데이터 팀의 역할
-
데이터 팀의 Mission
신뢰할 수 있는 데이터를 바탕으로 부가가치 생성
- 데이터의 품질이 보장되어야! (garbage in garbage out)
- 많은 경우 데이터 분석은 회사의 주력 사업이 아니라 +알파로서 부가적인 가치를 생성해내는 일 -
데이터 팀의 목표 1
고품질의 데이터를 시기적절하게 제공하여 정책 결정에 사용
- 결정과학(Decision Science)
- 데이터 참고 결정(data informed decisions), 데이터 기반 결정(data driven decisions)을 가능하게 함 -
데이터 팀의 목표 2
고품질 데이터를 필요할 때 제공하여 사용자의 서비스 경험 개선
- 머신러닝과 같은 데이터 기반 알고리즘을 통해 개선
- 개인화를 바탕으로 한 추천과 검색 기능 제공
- 하지만 사람의 개입/도움이 반드시 필요(human-in-the-loop)
-
데이터 인프라
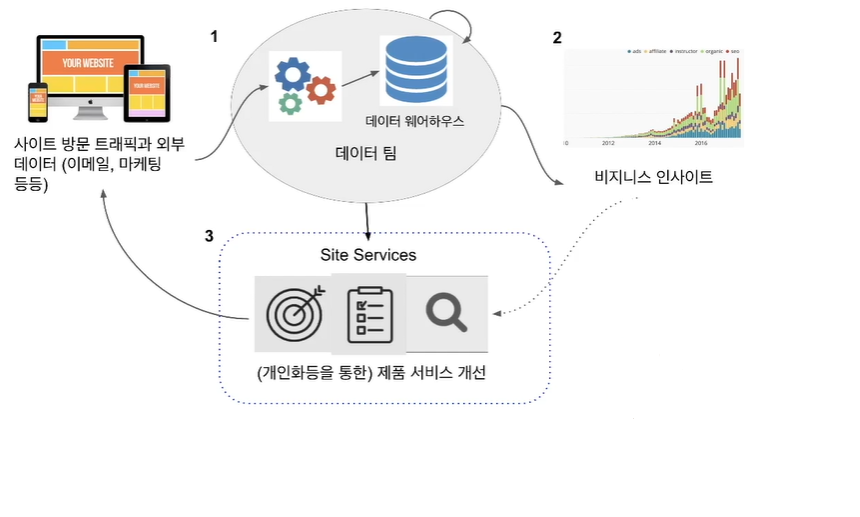
데이터 팀의 발전 과정
1. 데이터 인프라 구축
-
데이터 인프라: 데이터 웨어하우스와 ETL
- 데이터 웨어하우스: 회사에 필요한 모든 데이터를 저장하는 중앙 데이터베이스
- ETL(Extract, Transform, Load): 소스에 존재하는 데이터들을 데이터 웨어하우스로 적재하는 코드를 지칭
- 데이터 인프라의 구축은 데이터 엔지니어(Data Engineer)가 수행 -
데이터 웨어하우스란?
회사에 필요한 모든 데이터를 모아놓은 중앙 데이터베이스(SQL)
- 데이터의 크기에 맞게 어떤 데이터베이스를 사용할지 선택
- 중요 포인트는 프로덕션용 데이터베이스와 별개의 데이터베이스라는 점!
-
ETL(Extract, Transform, Load)
다른 곳에 존재하는 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업
- Extract: 외부 데이터 소스에서 데이터를 추출
- Transform: 데이터의 포맷을 원하는 형태로 변환
- Load: 변환된 데이터를 최종적으로 데이터 웨어하우스로 적재
- 가장 많이 쓰이는 프레임웍은 Airflow로 AWS와 구글 클라우드에서도 지원
2. 데이터 분석 수행
-
데이터 분석이란?
- 회사와 팀별 중요 지표(metrics)를 정의하고 대시보드 형태로 시각화(visualization)
- 중요 지표의 예: 매출액, 월간/주간 액티브 사용자 수 등
- 이외에도 데이터와 관련된 다양한 분석/리포팅 업무 수행
- 이는 데이터 분석가(Data Analyst)가 맡는 일 -
시각화 대시보드란?
- 보통 중요한 지표를 시간의 흐름과 함께 보여주는 것이 일반적
- 지표의 경우 3A(Accessible:쉽게 접근할 수 있어야 함, Actionable:지표를 보고 어떤 액션을 취해야 하는지 알 수 있어야 함, Auditable: 지표가 맞게 계산되고 있는 것인지 감사할 방법이 있어야 함)가 중요
- 가장 널리 사용되는 대시보드:- 구글 클라우드의 Looker
- 세일즈포스의 Tableau
- 마이크로소프트의 Power BI
- 오픈소스 아파치 Superset
3. 머신러닝/인공지능 적용
- 데이터 인프라에 저장된 데이터를 기반으로 지도기계학습을 통해 머신러닝 모델들을 개발하여 추천, 검색 등을 개인화하는 것이 일반적인 패턴
- 이는 데이터 과학자(Data Scientist)들이 하는 일
데이터 팀의 구성원
-
데이터 팀의 구성원
- 데이터 엔지니어: 데이터 인프라 구축
- 데이터 분석가: 데이터 웨어하우스의 데이터를 기반으로 지표를 만들고 시각화
- 데이터 과학자: 과거 데이터를 기반으로 미래를 예측하는 머신러닝 모델을 만들어 고객들의 서비스 경험 개선(개인화/자동화/최적화) -
데이터 엔지니어의 역할
기본적으로는 소프트웨어 엔지니어이며, 파이썬을 주로 사용하나 자바 혹은 스칼라와 같은 언어도 아는 것이 좋음
- 데이터 웨어하우스를 구축하고 이를 관리, 클라우드로 가는 것이 추세
- 관련해서 중요한 작업 중 하나는 ETL 코드를 작성하고 주기적으로 실행해주는 것
- 데이터 분석가, 과학자들과의 협업을 통해 필요한 툴이나 데이터를 제공해주는 것이 데이터 엔지니어의 중요한 역할 중 하나
-
데이터 분석가의 역할
비지니스 인텔리전스를 책임지고 중요 지표를 정의하여 이를 대시보드 형태로 시각화함
- 비지니스 도메인에 대한 깊은 지식이 필요
- 회사 내 임원들이나 팀 리드들의 데이터 관련 질문에 답을 하여 데이터 기반 결정을 내릴 수 있도록 도와줌
- 질문들이 굉장히 많고 반복적이므로 어떻게 셀프서비스로 만드냐가 관건 -
데이터 분석가의 딜레마
- 보통 많은 수의 긴급한 데이터 관련 질문들에 시달림
- 많은 경우 현업팀에 소속되기도 하여 소속감이 불분명하고 고과 기준이 불명확하여 커리어 관련 불안감이 있을 수 있음
Data Scientist?
-
데이터 과학자의 역할
머신러닝의 형태로 사용자들의 경험을 개선
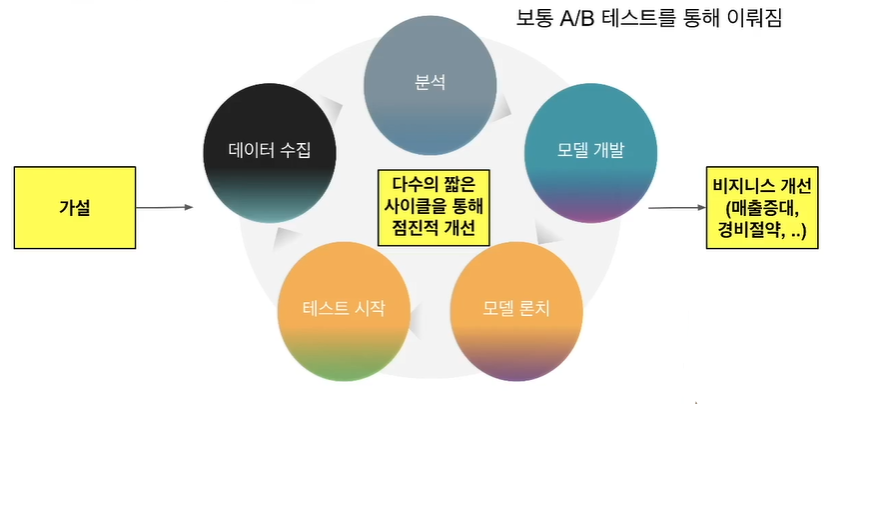
- 문제에 맞춰 가설을 세우고 데이터를 수집한 후에 예측 모델을 만들고 이를 테스트
- 장시간이 필요하지만 이를 짧은 사이클로 단순하게 시작해서 고도화하는 것이 좋음
- 가능하면 A/B 테스트를 수행하는 것이 더 좋음
- 데이터 과학자에게 필요한 스킬셋- 머신러닝/인공지능에 대한 깊은 지식과 경험
- 파이썬과 SQL
- 통계 지식, 수학 지식
- 끈기와 열정
-
훌륭한 데이터 과학자란?
- 열정과 끈기
- 다양한 경험
- 코딩 능력
- 현실적인 접근 방법: 애자일 기반의 모델링, 딥러닝이 모든 문제의 해답은 아님을 명심
- 과학적인 접근 방법: 지표기반 접근, 내가 만드는 모델의 목표는 무엇이고 성과를 어떻게 측정할 것인가? -
머신러닝 모델링 사이클: AGILE
-
A/B 테스트란?
- 온라인 서비스에서 새 기능의 임팩트를 객관적으로 측정하는 방법
- 새로운 기능을 론치함으로서 생기는 위험부담을 줄이는 방법
- 100%의 사용자에게 론치하는 것이 아니라 작게 시작하고 관찰 후 결정: 먼저 5%의 사용자에게만 론치하고 나머지 95% 사용자와 매출액과 같은 중요 지표를 가지고 비교하여 별 문제가 없으면(지표가 하락하지 않았으면) 점진적으로 늘려서 최종적으로 100%로 론치
- 보통 사용자들을 2개의 그룹(한 그룹은 기존 기능에 그대로 노출;control, 다른 그룹은 새로운 기능에 노출; test)으로 나누고 시간을 두고 관련 지표를 비교
- 가설과 영향받는 지표를 미리 정하고 시작하는 것이 일반적이며, 지표의 경우 성공/실패 기준까지 생각해보는 것이 필요
데이터 팀의 조직구조
현업에서 데이터 팀은 어떻게 다른 팀들과 협업하는가?
-
중앙집중 구조: 모든 데이터 팀원들이 하나의 팀을 존재
- 일의 우선 순위는 중앙 데이터팀이 최종 결정
- 데이터 팀원들 간의 지식과 경험으 공유가 쉬워지고 커리어 경로가 더 잘 보임
- 하지만 현업부서들의 만족도는 상대적으로 떨어짐 -
분산 구조: 데이터 팀이 현업 부서별로 존재
- 일의 우선 순위는 각 팀별로 결정
- 데이터 일을 하는 사람들 간의 지식/경험의 공유가 힘들고 데이터 인프라나 데이터의 공유가 힘들어짐
- 현업 부서들의 만족도는 처음에는 좋지만 많은 수의 데이터 팀원들이 회사를 그만두게 됨
-
중앙집중과 분산 구조의 하이브리드 모델
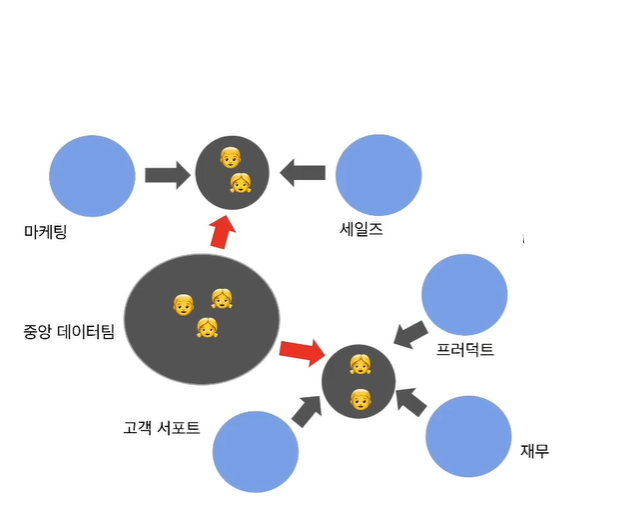
- 가장 이상적인 조직 구조
- 데이터 팀원들은 일부는 중앙에서 인프라적인 일을 수행하고 일부는 현업팀에서 파견식으로 일하되 주기적으로 일을 변경
- 데이터팀 안에서 커리어 경로가 만들어짐
모델 개발 시 고려할 점
데이터 엔지니어와 데이터 과학자 간 마찰이 생기는 지점 - 개발된 모델의 이양 관련
-
꼭 기억할 포인트(1)
누군가 모델 개발부터 최종 론치까지 책임질 사람이 필요하다! 모델 개발은 시작일 뿐이고 성공적인 프로덕션 론치가 최종적인 목표이다. 최종 론치하는 엔지니어들과 소통하는 것이 중요하다.모델 개발 초기부터 개발/론치 과정을 구체화하고 소통해야 한다.
- 모델 개발 시 모델을 어떻게 검증할 것인지?
- 모델을 어떤 형태로 엔지니어들에게 넘길 것인지?
- feature 계산을 어떻게 하는지, 모델 자체는 어떤 포맷인지?
- 모델을 프로덕션에서 A/B 테스트할 것인지, 한다면 최종 성공 판단 지표가 무엇인지? -
꼭 기억할 포인트(2)
개발된 모델이 바로 프로덕션에 론치 가능하도록 통일된 프로세스 혹은 프레임웍이 필요하다.
- 모델 개발 툴을 하나로 통일하면 제반 개발과 론치 관련 프레임웍의 개발이 쉬워짐
- AWS의 SageMaker: 머신러닝 모델 개발/검증/론치 프레임웍으로, 검증된 모델을 버튼 클릭 하나로 API 형태로 론치 가능하다. 구글 클라우드와 Azure도 비슷한 프레임웍을 지원한다. -
꼭 기억할 포인트(3)
첫 모델 론치는 시작일 뿐이다. 론치가 아닌 운영을 통해 점진적인 개선을 이뤄내는 것이 중요하다. 결국 피드백 루프가 필요한 것.
- 운영에서 생기는 데이터를 가지고 개선점 찾기
- 검색이라면 CTR(Click Through Rate)을 모니터링하고 모든 데이터를 기록
- 주기적으로 모델을 재빌딩
- 온라인 러닝(리얼타임 머신러닝): 모델이 프로덕션에서 사용되면서 계속적으로 업데이트 되는 방식의 머신러닝
데이터 일 관련 교훈
1. 데이터를 통해 매출이 생겨야 한다.
어느 조직이건 회사에서의 존재 이유는 매출 창조 혹은 경비 절감이다. 데이터 팀 또한 직접적이건 간접적이건 데이터를 통해 회사 수익에 긍정적인 영향을 끼쳐야 한다. 데이터 조직의 수장의 역할이 아주 중요한데, 다시 한 번 데이터 인프라의 구성이 첫 번째라는 점을 명심하되 단기적을 좋은 결과를 낼 방법을 찾아야 한다.
2. 데이터 인프라가 첫 번째 스탭!
데이터 인프라 없이는 데이터 분석이나 모델링은 불가능하다. 클라우드 기반으로 구축할 것인지, 직접 구축할 것인지, 배치 방식으로 주기적으로 데이터 웨어하우스에 ETL할 것인지, 실시간으로 처리할 것인지 등을 고려해야 한다.
3. 데이터의 품질이 아주 중요하다. Garbage In Garbage Out
데이터 과학자가 가장 많은 시간을 쏟는 분야는 데이터 청소 작업이다. 모델링에 드는 시간을 100이라고 하면, 그중 70은 데이터 클린업에 소요된다.
특히 중요 데이터의 경우 좀 더 품질 유지에 노력이 필요하다. 어디에 데이터가 있는지, 이 데이터의 품질에 혹시 문제가 있는지 계속적으로 모니터링하자.
4. 항상 지표부터 생각한다.
무슨 일을 하건 그 일의 성공 척도(지표)를 처음부터 생각하고, 나름대로 가설을 세우는 것이 인사이트를 키우는데 큰 도움이 된다. 지표의 계산에 있어서는 객관성이 매우 중요하다. 계산된 지표를 아무도 못 믿는다면 올바른 지표가 아닐 것이며, 지표를 어떻게 계산할 것인지 그리고 이걸 다른 사람들에게 어떻게 설명할지 고려해야 한다.
5. 가능하면 간단한 솔루션으로 시작하라.
DONE IS BETTER THAN PERFECT
모든 문제를 딥러닝으로 해결해야 하는 것은 아니다. 실제 회사에서 딥러닝으로 문제를 해결하는 경우는 드물며, 딥러닝은 왜 동작하는지 설명하기도 힘들고 개발과 론치 모두 시간이 걸린다.
한 큐에 완벽한 모델을 만드려고 하지 마라. 반복 기반의 점진적인 개발방식으로 개선하면서 원하는 결과가 나오면 그 때 중단하면 된다.
