Joint distribution
가 주어지고 를 예측을 하는 문제가 주어졌을 때 가장 간단한 방법은 결합확률분포를 이용하는 것일 것이다.

하지만 현재는 바로 전의 과거(very short term)에만 dependent하다는 문제가 있다.
Latent autoregressive model
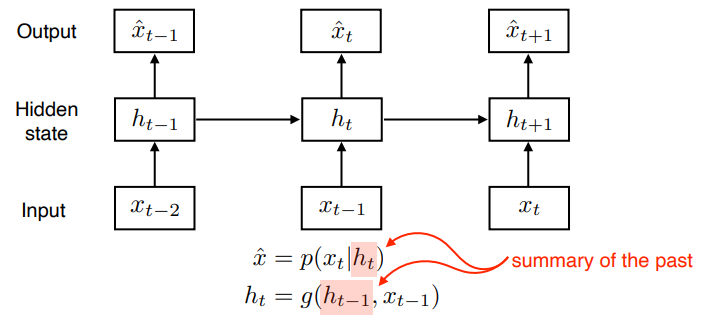
앞서 언급한 문제를 해결하기 위해서는 더 많은 과거의 정보를 포함할 필요가 있다. 이 문제를 를 이용해서 과거의 정보를 요약하고 이를 다음 state에 넘겨줌으로서 해결하는 방식을 채용한다.
RNN
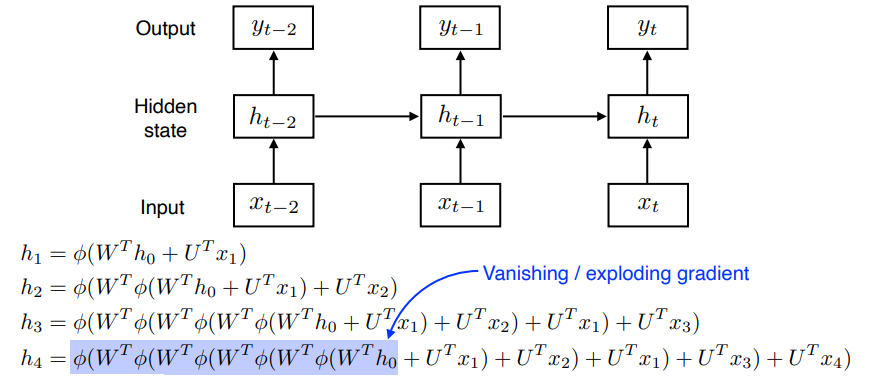
RNN은 앞서 언급한 LAM의 구조에 가 자기 자신으로 돌아오는 구조를 가진 모델이다. 하지만 아래 수식과 같이 time window가 길어지면 vanishing gradient 문제가 발생한다.
LSTM
LSTM은 RNN의 gradient vanishing, exploding으로 인한 long term dependencies를 해결하기 위해 고안된 모델로 다음과 같은 구조를 가진다.
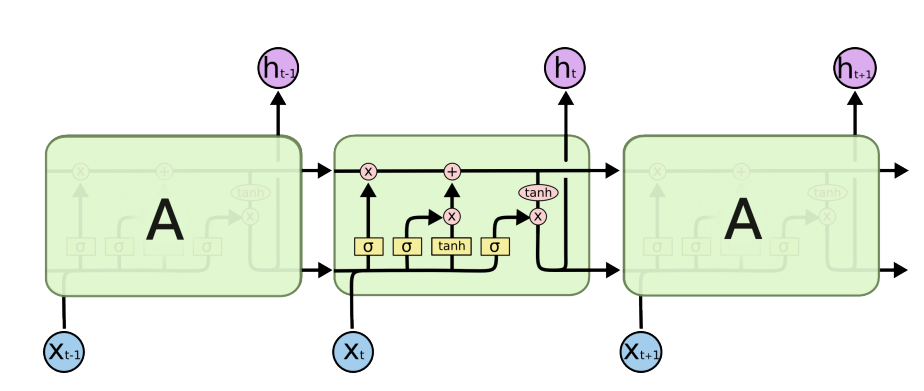
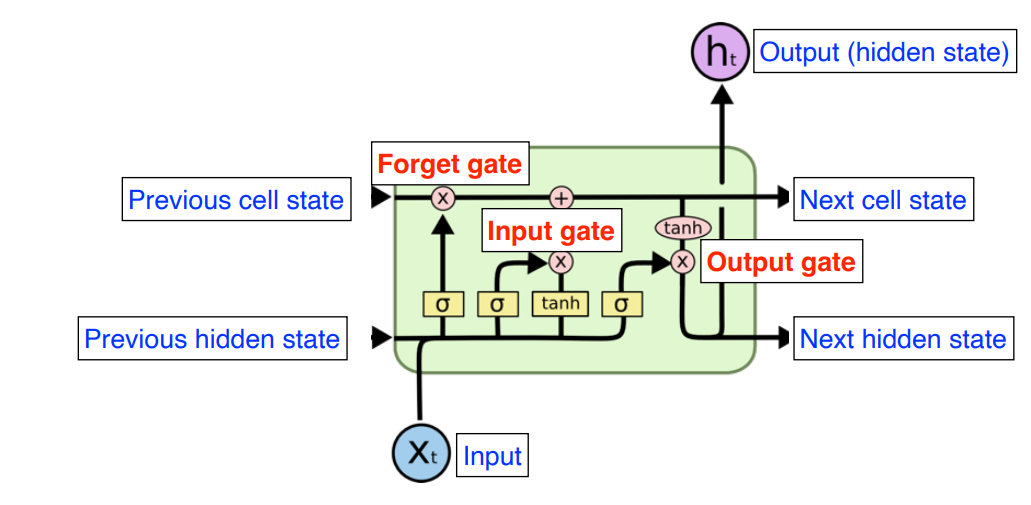
cell state
cell state는 LSTM의 core idea로 forget gate와 input gate에 의하여 어떤 것을 버리고 올릴 지 조정이 되며 계속해서 conveyer belt처럼 전달된다.
forget Gate
이전 Cell state의 정보중 어떤 정보를 버릴 지 정한다
Input Gate
현재 받은 정보중 어떤 정보를 올릴 지 정한다.
update cell
이전 단계에서 조정된 정보를 바탕으로 cell state를 업데이트 한다.
output gate
어떤 값을 로 내보낼 지 정한다.
Gru
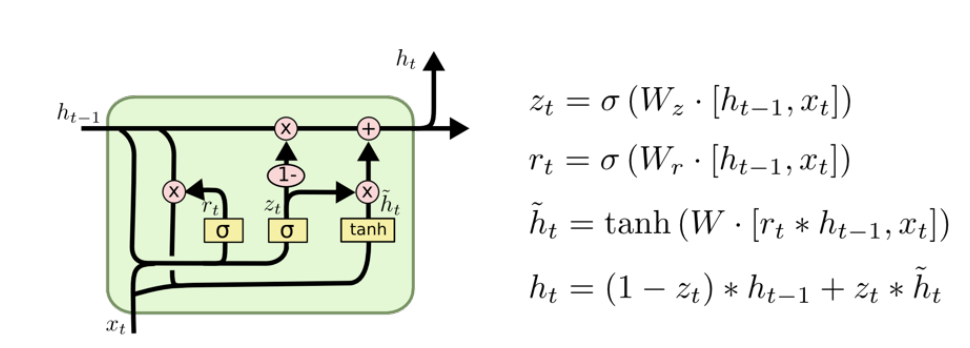
LSTM에서 cell state가 생략된 구조. reset gate와 update gate 밖에 없다. parameter 수가 적어서 대체적으로 GRU가 좀 더 성능이 좋다.
LSTM 구현
N = number of inputs
L = input sequence length
Q = dim
일 때
input = N X L X Q 일 것이다.
그리고
D = feature dim
일 때
output = N X L X D 일 것이다.
K = num of hidden layers
D = feature dim
일 때
= K X N X D
= K X N X D일 것이다.
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.n_layer = n_layer # K
self.rnn = nn.LSTM(
input_size=self.xdim,
hidden_size=self.hdim,
num_layers=self.n_layer,
batch_first=True)이렇게 하면 간단하게 LSTM 레이어가 생성이 되는데 마지막 단에 MNIST의 클래스가 10개이므로 이를 출력단을 10개로 바꿔주는 linear layer가 필요하다.
self.lin = nn.Linear(self.hdim,self.ydim)forward
batch에 따라 x가 들어오면 h와 c를 만들어줘야하는데
h,c = N X L X D이므로
h0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)이렇게 하고 rnn의 출력은 N X L X D이다. 하지만 우리가 관심이 있는 것은 마지막 단의 출력 즉 N X L X D의 tensor에서 마지막 L의 즉 N X 1 X D의 tensor만 필요하다. 따라서
rnn_out[:,-1:]을 linear에 넣어주어서 10개로 만들어준다.
