빅데이터 기술이란?
빅데이터 정의와 예
빅데이터란 무엇이며 어떤 예들이 있는가?
빅데이터의 정의 1. "서버 한 대로 처리할 수 없는 규모의 데이터" (분산 환경이 필요하느냐에 포커스)
빅데이터의 정의 2. "기존의 소프트웨어(MySql과 같은 관계형 DB)로는 처리할 수 없는 규모의 데이터"
빅데이터의 정의 3. 4V: Volume(데이터 크기가 대용량?), Velocity(데이터의 처리 속도가 중요?), Variety(구조화/비구조화 데이터 둘 다?), Varecity(데이터의 품질이 좋은지?)
Hardoop의 등장과 소개
-
대용량 처리 기술이란?
- 분산 환경 기반(1대 혹은 그 이상의 서버로 구성): 분산 컴퓨팅과 분산 파일 시스템이 필요
- Fault Tolerance: 소수의 서버가 고장나도 동작해야함
- 확장이 용이해야함: Scale Out이라고 부름 -
하둡(Hardoop)의 등장
- Doug Cutting이 구글랩 발표 논문들에 기반해 만든 오픈소스 프로젝트
- 처음 시작은 Nutch라는 오픈소스 검색엔진의 하부 프로젝트였으나, 이후 아파치 톱레벨 별개 프로젝트로 분리됨
- 크게 두 개의 서브 시스템으로 구성- 분산 파일 시스템인 HDFS
- 분산 컴퓨팅 시스템인 MapReduce: 새로운 프로그래밍 방식으로 대용량 데이터 처리의 효율을 극대화하는데 맞춤
-
MapReduce 프로그래밍의 문제점
- 작업에 따라서는 MapReduce 프로그래밍이 너무 복잡해짐
- 결국 Hive(SQL on Hadoop)처럼 MapReduce로 구현된 SQL 언어들이 다시 각광을 받게 됨
- 또한 MapReduce는 기본적으로 배치 작업에 최적화되어 있음 (not realtime)
-
MapReduce 프로그래밍 예제: Word Count
리듀스는 맵(key-value)의 같은 key들을 묶어주는 것이 보장됨
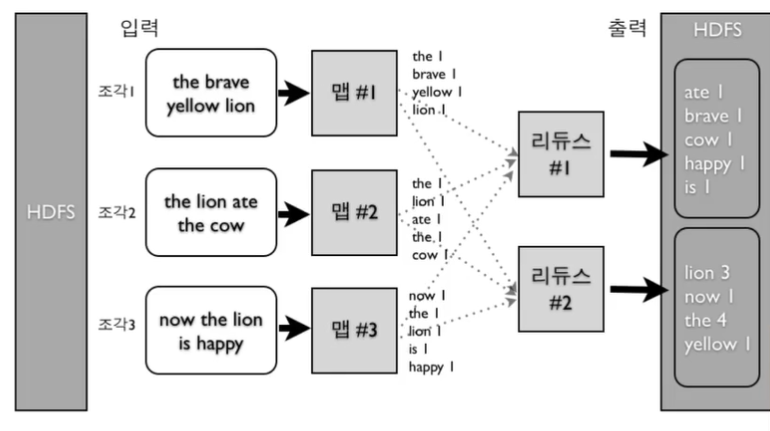
-
Hadoop의 발전
- 하둡 1.0: HDFS위에 MapReduce라는 분산 컴퓨팅 시스템이 도는 구조
- 하둡 2.0에서 아키텍처가 크게 변경됨
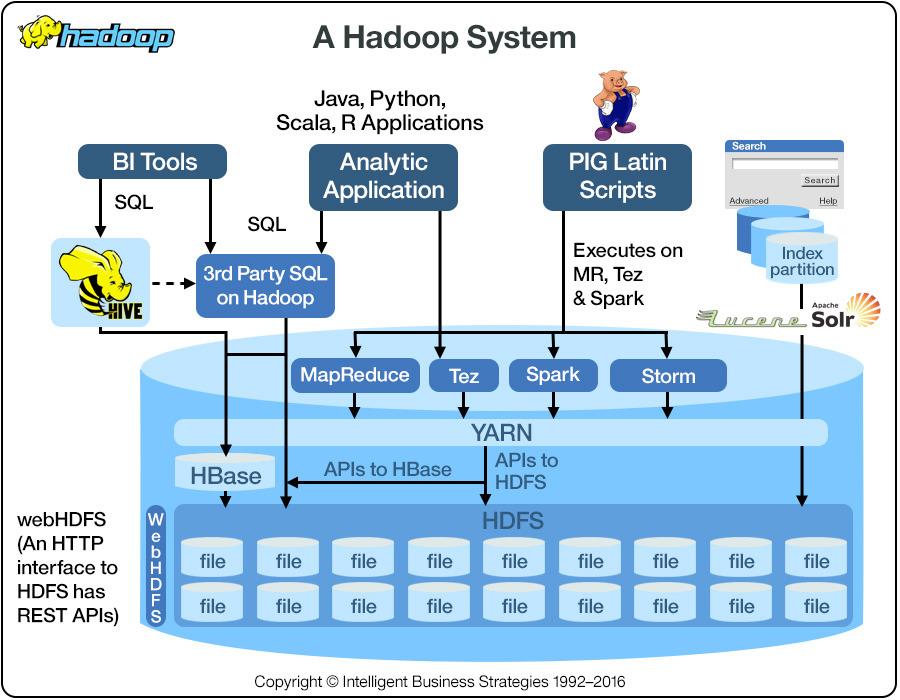
- 하둡은 기반 분산처리 시스템이 되고 그 위에 애플리케이션 레이어가 올라가는 구조
- YARN은 하둡 2.0에서의 분산 컴퓨팅 시스템 이름
- Spark는 하둡 2.0위에서 애플리케이션 레이어로 실행됨
- 손쉬운 개발을 위한 로컬 모드도 지원
-
HDFS: 분산 파일 시스템

- 데이터를 블록단위(크기는 128MB가 디폴트)로 저장
- 블록 복제 방식(Replication): 각 블록은 기본적으로 3개 서버에 중복 저장되어 Fault tolerance를 보장할 수 있는 방식
-
분산 컴퓨팅 시스템
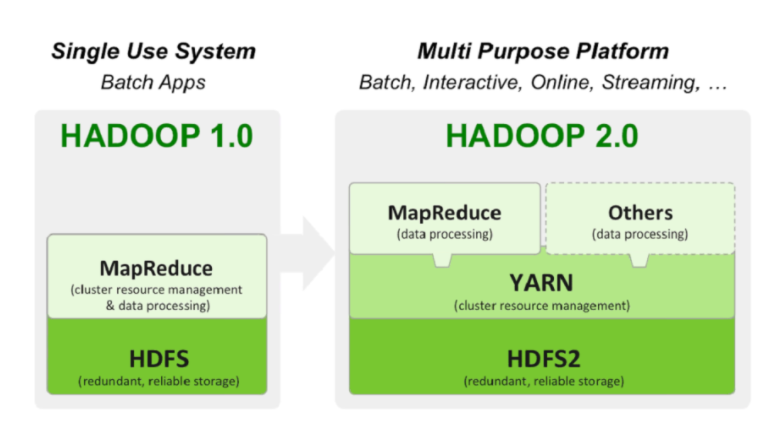
- 하둡 1.0 = MapReduce: 하나의 잡 트래커와 다수의 태스크 트래커로 구성되어 잡 트래커가 일을 나눠서 다수의 태스크 트래커에게 분배
- 하둡 2.0: 클라이언트, 리소스 매니저, 노드 매니저, 컨테이너로 역할을 세분화 함. Spark 지원, 분산 컴퓨팅 시스템을 만들 수 있는 프레임웍의 개념이 됨
Spark 소개
-
Spark의 등장
- 버클리 대학의 AMPLab에서 아파치 오픈소스 프로젝트로 2013년 시작
- 하둡의 뒤를 잇는 2세대 빅데이터 기술로, 하둡 2.0을 분산환경으로 사용
- Scala로 작성됨
- Pandas와 굉장히 흡사(서버 한 대 버전 vs. 다수 서버 분산환경 버전) -
Spark vs. MapReduce
- Spark는 기본적으로 메모리 기반으로, 메모리가 부족해지면 디스크 사용. MapReduce는 디스크 기반
- MapReduce는 하둡 위에서만 동작, Spark는 하둡(YARN)외에도 자체 분산환경 등 다른 분산 컴퓨팅 환경 지원
- MapReduce는 key, value기반 프로그래밍, Spark는 판다스와 개념적으로 흡사
- Spark는 다양한 방식의 컴퓨팅(배치 프로그래밍, 스트리밍 프로그래밍, SQL, 머신러닝, 그래프 분석) 지원 -
Spark의 구조
- 드라이버 프로그램의 존재
- 하둡 2.0위에 올라가는 애플리케이션
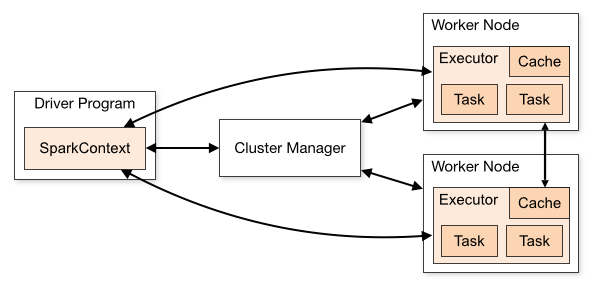
-
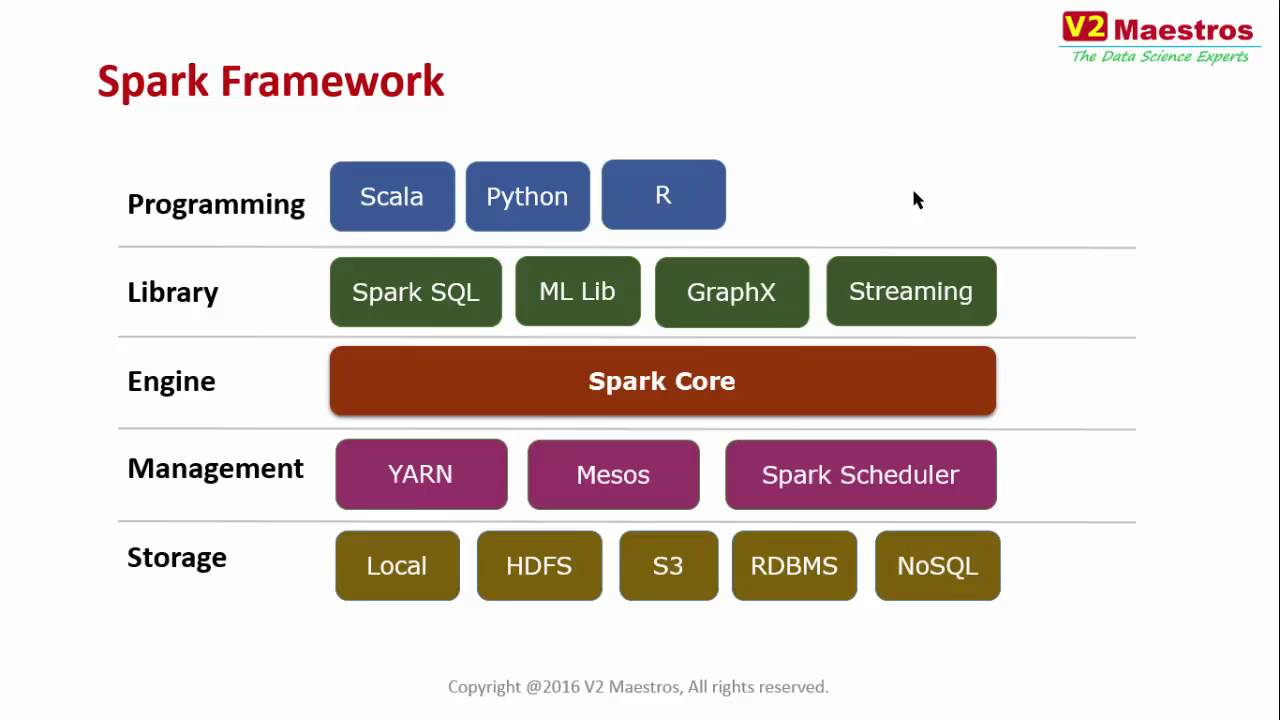
Spark 3.0의 구성
- Spark Core
- SparkSQL
- SparkStreaming
- MLlib(Spark.ML)
- SparkGraph
Spark 데이터프레임, 데이터셋, RDD
- Spark 세션
- Spark 프로그램의 시작은 SparkSession을 만드는 것
- Spark 세션을 통해 Spark이 제공해주는 다양한 기능을 사용: Spark 컨텍스트, Hive 컨텍스트, SQL 컨텍스트
# RDD 만드는 예제
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark create RDD example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
sc = spark.sparkContext
# spark와 sc를 이용해 뒤에서 배울 RDD와 데이터프레임을 조작하게 됨- Spark의 RDD(Resilient Distributed Dataset)
- 로우레벨 데이터로 클러스터 내의 서버에 분산된 데이터를 지칭
- 레코드별로 존재하고 구조화된 데이터/비구조화된 데이터 모두 지원
- Spark의 Dataframe과 Dataset
- RDD위에 만들어지는 하이레벨 데이터로 RDD와는 달리 필드 정보를 가짐.
- Dataset은 Dataframe과는 달리 타입 정보가 존재하며 컴파일 언어(Scala/Java)에서 사용 가능.
- PySpark에서는 Dataframe을 사용(SparkSQL을 사용하는 것이 더 일반적)
RDD
변경이 불가능한 분산 저장된 데이터로, 다수의 파티션으로 구성되고 Spark 클러스터 내 서버들에 나눠(cpu 수 만큼 partition으로 나뉘어) 저장된다. 로우레벨의 함수형 변환(map, filter, flatMap 등)을 지원한다. RDD가 아닌 일반 파이썬 데이터는 parallelize 함수로 RDD로 변환해주어야 한다.

데이터프레임
RDD처럼 데이터프레임도 변경이 불가능한 분산 저장된 데이터지만, RDD와는 다르게 관계형 DB 테이블처럼 컬럼으로 나눠 저장한다. 이는 판다스의 데이터프레임과 거의 흡사하다. Hive, 외부 DB, RDD 등의 다양한 데이터소스를 지원하고 Scala, Java, R, Python 언어를 지원한다.
# postgresql에서 테이블을 읽어 Spark 클러스터 내의 데이터프레임으로 만들기
df = spark.read.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:5432/databasename") \
.option("dbtable", "tablename") \
.option("user", "username") \
.option("password", "password") \
.option("driver", "org.postgresql.Driver") \
.load()
df.printSchema()- 데이터프레임 생성 방법
- RDD를 변환해서 생성: RDD의 toDF 함수 사용
- SQL 쿼리를 기반으로 생성(위의 예시)
- 외부 데이터를 로딩하여 생성: createDataFrame
데이터셋
Spark 1.6부터 추가된 새로운 데이터 타입으로, RDD와 SparkSQL의 최적화 엔진 두 가지 장점을 취했다. 데이터셋은 타입이 있는 컴파일 언어(스칼라, 자바)에서만 사용 가능하여 파이썬에서는 사용 불가능하다.
Spark 개발 환경
-
개인 컴퓨터에 설치하고 사용하는 방법
간편하기는 하지만 노트북 등을 설치하려면 복잡해진다. 아니면 spark-submit을 이용해 실행가능하다. -
각종 무료 노트북을 사용하는 방법
구글 Colab을 이용하거나, 데이터브릭의 커뮤니티 노트북을 사용하거나, 제플린의 무료 노트북을 사용할 수 있다. -
AWS의 EMR 클러스터 사용
이미지 출처
- 분산 파일 시스템: https://www.google.com/imgres?imgurl=http%3A%2F%2Fwww.corejavaguru.com%2Fassets%2Fimages%2Fcontent%2Fhdfs-data-flow-read.png&imgrefurl=https%3A%2F%2Fwikidocs.net%2F23582&tbnid=A3cWEz9eRn9tRM&vet=12ahUKEwi8g-SnvfDxAhUIXpQKHUGNA7EQMygOegUIARDHAQ..i&docid=ILjFwu5DQQdLPM&w=500&h=297&q=hdfs&ved=2ahUKEwi8g-SnvfDxAhUIXpQKHUGNA7EQMygOegUIARDHAQ
- 분산 컴퓨팅 시스템: https://bigdataanalyticsnews.com/hadoop-2-0-yarn-architecture/
- Spark의 구조: https://images.velog.io/images/dhelee/post/e623d616-c2f5-451e-a428-6e66d5dae6f0/image.png
{kind=link}
{kind=link}
