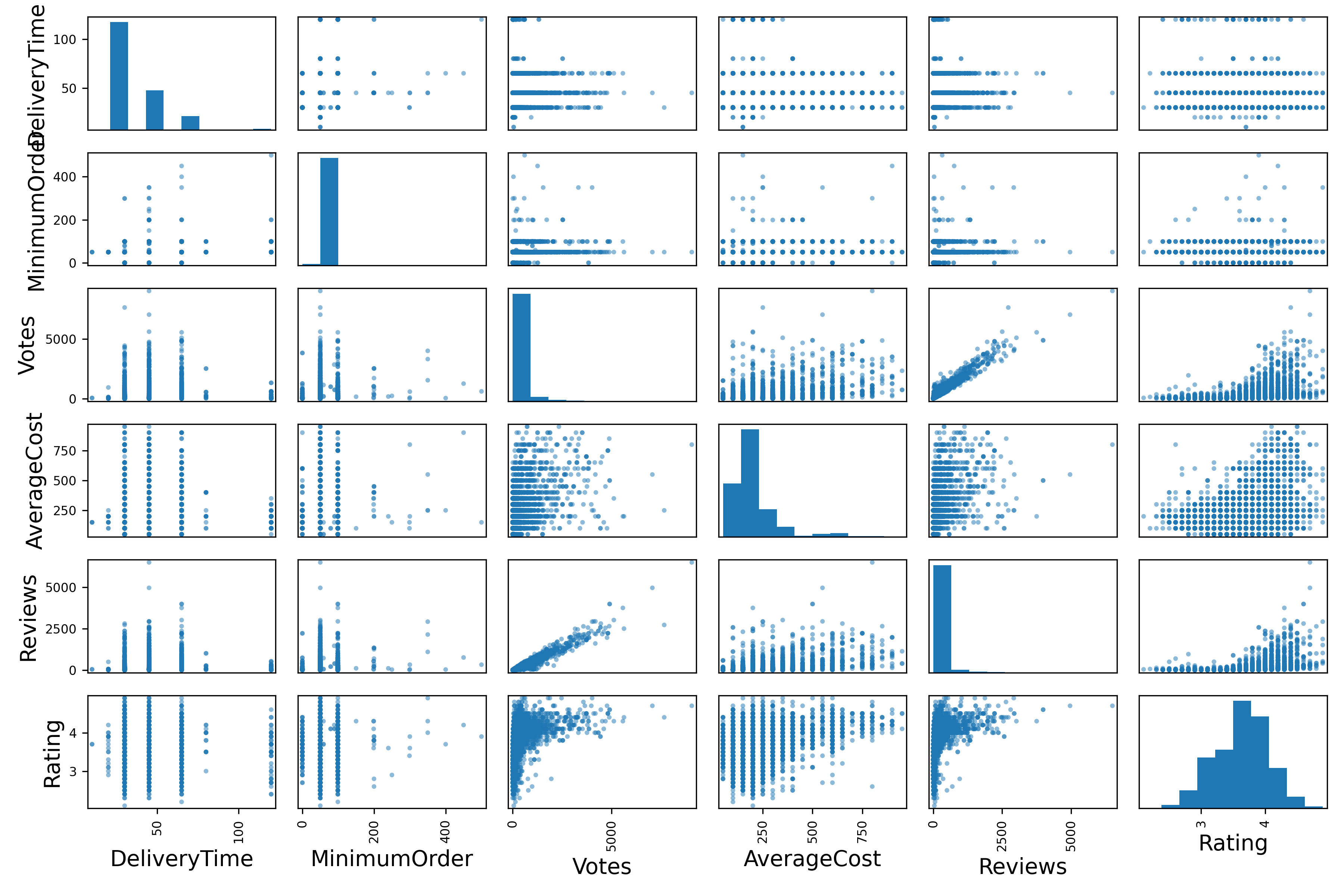
모델이 예측하는 값은 “음식배달에 걸리는 시간"입니다. 배달시간을 정확하게 예측하는 것은 사용자의 경험에 많은 영향을 미치게 됩니다.
29.[TIL Day28] Machine Learning 기초 - Matrix Calculus

이전 게시글과 이어서 작성하였다. 3. 중요 연산과 성질들 (Operations and Properties)
30.[TIL Day29] Machine Learning 기초 - Probability Distributions I

확률분포 Part 1: 이산확률분포에 대해 알아본다.
31.[TIL Day30] Machine Learning 기초 - Probability Distributions II
가우시안 분포(Gaussian Distribution) 가우시안 분포가 일어나는 여러가지 상황: 정보이론에서 엔트로피를 최대화시키는 확률분포, 중심극한정리
32.[TIL Day31] Machine Learning 기초 - Linear Models for Regression
선형 기저 함수 모델
33.[TIL Day32] Machine Learning 기초 - Linear Models for Classification
선형분류의 목표와 방법들
34.[TIL Day33] 신경망의 기초 - 인공지능과 기계학습 개요
어떤 컴퓨터 프로그램이 T라는 작업을 수행한다. 이 프로그램의 성능을 P라는 척도로 평가했을 때 경험 E를 통해 성능이 개선된다면, 이 프로그램은 학습을 한다고 말할 수 있다.
35.[TIL Day34] 신경망의 기초 - 기계학습과 수학
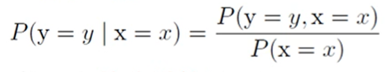
벡터와 행렬 놈(norm) 벡터와 행렬의 거리(크기) 측정 벡터의 p차 놈(p=1; absolute-value norm, p=2; euclidean norm) 벡터의 최대 놈 행렬의 프로베니우스 놈 벡터공간 벡터들의 선형결합으로 만들어지는 공간
36.[TIL Day35] 신경망의 기초 - 다층퍼셉트론 I
인공신경망
37.[TIL Day36] 신경망의 기초 - 다층퍼셉트론 II
다층 퍼셉트론 퍼셉트론은 선형 분리가 불가능한 상황에서 일정량의 오류가 생길 수 밖에 없는 한계를 가진다. 이를 극복하기 위해 고안된 것이 다층 퍼셉트론!
38.[TIL Day37] 신경망의 기초 - 심층학습 기초 I
혁신적 알고리즘 등장 합성곱 신경망(CNN)
39.[TIL Day38] 신경망의 기초 - 심층학습 기초 II
DMLP와 CNN의 비교
40.[TIL Day39] 신경망의 기초 - 심층학습 기초 III
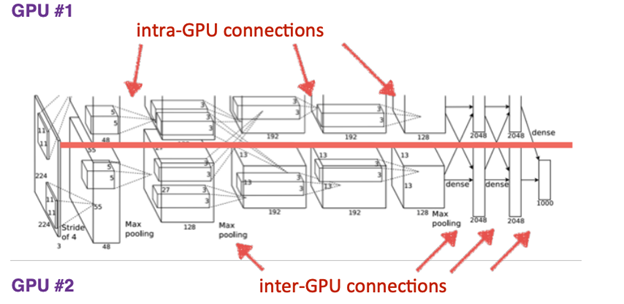
향후 CNN은 FC층의 매개변수를 줄이는 방향으로 발전
41.[TIL Day40] 신경망의 기초 - 심층학습 최적화 I
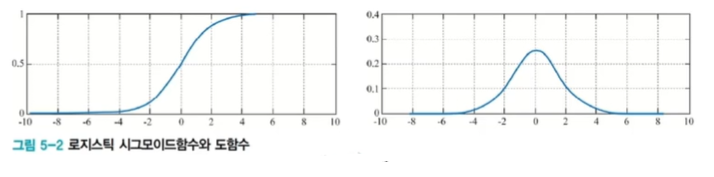
심층학습 최적화 I
42.[TIL Day41] 신경망의 기초 - 심층학습 최적화 II
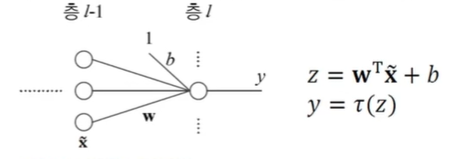
심층학습 최적화 II
43.[TIL Day42] 신경망의 기초 - 순환 신경망 I
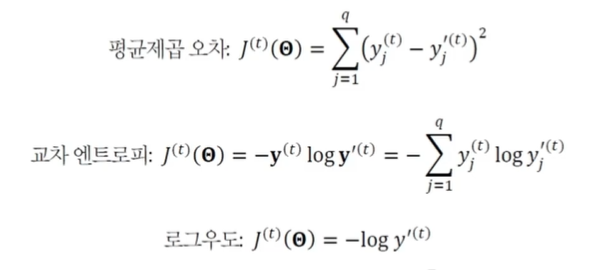
순차 데이터를 위한 순환 신경망, RNN
44.[TIL Day43] 신경망의 기초 - 순환 신경망 II
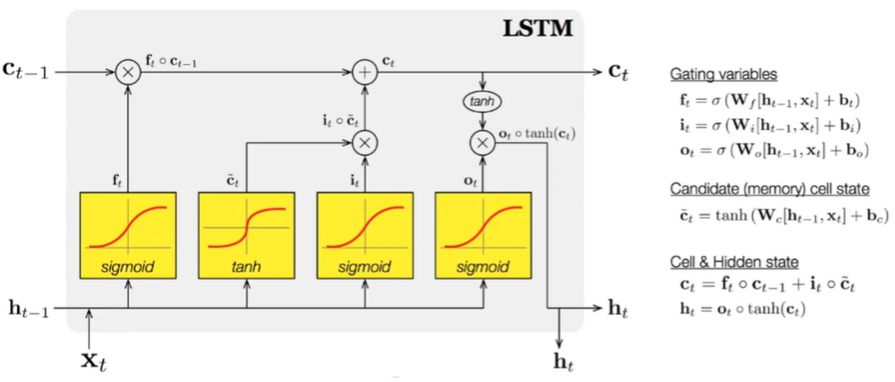
LSTM의 구조 및 동작과 활용 사례
45.[TIL Day44] SQL과 데이터분석 - Redshift 소개
1. 데이터 웨어하우스와 Redshift
46.[TIL Day45-1] SQL과 데이터분석 - DDL, DML, SELECT
2. SELECT 배우기
47.[TIL Day45-2] SQL과 데이터분석 - SELECT 실습
현업에서 깨끗한 데이터란 존재하지 않는다. 항상 데이터를 믿을 수 있는지 의심할 것!
48.[TIL Day46] SQL과 데이터분석 - GROUP BY와 CTAS
GROUP BY와 Aggregate 함수 테이블의 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산
49.[TIL Day47] SQL과 데이터분석 - JOIN
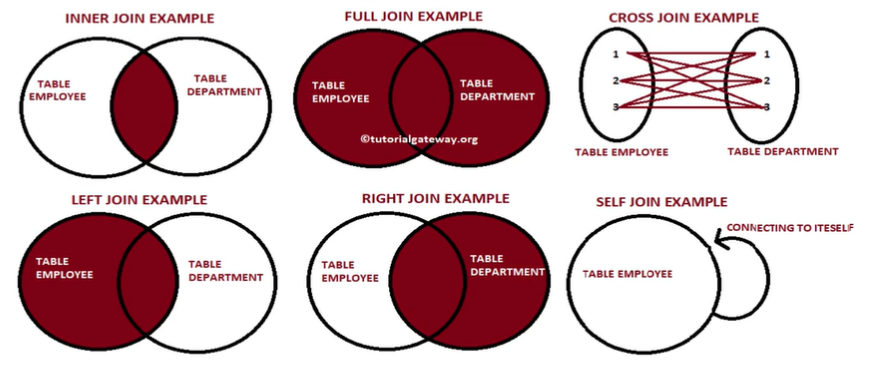
두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 merge하는 방법. 이는 star schema로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용된다.
50.[TIL Day48] SQL과 데이터분석 - 트랜잭션과 기타 고급 SQL 문법
트랜잭션이란? Atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법
51.[TIL Day49] Big Data: 데이터팀의 역할
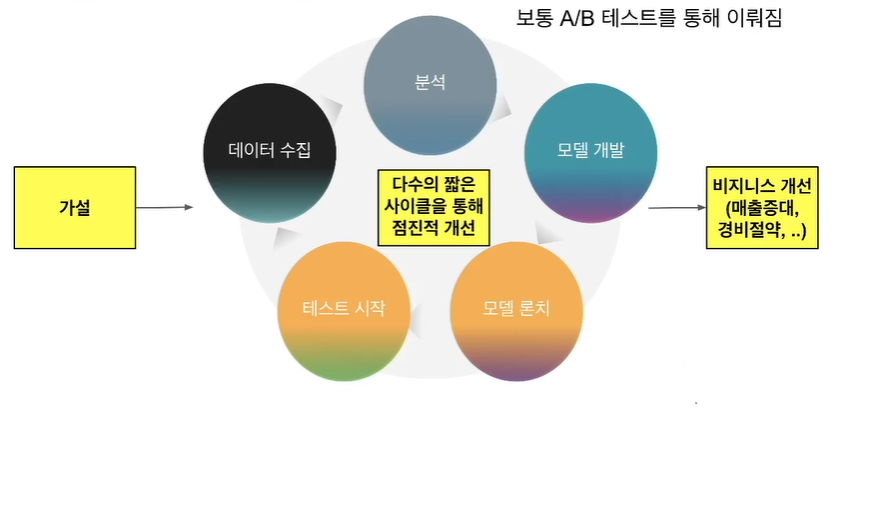
데이터 팀의 Mission 신뢰할 수 있는 데이터를 바탕으로 부가가치 생성
52.[TIL Day50] Big Data: Spark 소개
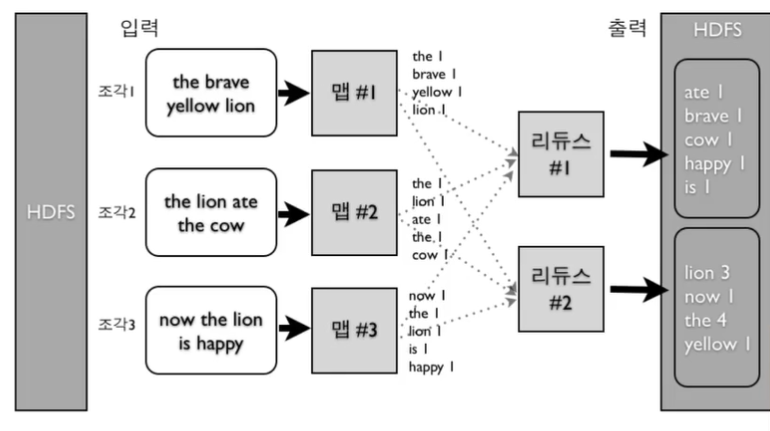
빅데이터의 정의 "서버 한 대로 처리할 수 없는 규모의 데이터"
53.[TIL Day51] Big Data: SparkSQL을 이용한 데이터 분석
구조화된 데이터 처리를 위한 Spark 모듈
54.[TIL Day52] 디지털 마케팅과 데이터
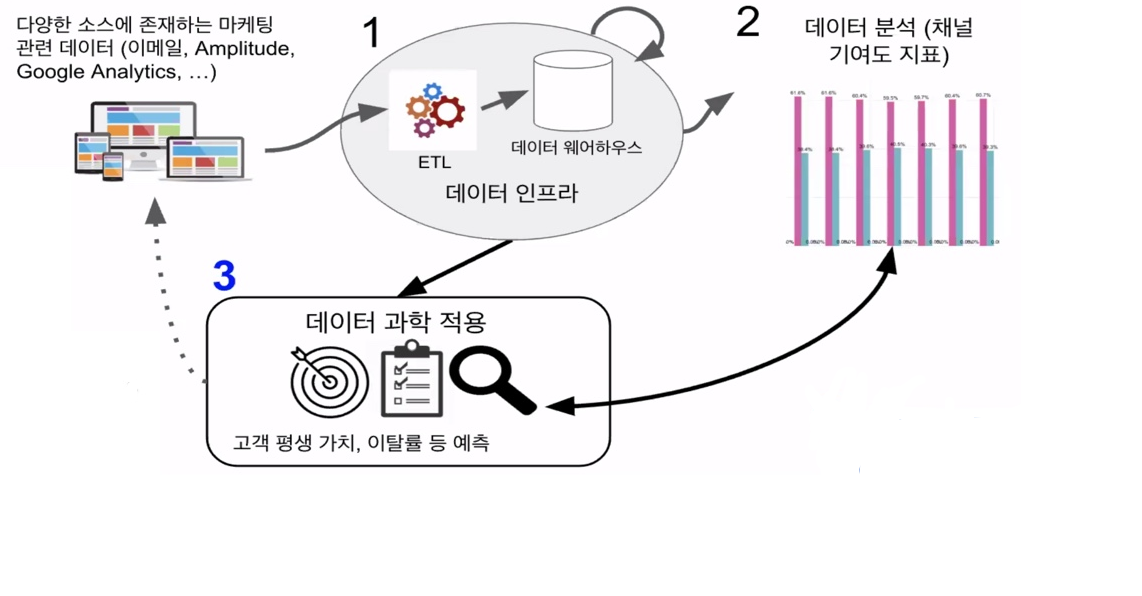
마케팅 분석 필수 데이터
55.[TIL Day53] Big Data: Spark MLib 소개와 머신러닝 모델 빌딩
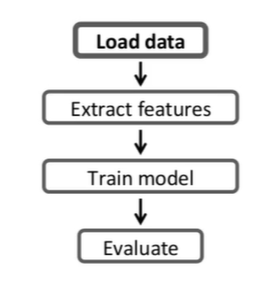
Spark MLib 소개
56.[TIL Day54] Big Data: ML Pipeline과 Tuning 소개와 실습
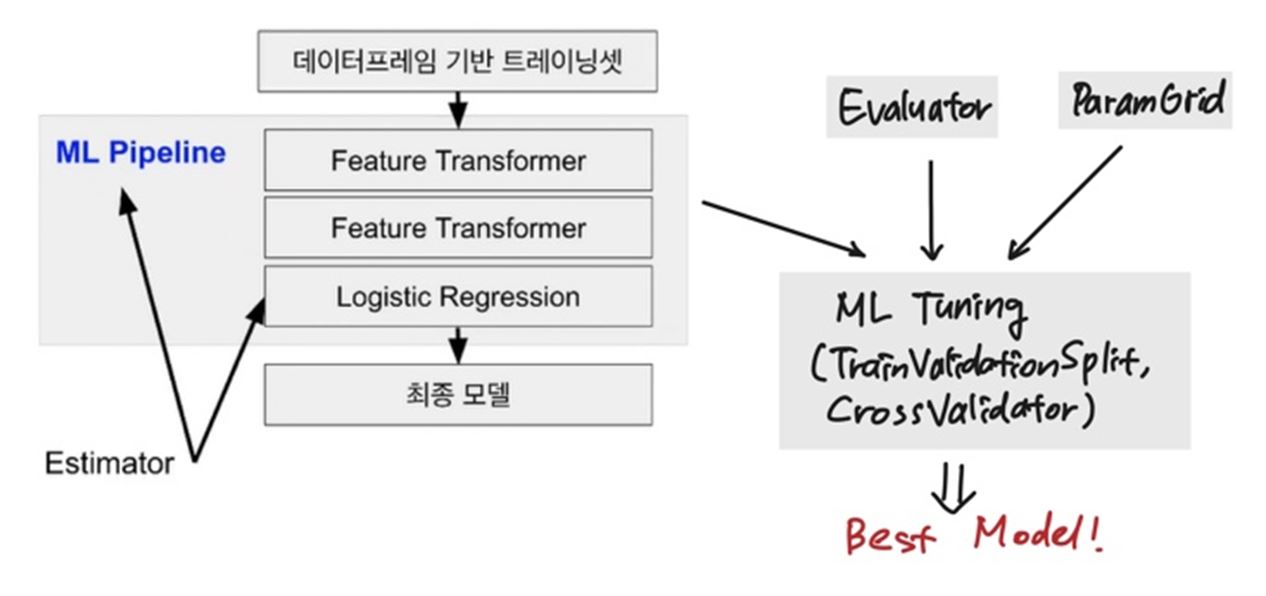
Spark MLlib의 ML Pipeline과 모델 Tuning
57.[TIL Day55] Natural Language Processing: 텍스트 전처리

텍스트 데이터 전처리 - Subword Tokenization
58.[TIL Day56] Natural Language Processing: 언어모델
언어모델의 목표는 주어진 문장이 나타날 확률을 구하는 것이다.
59.[TIL Day58] Natural Language Processing: 단어 임베딩
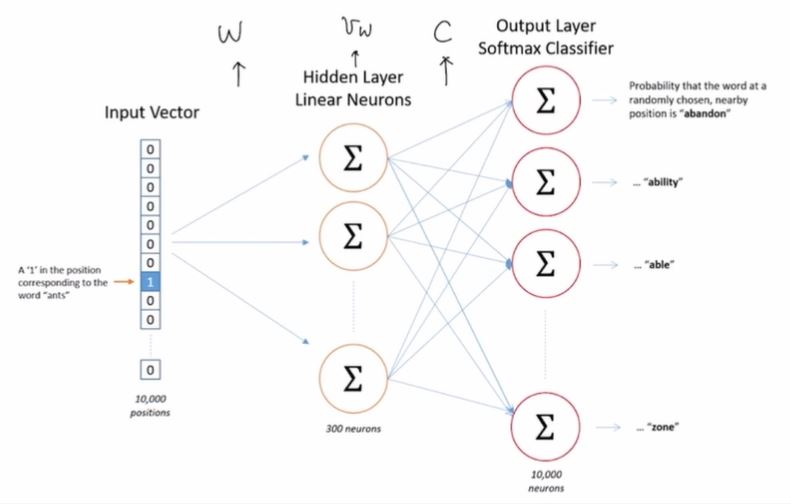
단어 임베딩 단어의 의미를 어떻게 나타낼 수 있을까? 단어간의 관계를 잘 표현할 수 있어야 좋은 표현방식이다. One-hot encoding 방식은 단어간의 관계를 표현하기 어렵다. 단어의 의미를 나타내기 위해 다음과 같은 것들을 고려해야 한다.
60.[TIL Day60] Recommendation System: 추천 엔진이란?
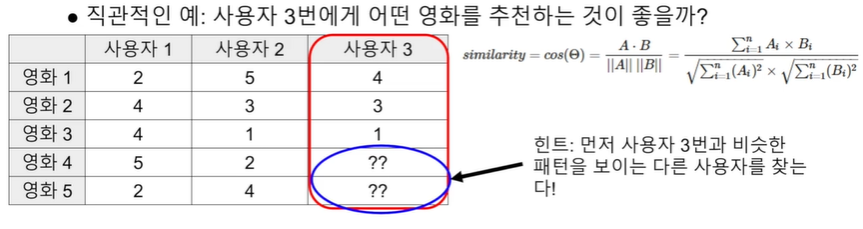
추천 엔진의 정의: 사용자가 관심있어 할만한 아이템을 제공해주는 자동화된 시스템