예제
1. 사용자별 처음과 마지막 채널 찾기
- ROW_NUMBER를 이용하자
- ROW_NUMBER() OVER (PARTITION BY field1 ORDER BY field2) nn- PARTITION BY: 그룹핑할 필드
- ORDER BY: 열 번호를 매길 기준
방법 (1) CTE를 빌딩블록으로 사용
WITH first AS (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
), last AS (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts DESC) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
)
SELECT first.userid AS userid, first.channel AS first_channel, last.channel AS last_channel
FROM first
JOIN last ON first.userid = last.userid and last.seq = 1
WHERE first.seq = 1;방법 (2) JOIN 방식
SELECT first.userid AS userid, first.channel AS first_channel, last.channel AS last_channel
FROM (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
) first
JOIN (
SELECT userid, ts, channel, ROW_NUMBER() OVER(PARTITION BY userid ORDER BY ts DESC) seq
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
) last ON first.userid = last.userid and last.seq = 1
WHERE first.seq = 1;방법 (3) GROUP BY 방식
SELECT userid,
MAX(CASE WHEN rn1 = 1 THEN channel END) first_touch,
MAX(CASE WHEN rn2 = 1 THEN channel END) last_touch
FROM (
SELECT userid,
channel,
(ROW_NUMBER() OVER (PARTITION BY usc.userid ORDER BY st.ts asc)) AS rn1, -- 오름차순으로 계산
(ROW_NUMBER() OVER (PARTITION BY usc.userid ORDER BY st.ts desc)) AS rn2 -- 내림차순으로 계산
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
)
GROUP BY 1;방법 (4) FIRST_VALUE/LAST_VALUE - 가장 직관적!
SELECT DISTINCT
A.userid,
FIRST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS First_Channel,
LAST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS Last_Channel
FROM raw_data.user_session_channel A
LEFT JOIN raw_data.session_timestamp B ON A.sessionid = B.sessionid
ORDER BY 1;2. Gross revenue가 가장 큰 사용자ID 10개 찾기
방법 (1) GROUP BY
SELECT
userID,
SUM(amount)
FROM raw_data.session_transaction st
LEFT JOIN raw_data.user_session_channel usc ON st.sessionid = usc.sessionid
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;방법 (2) SUM OVER
SELECT DISTINCT
usc.userid,
SUM(amount) OVER(PARTITION BY usc.userid)
FROM raw_data.user_session_channel AS usc
JOIN raw_data.session_transaction AS revenue ON revenue.sessionid = usc.sessionid
ORDER BY 2 DESC
LIMIT 10;3. 월별 NPS 계산하기
서비스에 대해 고객들에게 '주변에 추천하겠는가?' 라는 질문을 기반으로 고객 만족도를 0(의향 없음)에서 10(의향 아주 높음)까지 점수 매겼을 때, 점수에 따라 다음과 같이 나눈다.
- detractor(비추천자): 0에서 6점
- passive(소극자): 7이나 8점
- promoter(홍보자): 9나 10점
NPS는 promoter 비율(%) - detractor 비율(%)로 계산한다.
방법 (1)
SELECT month,
ROUND((promoters-detractors)::float/total_count*100, 2) AS overall_nps
FROM (
SELECT LEFT(created, 7) AS month,
COUNT(CASE WHEN score >= 9 THEN 1 END) AS promoters,
COUNT(CASE WHEN score <= 6 THEN 1 END) AS detractors,
COUNT(CASE WHEN score > 6 AND score < 9 THEN 1 END) AS passives,
COUNT(1) AS total_count
FROM raw_data.nps
GROUP BY 1
ORDER BY 1
);방법 (2)
SELECT LEFT(created, 7) AS month,
ROUND(SUM(CASE
WHEN score >= 9 THEN 1
WHEN score <= 6 THEN -1 END)::float*100/COUNT(1), 2) -- 분자를 한번에 구함
FROM raw_data.nps
GROUP BY 1
ORDER BY 1;트랜잭션 소개와 실습
-
트랜잭션이란?
Atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법
- 이는 DDL이나 DML 중 레코드를 수정/추가/삭제한 것에만 의미가 있음
- SELECT에는 트랜잭션을 사용할 이유 X
- BEGIN과 END 혹은 BEGIN과 COMMIT 사이에 해당 SQL들을 사용
- 만약 BEGIN 전의 상태로 돌아가고 싶다면 ROLLBACK 실행 -
예시: 은행 계좌 이체
- 계좌 이체는 인출과 입금의 두 과정으로 이뤄짐
- 만일 인출은 성공했는데, 입금이 실패한다면?
- 이 두 과정은 동시에 성공하던지 실패해야 한다(Atomic하다는 의미!)
- 이런 과정들을 트랜잭션으로 묶어주자(조회만 한다면 이는 트랜잭션으로 묶일 필요 없다)
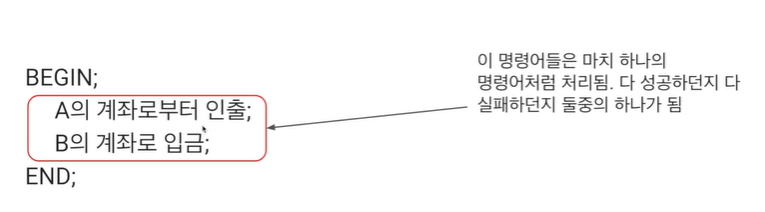
-
트랜잭션 커밋 모드: autocommit
- autocommit = True- 모든 레코드 수정/삭제/추가 작업이 기본적으로 바로 데이터베이스에 쓰여짐
- 이를 커밋된다고 함
- 만일 특정 작업을 트랜잭션으로 묶고 싶다면 BEGIN과 END(COMMIT)/ROLLBACK으로 처리
-
autocommit = False
- 모든 레코드 수정/삭제/추가 작업이 COMMIT 호출될 때까지 커밋되지 않음
- 모든 레코드 수정/삭제/추가 작업이 COMMIT 호출될 때까지 커밋되지 않음
-
Google Colab의 트랜잭션 방식
- 기본적으로 모든 SQL statement가 바로 커밋됨(autocommit = True)
- 이를 바꾸고 싶다면 BEGIN과 END(COMMIT)/ROLLBACK을 사용
-
psycopg2의 트랜잭션 방식
- autocommit이라는 파라미터로 조절가능
- autocommit = True가 되면 기본적으로 PostgreSQL의 커밋 모드와 동일
- autocommit = False가 되면 커넥션 객체의 .commit()과 .rollback()함수로 트랜잭션 조절 가능
DELETE FROM vs. TRUNCATE
- DELETE FROM table_name (not DELETE * FROM)
- 테이블에서 모든 레코드를 삭제
- WHERE 사용해 특정 레코드만 삭제 가능
DELETE FROM raw_data.user_session_channel WHERE channel = 'Google'
- TRUNCATE table_name
- 테이블에서 모든 레코드를 삭제
- DELETE FROM은 속도가 느림
- TRUNCATE가 전체 테이블의 내용 삭제 시에는 여러모로 유리하지만 두 가지 단점이 존재- TRUNCATE는 WHERE를 지원하지 않음
- TRUNCATE는 transaction을 지원하지 않음(rollback 불가능!)
기타 고급 문법 소개와 실습
UNION, EXCEPT, INTERSECT
-
UNION(합집합)
- 여러 개의 테이블들이나 SELECT 결과를 하나의 결과로 합쳐줌
- UNION vs. UNION ALL (UNION은 중복을 제거한 결과를 반환)
-
EXCEPT(MINUS)
- 하나의 SELECT 결과에서 다른 SELECT 결과를 빼주는 것이 가능 -
INTERSECT(교집합)
- 여러 개의 SELECT문에서 같은 레코드들만 찾아줌
COALESCE, NULLIF
-
COALESCE(Expression 1, Expression 2, ...)
- 첫번째 Expression 부터 값이 NULL이 아닌 것이 나오면 그 값을 리턴하고, 모두 NULL이면 NULL을 리턴
- NULL을 다른 값으로 바꾸고 싶을 때 사용 -
NULLIF(Expression 1, Expression 2)
- Expression 1과 Expression 2의 값이 같으면 NULL을 리턴
LISTAGG
GROUP BY에서 사용되는 Aggregate 함수 중 하나
- 사용자 ID별로 채널을 순서대로 리스트
SELECT userid, LISTAGG(channel, '->') WITHIN GROUP (ORDER BY ts) channels -- ts 순서대로 사용자별 채널을 리스트, 구분자 지정까지
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
GROUP BY 1
LIMIT 10;
WINDOW
- LAG 함수
- 어떤 사용자 세션에서 시간순으로 봤을 때- 앞 세션의 채널이 무엇인지 알고 싶다면?
- 혹은 다음 세션의 채널이 무엇인지 알고 싶다면?
-- 이전 채널 찾기
SELECT usc.*, st.ts,
LAG(channel, 1) OVER (PARTITION BY userId ORDER BY ts) prev_channel -- LAG(필드명, 1): 하나 앞의 레코드에서 값을 읽어와라
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp st ON usc.sessionid = st.sessionid
ORDER BY usc.userid, st.ts
LIMIT 100;JSON Parsing Functions
JSON 포맷을 이미 아는 상황에서만 사용가능하며, JSON String을 입력으로 받아 특정 필드의 값을 추출가능(nested 구조 지원)
- JSON_EXTRACT_PATH_TEXT

SELECT JSON_EXTRACT_PATH_TEXT('{"f2":{"f3": "1"},"f4":{"f5":"99","f6":"star"}}','f4', 'f6');