[강의 자료]
- Speech and Language Processing (https://web.stanford.edu/~jurafsky/slp3/)
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow(2nd Edition)
자연어 처리란, 자연어의 의미를 컴퓨터로 분석해서 특정 작업을 위해 사용할 수 있도록 하는 것이다. 응용분야로는 기계번역, 감성분석, 문서분류, 질의응답시스템, 챗봇, 언어생성, 음성인식, 추천시스템 등이 있다. 자연어 처리를 위한 텍스트 전처리 방법들, 특히 Tokenization에 대해 알아본다.
텍스트 전처리
단어(Word)
텍스트 전처리 시 다음과 같은 고려사항이 있을 수 있다.
-
문장부호를 단어에 포함시켜야 할까?
- 상황에 따라 다르지만, 포함시킨다면 phase의 경계를 뚜렷하게 보여주는 역할을 할 수 있음
-
(구어제 문장에서) Fragments, filled pauses는 어떻게 처리할까?
- 화자를 인식하는 task에서는 유용하게 사용할 수 있음
- 음성을 정제된 텍스트로 변환해야 하는 작업에서는 제거하는 것이 좋음 -
"Seuss's cat in the hat is different from other cats!"
- 표제어(lemma): 여러 단어들이 공유하는 뿌리 단어
- 단어형태(wordform): 같은 표제어를 공유하지만 다양한 형태를 가질 수 있음
- cat과 cats: 두 가지의 형태를 가지고 있지만 동일한 표제어 cat을 공유
자연어 처리에서 사용되는 용어를 살펴보자.
- Vocabulary: 단어의 집합(중복 없음)
- Type: Vocabulary의 한 원소
- Token: 문장 내에 나타나는 한 단어(an instance of a type in running text)
예를 들어, "They picnicked by the pool, then lay back on the grass and looked at the stars."이라는 문장은 16 tokens와 14 types를 가진다.
말뭉치(Corpus)
하나의 말뭉치는 일반적으로 대용량의 문서들의 집합이다. 말뭉치의 특성은 다음과 같은 요소들에 따라 달라지게 된다.
- 언어
- 방언
- 장르(뉴스, 소설, 과학기술문서, 위키피디아, 종교문서 등등)
- 글쓴이의 인구통계적 속성(나이, 성별, 인종 등)
다양한 말뭉치에 적용할 수 있는 NLP 알고리즘이 바람직한 알고리즘이다.
토큰화(Tokenization)
토큰화는 텍스트 정규화 방법 중 하나로, 모든 자연어 처리는 텍스트 정규화를 필요로 한다. 이외에도 단어정규화(normalizing word formats), 문장분절화(segmenting sentences) 등의 텍스트 정규화가 있다.
Unix 명령으로 간단하게 토큰화하기
-
텍스트 파일 안에 있는 단어들 토큰화
-tr -sc 'A-Za-z' '\n' < hamlet.txt
- 영문자가 아닌 모든 문자를 '/n'으로 replace하고 중복을 제거(squeeze) -
빈도수로 정렬
-tr -sc 'A-Za-z' '\n' < hamlet.txt | sort | uniq-c | sort -n -r
-
소문자로 변환해서 정렬
-tr 'A-Z' 'a-z' < hamlet.txt | tr -sc 'a-z' '\n' | sort | uniq-c | sort -n -r

-
문제점들...
- 문장부호들을 항상 무시할 수는 없음(ex. 단위, 날짜, URLs, hashtags, 이메일주소)
- 문장부호가 단어의 의미를 명확하게 하는 경우는 제외시키지 않는 것이 좋음
- 접어(clitics): 다른 단어에 붙어서 존재하는 형태(ex. we're)
- 여러 개의 단어가 붙어있어야 의미가 있는 경우(ex. New York)
Subword Tokenization
한국어의 경우 토큰화가 복잡하다. 띄어쓰기가 잘 지켜지지 않고, 띄어쓰기가 제대로 되었더라도 한 어절에 하나 이상의 의미 단위들이 있을 수 있기 때문이다. 뜻을 가진 가장 작은 말의 단위를 '형태소'라고 한다.
- 자립형태소: 명사, 대명사, 부사 등
- 의존형태소: 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사 등
즉, 단어보다 작은 단위(subword)로 토큰화가 필요하다.
-
만약 학습데이터에서 보지 못했던 새로운 단어가 나타난다면?
- 학습데이터: low, new, newer
- 테스트데이터: lower
- -er, -est 등과 같은 형태소를 분리할 수 있으면 좋을 것이다 -
Subword Tokenization Algorithms
- Byte-Pair Encoding(BPE)
- WordPiece
- Unigram language modeling
-
Subword Tokenization의 두 가지 구성요소
- Token learner: 말뭉치에서 vocabulary(token들의 집합)을 만들어 냄
- Token segmenter: 새로운 문장을 토큰화 함
Byte Pair Encoding
Subword Tokenization Algorithm 중 하나인 BPE에 대해 살펴보자.
우선, Token learner의 동작 방식은 다음과 같다.

예제 말뭉치 "low low low low low lowest lowest lowest newer newer newer newer newer newer wider wider wider new new"에 적용해본다.
-
Vocabulary를 단일 문자들의 집합으로 초기화한다.
- 단어의 끝을 나타내는 특수기호 '_'를 단어 뒤에 추가하고, 각 단어를 문자 단위로 쪼갠다.

- 단어의 끝을 나타내는 특수기호 '_'를 단어 뒤에 추가하고, 각 단어를 문자 단위로 쪼갠다.
-
다음을 반복한다.
- 말뭉치에서 연속적으로 가장 많이 발생하는 두 개의 기호들을 찾는다.
- 두 기호들을 병합하고, 새로운 기호로 vocabulary에 추가한다. (주의할 것은, 기호 병합은 단어 안에서만 이루어진다.)
- 말뭉치에서 그 두 기호들을 병합된 기호로 모두 교체한다.



-
위 과정을 k번의 병합이 일어날 때까지 반복한다.

Token learner의 학습이 끝난 후, 새로운 문장이 주어졌을 때 Token segmenter는 어떻게 토큰화를 할까? Greedy한 방법으로, 병합을 학습한 순서 그대로 적용하게 된다. 자주 나타나는 단어는 하나의 토큰으로 병합될 가능성이 높고 드문 단어는 subword 토큰들로 분할될 가능성이 높다.
예를 들어, "n e w e r _"는 하나의 토큰 "newer_"로 토큰화 되고 "l o w e r _"는 두 개의 토큰들 "low er_"로 토큰화 된다.
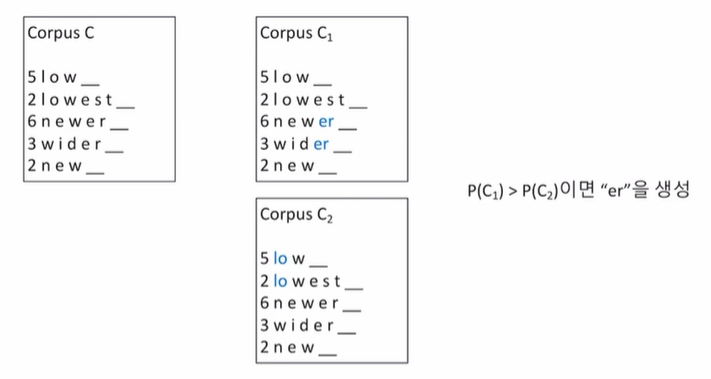
WordPiece
또 다른 Subword Tokenization Algorithm인 WordPiece는 기호들의 쌍을 찾을 때 빈도수 대신에 likelihood를 최대화시키는 쌍을 찾는다. 여러 개의 기호 pair 중 병합시킬 pair를 고를 때 likelihood가 기준이 되는 것이다. 확률은 언어모델을 이용하여 구한다.
Unigram
Unigram 방법은 다음과 같이 tokenization을 진행한다.
- 확률모델(언어모델)을 사용한다.
- 학습데이터 내의 문장을 관측(observed) 확률변수로 정의한다.
- Tokenization을 잠재(latent) 확률변수로 정의한다.
- 연속적인(sequential) 변수 - 데이터의 주변 우도(marginal likelihood)를 최대화시키는 tokenization을 구한다.
- EM(Expectation Maximization)을 사용
- Maximization step에서 Viterbo 알고리즘을 사용(wordpiece는 greedy하게 likelihood를 향상)
단어정규화
단어정규화란 단어들을 정규화된 형식으로 표현하는 것이다. 가령 U.S.A.와 USA와 US를 US로 통일하는 식이다. 이는 검색엔진에서 문서들을 추출할 때 유용할 수 있다. 다음과 같은 방법들이 있다.
-
Case Folding
- 모든 문자들을 소문자화함
- 일반화를 위해서 유용: 학습데이터와 테스트데이터 사이의 불일치 문제에 도움
- 정보검색, 음성인식 등에서 유용
- 감성분석 등의 문서분류 문제에서는 오히려 대소문자 구분이 유용할 수 있음 -
Lemmatization
- 어근을 사용해서 표현
- am, are, is → be
단어정규화가 필요한 근본적인 이유는, 단어들 사이의 유사성을 이해해야 하기 때문이다. 단어정규화 작업을 같은 의미를 가진 여러 형태의 단어들을 하나의 단어로 대응시키는 것으로 이해할 수 있다.
그러나 단어를 vocabulary로 정의된 공간(고차원 희소 벡터)이 아닌 저차원 밀집 벡터로 대응시킬 수 있다면, 즉 단어임베딩을 사용해서 단어를 표현하게 되면 단어정규화의 필요성이 줄어들게 된다.
