단어 임베딩
단어의 의미를 어떻게 나타낼 수 있을까? 단어간의 관계를 잘 표현할 수 있어야 좋은 표현방식이다. One-hot encoding 방식은 단어간의 관계를 표현하기 어렵다. 단어의 의미를 나타내기 위해 다음과 같은 것들을 고려해야 한다.
동의어(Synonyms)
문맥상 같은 의미를 가지는 단어들이다. (couch, sofa)
동의어라고 해서 항상 그 단어로 대체할 수 있는 것은 아니다.
유사성(Similarity)
유사한 의미를 가진 단어들이다. (car, bicycle)
연관성(Relatedness)
단어들은 의미의 유사성 외에도 다양한 방식으로 연관될 수 있다.
-
Semantic Field
특정한 주제(topic)이나 영역(domain)을 공유하는 단어들이다.
예를 들면, houses 영역에는 (door, roof, kitchen, family, bed) 같은 단어들이 있다. -
Semantic Frame
특정 행위에 참여하는 주체들의 역할에 관한 단어들이다.
예를 들면, 상거래라는 행위에 참여하는 주체들은 (buy, sell, pay) 등의 행동을 한다.
벡터로 의미 표현하기
"The meaning of a word is its use in the language." 단어의 의미라는 것은, 결국에 그 언어에서의 어떻게 사용되는지이다. 단어 자체가 독립적인 의미를 가지기보다, 주변의 환경(주변 단어들의 분포)에 의해 의미가 결정된다.
만약, 두 단어 A와 B가 거의 동일한 주변 단어들의 분포를 가지고 있다면, 그 두 단어는 유사어라고 볼 수 있는 것이다.
따라서 단어의 의미를 분포적 유사성(distributional similarity)을 사용해 표현하고자 한다. 벡터를 사용해서 분포적 유사성을 표현하면, 벡터공간 내에서 비슷한 단어들은 가까이 위치하게 된다.

이렇게 벡터로 표현된 단어를 임베딩(embedding)이라고 부른다. 최근 NLP 방법들은 모두 임베딩을 사용해서 단어의 의미를 표현한다.
왜 임베딩을 사용하는가?
-
임베딩을 사용하지 않는다면
- 각 속성은 한 단어의 존재 유무
- 학습 데이터와 테스트 데이터에 동일한 단어가 나타나지 않으면 예측 결과가 좋지 못함 -
임베딩을 사용하는 경우
- 각 속성은 단어 임베딩 벡터
- 테스트 데이터에 새로운 단어가 나타나도 학습 데이터에 존재하는 유사한 단어를 통해학습한 내용이 유효
임베딩의 종류
-
희소벡터(sparse vector)
- tf-idf
- Vector propagation (검색엔진을 위한 질의어, 문서 표현) -
밀집벡터(dense vector)
- Word2Vec
- Glove
TF-IDF
희소벡터로 임베딩하는 알고리즘 중 하나인 TF-IDF 방식에 대해 알아보자.
Term-document 행렬
각 문서는 단어들의 벡터로 표현된다. 문서에 나타나는 단어별 빈도수로 표현할 수 있다.
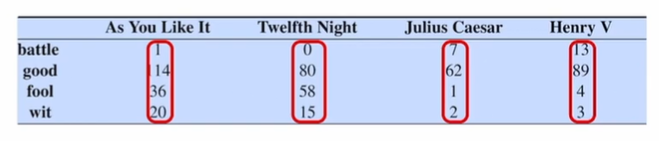
반대로, 단어들을 문서 개수의 차원을 갖는 벡터로 나타낼 수도 있다.
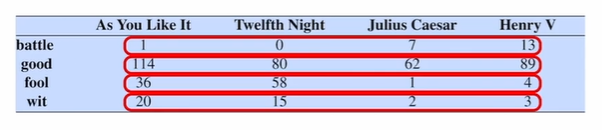
Word-word 행렬(Term-context 행렬)
각 단어를 그 주변 단어들의 빈도를 가지고 벡터로 표현할 수도 있다.

- 벡터의 유사도 계산: Cosine Similarity

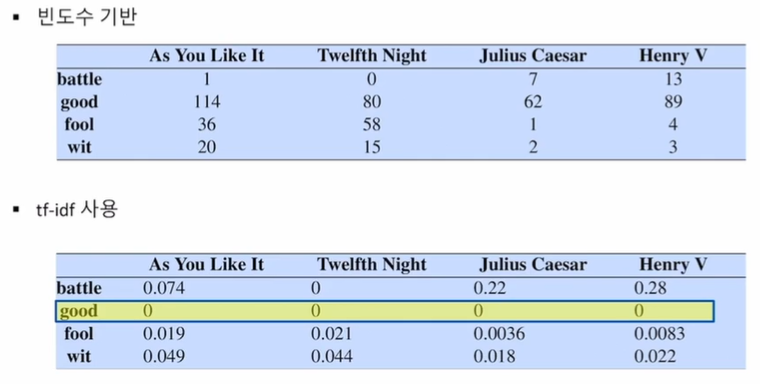
단어의 빈도수를 그대로 사용할 때는 문제점이 있다. "the", "it", "they"등의 단어는 매우 자주 나타나지만, 의미를 구별하는데 도움이 되지 않는다. 이를 TF-IDF 방법으로 보정해줄 수 있다.
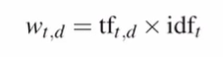
Term Frequency(tf)
문서 d에서 단어 t가 몇 번 나타났는지를 나타낸다.
Document Frequency(df)
단어 t를 포함하는 모든 문서들의 개수를 나타낸다. 특정 문서에만 나타나는 단어들은 이 값이 작을 것이다. 이 값에 역수를 취하여(idf) tf에 곱한 값이 문서 d에서 단어 t의 가중치 값이 된다.
(은 전체 문서의 개수)
최종적으로, 빈도수 기반 단어 벡터와 tf-idf를 사용하였을 때 단어 벡터는 다음과 같다.
밀집벡터(dense vector)
-
tf-idf vector
- 길다
- 희소성 (sparse, 대부분의 원소가 0)
- wide network -
Word2Vec, Glove
- 짧다
- 밀집성 (dense, 대부분의 원소가 0이 아님)
- deep network
밀집벡터가 선호되는 이유는, 더 적은 개수의 학습 파라미터를 수반하며 더 나은 일반화 능력을 가지기 때문이다. 또한 동의어, 유사어를 더 잘 표현한다.
Word2Vec
주어진 단어 w를 인접한 단어들의 빈도수로 나타내는 대신, 주변 단어를 예측하는 분류기를 학습하면 어떨까? 즉, 단어 w가 주어졌을 때 단어 c가 주변에 나타날 확률을 구하도록 분류기를 학습시키고, 이 예측 모델의 최종예측값이 아닌 모델 내 단어 w의 가중치벡터를 얻는 것이다.
이것이 굉장히 유용한 이유는, 이 모델을 학습하기 위한 목표값이 이미 데이터 내에 존재하기 때문이다. 사람이 수동으로 레이블을 생성할 필요가 없이 주어진 문서만 가지고 학습을 할 수 있다.(Self-supervision)
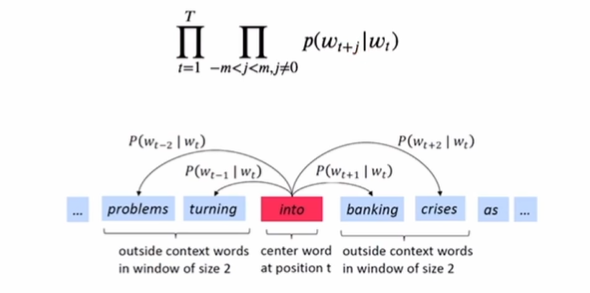
Skip-Gram
Word2Vec을 학습하는 방법 중 하나인 Skip-Gram에 대해 살펴보자. Skip-gram 모델은 한 단어가 주어졌을 때, 그 주변 단어를 예측할 확률을 최대화 하는 것이 목표이다. 즉 단어들의 시퀀스 가 주어졌을 때 다음 확률을 최대화하고자 한다.
파라미터를 명시화해서 우도함수로 표현하면 다음과 같다.
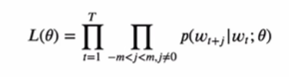
파라미터 는 두 개의 임베딩 행렬 와 를 포함한다. 를 목표(또는 입력) 임베딩 행렬, 를 상황(또는 출력) 임베딩 행렬이라고 부른다. 와 의 shape은 같으며, 만약 사전에 5만개의 단어가 있다면 는 5만개의 차원 벡터로 이루어진다.
하나의 목표 단어 와 상황 단어 가 주어졌을 때 와 를 각각 임베딩 벡터라고 하면 skip-gram 모델은 다음가 같은 확률 모델을 가정한다. dot product를 통해 두 단어 사이의 유사성을 포착한다.
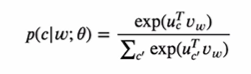
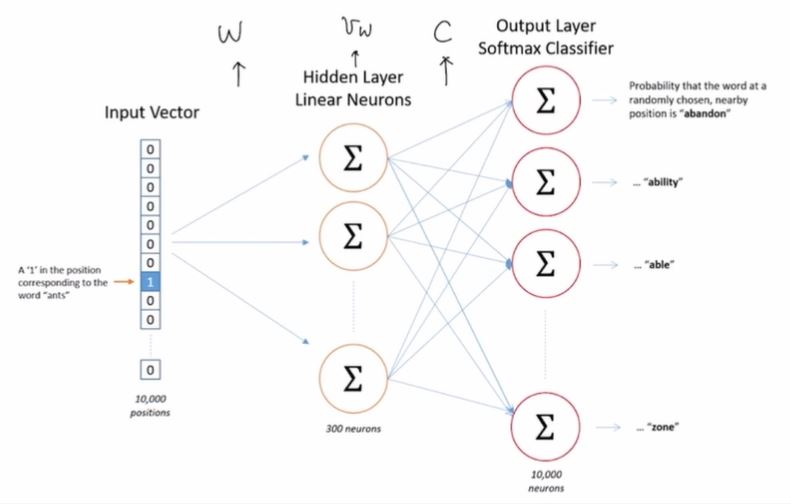
가 주어졌을 때 를 예측하는 문제로, 가 하나의 입력 속성 벡터인 것이다. 이것은 굉장이 차원이 큰 multi class classification 문제를 푸는 것으로 생각할 수 있다. 하지만 여기서 우리가 얻으려는 것은 예측값이 아니라 임을 기억하자.
여기서 를 단어 에 대한 one-hot 벡터라고 하면, 와 는 다음과 같이 정의된다.
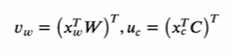
이 문제에 해당하는 신경망은 다음과 같다.

이 모델의 문제점은, 계산량이 매우 많다는 것이다. 해결책으로 Noise-constrastive estimation을 사용할 수 있다. Normalization constant를 하나의 파라미터로 학습하는 방법이다. 다중클래스 분류 문제를 이진 분류 문제로 변환하여 새로운 목표함수를 최적화시키는 것인데, 이렇게 해서 얻어지는 파라미터들이 원래 likelihood의 최적해를 근사한다는 것이 증명되어있다.
Word2Vec은 이 방법을 그대로 사용하는 것이 아니라 단순화시켜서 negative sampling이라는 방식을 사용한다. 더 알아보기 위해서 다음 자료를 참고하자.
Negative sampling을 사용했을 때 목표함수는 다음과 같다.
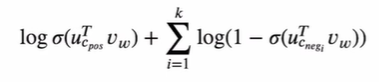
신경망의 구조는 그대로이지만, normalization constant를 계산할 필요가 없고 gradient 계산이 단순화된다.
Word2Vec 학습과정 요약
- |v|개의 d차원 임베딩을 랜덤하게 초기화
- 주변 단어들의 쌍을 positive example로 생성
- 빈도수에 의해 추출된 단어들의 쌍을 negative example로 생성
- 위 데이터를 사용해 분류기 학습
- 학습된 임베딩 w가 최종 결과물
