ML 기반 추천 엔진: 추천 엔진이란?
추천의 정의와 예
추천 엔진 정의
-
사용자와 아이템
- 사용자: 서비스를 사용하는 사람
- 아이템: 서비스에서 판매하는 물품
- 다른 사용자가 물품이 될 수도 있음(ex. 페이스북 친구 추천) -
추천이 언제 필요해질까?
- 보통 서비스가 성장하면 사용자/아이템의 수도 같이 성장
- 특시 사용자의 성장도가 훨씬 커짐
- 하지만 아이템의 수가 커지면서 아이템 디스커버리 문제가 대두됨
- 모든 사용자가 검색(능동적)을 하지 않으며 사람들이 점점 더 추천(수동적)에 의존
추천 엔진의 정의
- 사용자가 관심있어 할만한 아이템을 제공해주는 자동화된 시스템(트위터의 알파 제인의 정의)
- 비지니스의 장기적인 목표(=매출액)를 개선하기 위해 사용자에게 알맞은 아이템을 자동으로 보여주는 시스템(야후의 디팍 아그리왈의 정의)
왜 추천 엔진이 필요한가?
-
조금의 노력으로 사용자가 관심있어 할만한 아이템을 찾아주는 방법
- 특히 아이템의 수가 굉장히 큰 경우 더 의미가 있음
- 결국은 개인화로 연결됨
- 또한 가끔씩 전혀 관심없을 득한 아이템도 추천 가능(serendipity) -
회사 관점에서는 추천 엔진을 기반으로 다양한 기능 추가 가능
- 마케팅시 추천 엔진 사용(이메일 마케팅)
- 관련 상품 추천으로 쉽게 확장 가능 -
아이템의 수가 많아서 원하는 것을 찾기 쉽지 않은 경우
- 검색을 위한 수고를 덜어줌 -
추천을 통해 신상품 등의 마케팅이 가능해짐
- 새로 나온 아이템들은 노출 자체가 어려운데 추천을 통해 기회를 줄 수 있음 -
인기 아이템 뿐만 아니라 롱 테일의 다양한 아이템의 노출 가능
- 추천 방식에 따라 다르지만 개인화가 잘 되면 이게 가능
추천은 결국 매칭 문제
- 사용자와 아이템에 대한 부가 정보들이 필요해짐
- 사용자 프로파일 정보: 개인정보, 관심 카테고리와 서브 카테고리, 태그, 클릭 혹은 구매 아이템 등
- 아이템 부가 정보: 먼저 분류 체계를 만드는 것이 필요하며 태그 형태로 부가정보를 유지하는 것도 아주 좋음
- 무엇을 기준으로 추천을 할 것인가? 클릭, 매출, 소비, 평점...
추천 엔진 예제
-
추천 엔진의 예들
- 아마존 관련 상품 추천
- 넷플릭스 영화/드라마 추천
- 구글 검색어 자동완성
- 링크드인 혹은 페이스북 친구 추천
- 스포티파이 혹은 판도라 노래/플레이리스트 추천
- 헬스케어 도메인의 위험 점수 계산
- 유데미 강좌 추천 -
추천 엔진들의 공통점
- 격자 형태 UI를 사용 -
다양한 종류의 추천 유닛들이 존재
- 일부 유닛은 개인화
- 일부 유닛은 인기도 등의 비개인화 정보 기반
- 추천 유닛의 랭킹이 중요해짐- 이 부분도 모델링을 하여 개인화하는 추세
- 클릭을 최적화하고 이 데이터 수집을 위한 실험을 함
추천 엔진 알고리즘 종류
다양한 방식의 추천 알고리즘
-
컨텐츠 기반 (아이템 기반)
- 개인화된 추천이 아니며 비슷한 아이템을 기반으로 추천이 이뤄짐
- 텍스트 처리가 필요하기도 함(NLP)
- 유사도 계산 필요 -
협업 필터링(Collaborative Filtering): 평점 기준
- 기본적으로 다른 사용자들의 정보를 이용하여 내 취향을 예측하는 방식
- 사용자 기반: 나와 비슷한 평점 패턴을 보이는 사람들을 찾아서 그 사람들이 높게 평가한 아이템 추천
- 아이템 기반: 평점의 패턴이 비슷한 아이템들을 찾아서 추천 -
사용자 행동 기반
- 아이템 클릭/구매/소비 등의 정보를 기반으로 한 추천
- 사용자와 아이템에 대한 부가 정보가 반드시 필요
- 모델링을 통해 사용자와 아이템 페어에 대한 클릭 확률 등의 점수 계산이 가능 -
많은 경우 위의 알고리즘들을 하이브리드 형태로 사용
컨텐츠 기반
- 아이템 간의 유사도를 측정하여 추천
- 책이라면 타이틀, 저자, 책 요약, 장르 등의 정보를 사용
- 많은 경우 NLP 테크닉을 사용해 텍스트 정보를 벡터 정보로 변환
- 단어 카운트, TF-IDF 카운트, 임베딩 등 사용 가능
- 개인화된 추천이 아님
- 모든 이에게 동일한 아이템을 추천
- 구현이 상대적으로 간단함
- 보통 아이템의 수가 사용자의 수보다 작음
아이템 기반
사용자 기반 협업 필터링(User-to-User)
나와 비슷한 평점 패턴을 보이는 사람들을 찾아서 그 사람들이 높게 평가한 아이템을 추천하는 방식
- 나와 비슷한 사용자를 어떻게 찾을지가 중요
- 사용자 프로파일 정보 구축
- 프로파일 정보 간의 유사도 계산(KNN 알고리즘을 사용하기도)
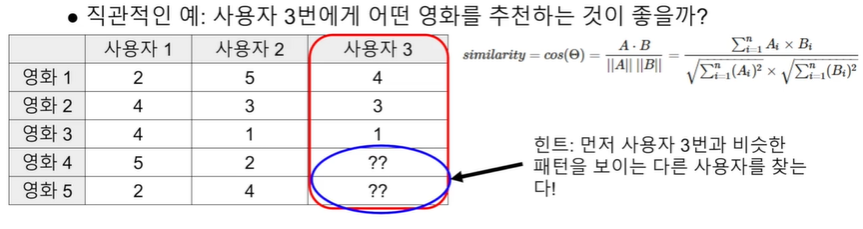
아이템 기반 협업 필터링(Item-to-Item)
- 아이템들간의 유사도를 비교하는 것으로 시작
- 사용자 기반 협업 필터링과 비교해 더 안정적이며 좋은 성능
- 아이템의 수가 보통 작기에 사용자에 비해 평점의 수가 평균적으로 더 많고 계산량이 작음
- 사용자 기반으로 하면 sparse matrix가 만들어짐
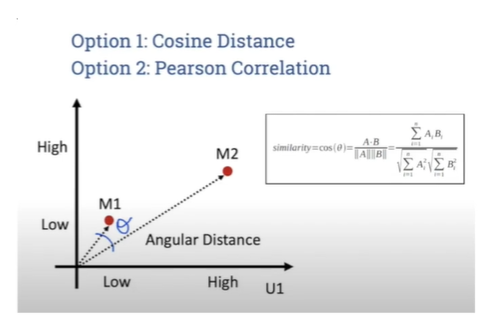
유사도 측정 방법
- 두 개의 비교 대상을 N차원 좌표로 표현
- 보통 코사인 유사도 혹은 피어슨 유사도 사용
- 두 벡터의 방향성이 비슷할수록 1에 가까운 값이 계산됨
- 두 벡터가 반대방향을 향하는 경우 -1이 계산됨
- 피어슨 유사도는 코사인 유사도의 개선 버전으로 각 벡터를 중앙으로 중심 재조정
협업 필터링 문제점
- Cold Start 문제
- 사용자: 아직 평점을 준 아이템이 없는 경우
- 아이템: 아직 평점을 준 사용자가 없는 경우
- 보통 컨텐츠 기반 혹은 사용자 행동 기반 추천과 병행하여 이 문제를 해결 - 리뷰 정보의 부족(sparsity)
- 업데이트 시점
- 사용자나 아이템이 추가될 때마다 다시 계산을 해주어야 함 - 확장성 이슈
- 사용자와 아이템의 수가 늘어나면서 행렬 계산이 오래 걸리게 됨
- Spark와 같은 인프라가 필요한 이유
협업 필터링 구현 방법
- 메모리 기반
- 사용자간 혹은 아이템간 유사도를 미리 계산
- 추천 요청이 오면 유사한 사용자 혹은 아이템을 K개 뽑아서 이를 바탕으로 아이템 추천
- 구현과 이해가 상대적으로 쉽지만 스케일하지 않음(평점 데이터의 부족)
- 모델 기반
- 사용자 아이템 행렬에서 비어있는 평점들을 SGD를 사용해서 채우는 방식
- 보통 SVD(Singular Vector Decomposition)를 사용해서 구현되며 요즘은 딥러닝 오토인코더를 사용하기도 함
- 평점을 포함한 다른 사용자 행동을 예측하는 방식으로 진화하고 있기도 함
사용자 행동 기반
- 사용자의 행동을 보고 그에 맞춰 아이템을 추천
- 주로 암시적 정보(클릭, 구매, 소비)를 기반으로 - 사용자 행동 기반 간단한 추천 유닛 구성
- 사용자가 관심있는 특정 카테고리의 새로운 아이템
- 사용자가 관심있는 특정 카테고리의 인기 아이템 - 사용자 행동을(클릭 혹은 구매) 예측하는 추천
지도학습 방식의 추천 엔진
- 어떤 기준으로 추천을 하느냐가 가장 중요(머신러닝의 레이블 정보)
- 명시적인 힌트: 리뷰 점수 혹은 좋아요
- 암시적인 힌트: 클릭, 구매, 소비
- 클릭은 노이즈가 있지만 장점은 관심없는 아이템들의 파악이 쉬움
- 자세한 사용자 행동 정보의 수집, 저장과 가공이 먼저 필요
