Spark MLlib 모델 튜닝 소개
-
Spark MLlib 모델 튜닝
- 최적의 모델 혹은 모델의 파라미터를 찾는 것이 아주 중요
- 하나씩 테스트 해보는 것 vs. 다수를 동시에 테스트하는 것
- 모델 선택의 중요한 부분은 테스트 방법
- 교차 검증(Cross Validation)과 홀드 아웃(Train-Validation Split) 테스트 방법을 지원
- 보통 ML Pipeline과 같이 사용함 -
Spark MLlib 모델 테스트 방법
- 훈련/테스트셋 나누기(=홀드아웃 테스트, Train-validation split):TrainValidationSplit
- 교차 검증(=K-Fold 테스트, Cross Validation):CrossValidator- 트레이닝 셋을 K개의 서브셋으로 나눠 총 K번의 훈련을 반복
- i번째 훈련을 할 때는 i번째 서브셋을 빼고 훈련을 해서 모델 빌딩한 후, 만들어진 모델의 테스트는 i번째 서브셋으로 수행하는 방식
- 각 훈련에서 얻은 K개 평가 지표의 평균값을 계산
- 홀드아웃 테스트보다 훨씬 안정적이며 오버피팅 문제가 감소
-
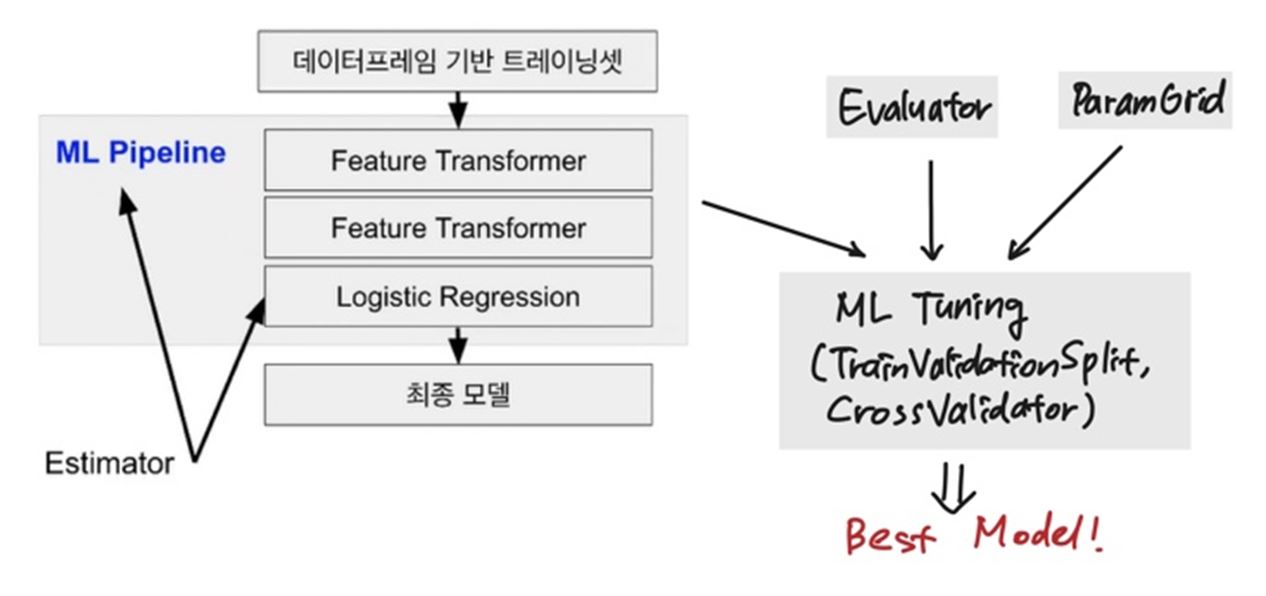
Spark MLlib 모델 튜닝 방법
- 모델 테스트 방법(TrainValidationSplit or CrossValidator)을 선택한 후
- 다음과 같은 입력을 기반으로 가장 좋은 파라미터를 찾아줌
- Estimator: 머신러닝 모델 혹은 모델 빌딩 파이프라인(ML Pipeline)
- Evaluator: 머신러닝 모델의 성능 측정에 사용되는 지표(metrics)
- Parameter: 훈련 반복 횟수 등의 하이퍼 파라미터
- ParamGridBuilder를 이용해 ParamGrid 타입의 변수 생성
- 최종적으로 가장 결과가 좋은 모델을 리턴! -
Spark MLlib 모델 성능 측정: Evaluator
-evaluate함수를 가지며, 인자로 테스트셋 예측 결과가 포함된 데이터프레임과 파라미터(성능지표)를 넘겨주어야 함
- 입력으로는 Prediction 컬럼과 레이블 컬럼이 들어있는 데이터프레임을 받음
- LogisticRegression의 경우, probability 컬럼도 들어옴
- 보통 이 데이터프레임은 머신러닝 모델의 transform 함수가 리턴해준 값이 됨
- 또한 어떻게 성능을 측정할 것인지 성능지표를 지정해주어야 함
-
ML 모델 빌딩 전체 프로세스
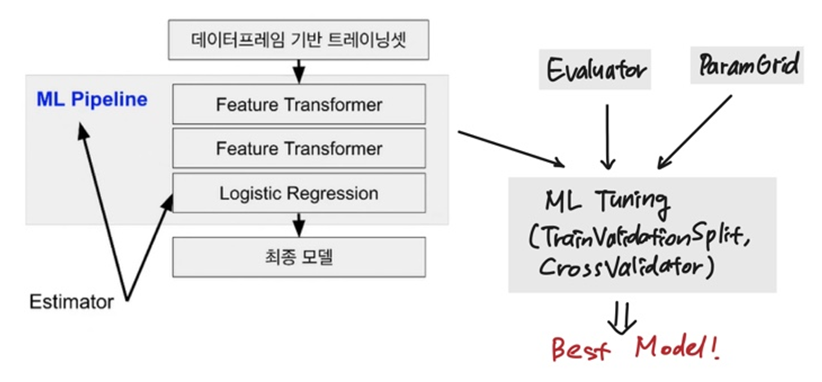
ML Pipeline 기반 머신러닝 모델 만들기
-
타이타닉 승객 생존 예측 분류기 개발 방향
- ML Pipeline을 사용하여 모델 빌딩
- 다양한 Transformer 사용: Imputer, StringIndexer, VectorAssembler
- MinMaxScaler를 적용하여 피쳐 값을 0과 1 사이로 스케일링
- Gradient Boosted Tree Classifier와 Logistic Regression을 머신러닝 알고리즘으로 사용
- CrossValidation을 사용하여 모델 파라미터 선택
- BinaryClassificationEvaluator를 Evaluator로 사용
- ParamGridBuilder를 사용하여 ParamGrid를 생성
- ML Pipeline을 ML Tuning 개체로 지정해서 여러 하이퍼 파라미터를 테스트해보고 가장 결과가 좋은 모델을 선택 -
MinMaxScaler의 사용
- 기본적으로 VectorAssembler로 벡터로 변환된 피쳐컬럼에 적용
from pyspark.ml.feature import MinMaxScaler
age_scaler = MinMaxScaler(inputCol="features", outputCol="features_scaled")
age_scaler_model = age_scaler.fit(data_vec)
data_vec = age_scaler_model.transform(data_vec)ML Pipeline 사용 예
- 필요한 Transformer와 Estimator들을 만들고 순서대로 리스트에 추가
from pyspark.ml.feature import Imputer, StringIndexer, VectorAssembler, MinMaxScaler
# Gender
stringIndexer = StringIndexer(inputCol = "Gender", outputCol = 'GenderIndexed')
# Age
imputer = Imputer(strategy='mean', inputCols=['Age'], outputCols=['AgeImputed'])
# Vectorize
inputCols = ['Pclass', 'SibSp', 'Parch', 'Fare', 'AgeImputed', 'GenderIndexed']
assembler = VectorAssembler(inputCols=inputCols, outputCol="features")
# MinMaxScaler
minmax_scaler = MinMaxScaler(inputCol="features", outputCol="features_scaled")
stages = [stringIndexer, imputer, assembler, minmax_scaler]
from pyspark.ml.classification import LogisticRegression
algo = LogisticRegression(featuresCol="features_scaled", labelCol="Survived")
lr_stages = stages + [algo]- 앞서 만든 리스트를 Pipeline의 인자로 지정!
from pyspark.ml import Pipeline
pipeline = Pipeline(stages = lr_stages)- 이를 사용해 바로 모델 빌드를 하고 싶다면
df = data.select(['Survived', 'Pclass', 'Gender', 'Age', 'SibSp', 'Parch', 'Fare'])
train, test = df.randomSplit([0.7, 0.3])
lr_model = pipeline.fit(train)
lr_cv_predictions = lr_model.transform(test)
evaluator.evaluate(lr_cv_predictions)- ML Tuning 사용 절차
- 테스트하고 싶은 머신러닝 알고리즘 개체 생성(혹은 ML Pipeline)
- ParamGrid를 만들어 테스트하고 싶은 하이퍼 파라미터 지정
- CrossValidator 혹은 TrainValidationSplit 생성
- fit 함수 호출해서 최선의 모델 선택
ML Tuning 사용 예
- ParamGrid와 CrossValidator 생성
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
paramGrid = (ParamGridBuilder()
.addGrid(algo.maxIter, [1, 5, 10])
.build())
cv = CrossValidator(
estimator=pipeline,
estimatorParamMaps=paramGrid,
evaluator=evaluator, # 앞서 생성한
numFolds=5)- CrossValidator 실행하여 최선의 모델을 선택하고 테스트셋으로 검증
# 교차 분석 수행! 가장 좋은 모델이 리턴됨
cvModel = cv.fit(train)
# 이 모델에 테스트셋을 입력으로 주고, 결과를 받아 결과 분석!
lr_cv_predictions = cvModel.transform(test)
evaluator.evaluate(lr_cv_predictions)- 어느 하이퍼 파라미터 조합이 최선의 결과를 냈는지 알고 싶다면?
- ML Tuning의 getEstimatorParamMaps/getEvaluator의 조합으로 파악
범용 머신러닝 모델 파일포맷: PMML
-
PMML: Predictive Model Markup Language
- 머신러닝 모델을 마크업 언어로 표현해주는 XML 언어
- 간단한 입력 데이터 전처리와 후처리도 지원하나 아직도 제약사항이 많음
- PySpark에서는 pyspark2pmml을 사용- 하지만 내부적으로는 jpmml-sparkml이라는 자바 jar 파일을 사용
- 너무 복잡하고 버전 의존도도 복잡
-
전체적인 절차
1. ML Pipeline을 PMML 파일로 저장
2. PMML 파일을 기반으로 모델 예측 API로 론치
3. 이 API로 승객정보를 보내고 예측 결과를 받는 클라이언트 코드 작성
