추천 시스템을 실제 적용하기 위해서는 cost efficiency가 중요하다. MF나 Item2Vec을 이용해서 구했다고 하더라도 모든 아이템에 대해서 유사도를 구하면 정확도는 높을 수 있어도 시간 효율 측면에서 매우 비효율적. 그런 측면에서 ANN이 고안이 되었다. 정확도와 시간을 trade-off하면서 적당한 정확도를 확보하는 것.
MF with ALS
먼저 retail data를 MF ALS 모델을 이용해 학습을 시켜보겠다.
전처리
MF 기반에 모델에 데이터를 feeding하기 위해서는 유저,아이템 인터렉션의 sparse matrix가 필요하다. 현재 모양은 좀 동떨어진 형태. 여기에는 rating이 없으니 quantity를 rating으로 취급한다.
Null 값 처리
먼저 유저 아이디가 없거나 quatity가 0인 것들은 정리하고 필요한 필드만 추출한다.
train test 분리
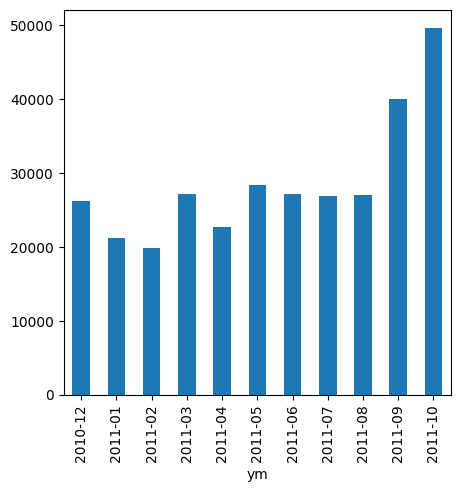
11년 10이전은 train으로 분리했다.
sparse 만들기
현재 데이터는 구매 기록을 바탕으로 되어있기 때문에 같은 아이템을 두 번 구매해도 다른 row로 표현된다. 이를 유저 id와 item id를 기준으로 묶어서 sum을 해 유저 아이템의 row를 unique하게 만들어준다.
또한 id를 category 타입으로 만들어준다.
train_df['CustomerID'] = train_df['CustomerID'].astype("category")
train_df['StockCode'] = train_df['StockCode'].astype("category")
train_df['user_id'] = train_df['CustomerID'].cat.codes
train_df['item_id'] = train_df['StockCode'].cat.codes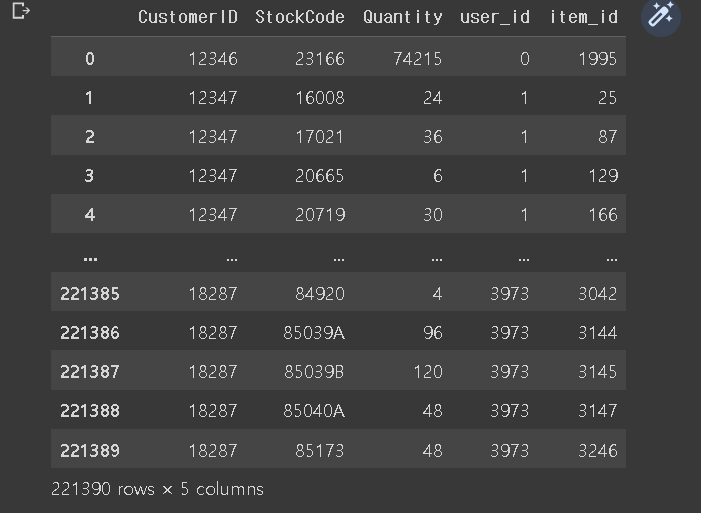
이렇게 변환하면 어떤 user_id가 어떤 customer인지 mapping이 필요하다.
user_id_map = dict(enumerate(train_df['CustomerID'].cat.categories)) # 새로운 user_id => 기존 CustomerID
item_id_map = dict(enumerate(train_df['StockCode'].cat.categories)) # 새로운 item_id => 기존 StockCode
customer_id_map = dict() # 기존 CustomerID => 새로운 user_id
stock_code_map = dict() # 기존 StockCode => 새로운 item_id
for x, y in zip(user_id_map.keys(), user_id_map.values()) :
customer_id_map[y] = x
for x, y in zip(item_id_map.keys(), item_id_map.values()) :
stock_code_map[y] = x마지막으로 quantity를 r로 user id를 index, item id를 col로 sparse를 만든다.
sparse_user_item = sparse.csr_matrix((train_df['Quantity'].astype(float), (train_df['user_id'], train_df['item_id']))) 모델 학습
model = implicit.als.AlternatingLeastSquares(
factors=20,
regularization = 0.1,
iterations = 100,
calculate_training_loss=False,
use_gpu = False
)
model.fit(sparse_user_item)추천
a, b = model.recommend(0, sparse_user_item[0], 10)Metric 평가
def get_precision(relevant, recommend):
_intersection = set(recommend).intersection(set(relevant))
return len(_intersection) / len(recommend)
def get_recall(relevant, recommend):
_intersection = set(recommend).intersection(set(relevant))
return len(_intersection) / len(relevant)
def get_ndcg(relevant_item, recommend_item):
# Discounted Cumulative gain
k = len(recommend_item)
discount = np.log2(np.arange(k) + 2)
cg = []
for item in recommend_item:
if item in relevant_item:
cg.append(1)
else:
cg.append(0)
dcg = np.sum(np.divide(cg, discount))
# Ideal Discounted Cumulative gain
k_for_idcg = min(k, len(relevant_item))
idcg = np.zeros(k)
for i in range(k_for_idcg):
idcg[i] += 1
idcg = np.sum(np.divide(idcg, discount))
#Normalized Discounted Cumulative Gain
return dcg / idcg이렇게 metric 함수를 정의하고 test data에서 유저가 구매한 아이템과 내가 추천한 아이템을 비교하면서 평가를 해본다.
user_grouped = test_df.groupby('CustomerID')test df를 user id로 그룹해주고
for customer_id, user_df in tqdm(user_grouped):이렇게 하면 id와 그룹화된 dataframe이 딸려온다.
그러면 user id로 model의 user vector에 접근을 하고 model의 item vector와 dot product를 한다.(ALS는 MF 기반이기 때문에 를 통해서 rating을 구한다) 그리고 top k개를 추출
user_id = customer_id_map[customer_id]
user_vector = model.user_factors[user_id]
scores = item_vecs.dot(user_vector)
top_k_item = np.argpartition(scores, -k)[-k:]이를 기반으로 Precision, Recall, nDCG를 구한다.
Annoy & Faiss 서빙
n 아이템과 유사한 아이템을 추천을 하고 싶다면
Annoy
n_trees = 20
similar_items_index = annoy.AnnoyIndex(item_vecs.shape[1], "angular")
# 모든 아이템 벡터를 annoy index에 추가
for i, row in enumerate(item_vecs):
similar_items_index.add_item(i, row)
# 모델 build
similar_items_index.build(n_trees)
itemid = 0
N = 20
neighbours, dist = similar_items_index.get_nns_by_item(itemid, N, include_distances=True)Faiss
similar_items_hnsw_index = faiss.IndexHNSWFlat(item_vecs.shape[1], item_vecs.shape[1])
# 모든 아이템 벡터를 faiss HNSW index에 추가
similar_items_hnsw_index.add(item_vecs)
# faiss 안에 있는 전체 아이템 개수 확인
similar_items_hnsw_index.ntotal
n_clusters = 10 # 클러스터 개수
n_subquantizer = 5 # subquantizer 개수
n_bits = 8 # 각각의 sun-vector가 8bits로 인코딩 됨
similar_items_basic_index = faiss.IndexFlatL2(item_vecs.shape[1]) # 고정된 길이의 임베딩 벡터화 (coarse qauntizer)
similar_items_ivfpq_index = faiss.IndexIVFPQ(similar_items_basic_index, item_vecs.shape[1], n_clusters, n_subquantizer, n_bits)
similar_items_ivfpq_index.train(item_vecs) # pruning과 PQ 가 있어서 training 시켜야 함
# 모든 아이템 벡터를 faiss IVFPQ index에 추가
similar_items_ivfpq_index.add(item_vecs)
# faiss 안에 있는 전체 아이템 개수 확인
similar_items_ivfpq_index.ntotal
itemid = 0
N = 20
neighbours, dist = similar_items_hnsw_index.search(item_vecs[itemid].reshape(1, -2), N)
[(y, x) for x, y in zip(*neighbours, *dist)