AlexNet
- ReLU activation
- GPI implementations
- Local response normalization, Overlapping pooling
ReLU
-
Preserves properties of linear models
-
Easy to optimize
-
Overcom the vanishing grad problem
VGGNet
-
Increasing depth with 3x3 filters
-
1x1 conv for fc layers
-
Dropout 0.5
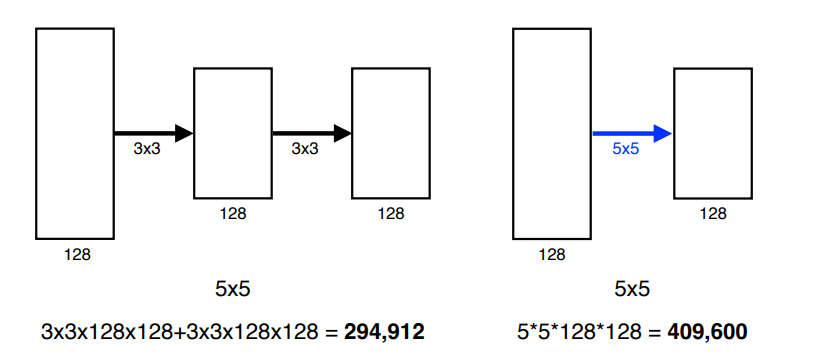
Why 3X3 convolution?
-
파리미터 수 측면에서 이득
-
더 깊게 쌓을 수 있음
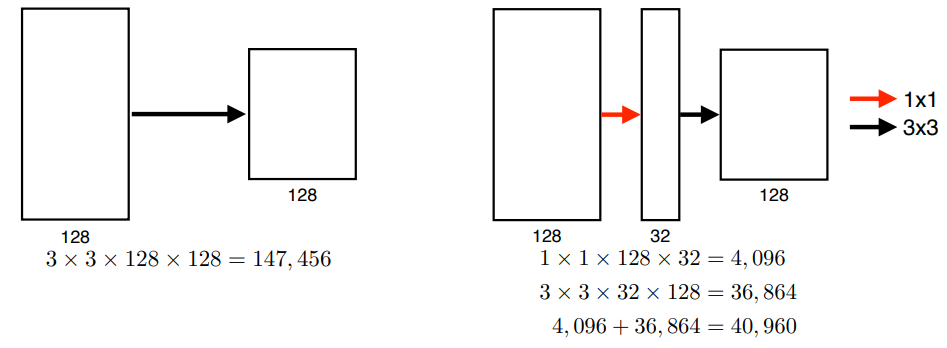
GoogLeNet
- network in network (NiN) with inception blocks
inception blocks
- reduce the # of params
- 1x1 conv = channel wise dimension reduction
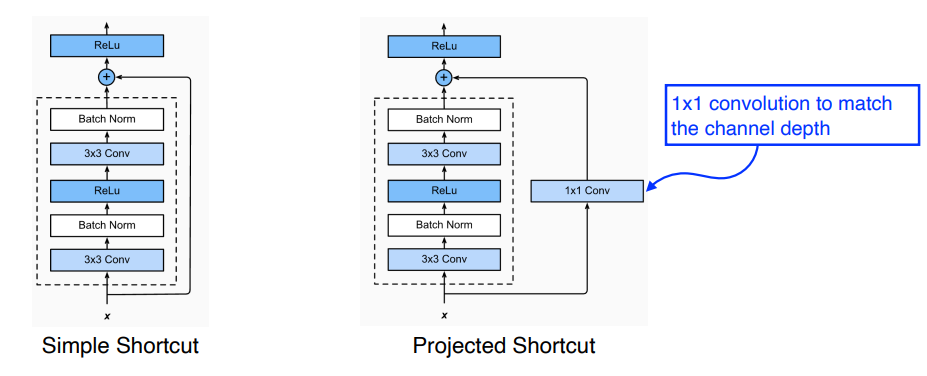
ResNet
- The deeper the nn is, the harder to train the nn
- Add an identity map(skip connection) afther nonlinear activations
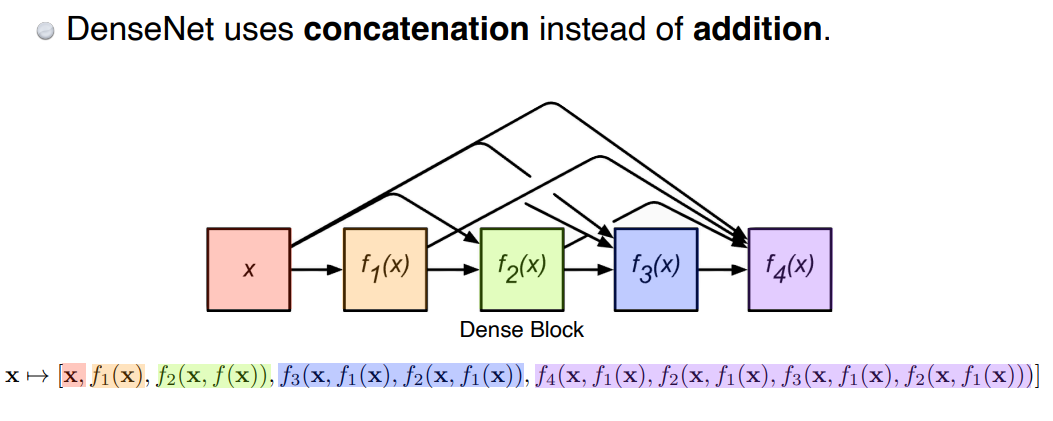
DenseNet
- instead addition, use concatenation
- However, repeated concatenation can lead to increasing # of channels(params)
- DenseNet introduces transition block to solve this problem
Transition Block
- BN -> 1x1 conv(reduction) -> 2x2 Avg pooling


AI Engineer