My first Personal Project: Dance Matching platform_ 7)2020_04_18
To Dos
1) JustJerk to CSV > to DB
import requests
import pandas as pd
from urllib.error import HTTPError
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
# 1. 웹페이지 분석 : url
url = "http://jerkdemy.com/16"
headers = {
"user-agent" : UserAgent().chrome
}
response = requests.get(url, headers = headers)
# print(response)
dom = BeautifulSoup(response.content, "html.parser")
# print(dom.text)
table = dom.find("table",{"id":"mh-plan"})
# print(table)
## Total_week : 5주 전체
T_Wks = table.find_all("tr")
## Each_Week : 각 1주 > 2번째주로 설정해보기.
## 2번째주 전체 td 내용
EC_Wks = T_Wks[1].find_all("td")
JJ_Classes = []
for b in range(0, len(T_Wks)):
# 주 단위
print("----------------------------------------------------------------------------------------")
EC_Wks = T_Wks[b].find_all("td")
print("%d 번째주 수업입니다\n\n" %( b+1 ) )
for a in range(0, len(EC_Wks)):
# 일 단위
if a == 0 or len(EC_Wks) - 1 :
EC_Wk_D = EC_Wks[a].find_all("li")
for i in range(2, len(EC_Wk_D)):
# 수업 단위
# 주말 수업
if b == 2 and a == 0 :
Class_Name_None = ""
JJ_Classes.append({
'Class_Names': Class_Name_None ,
'Day_1': "Weekends" ,
'Day_2': EC_Wk_D[0].text ,
'Time_1': "Night" ,
'Time_2': Class_Name_None ,
'Genre': "" ,
'Link': "http://jerkdemy.com/16" ,
'Place': dom.select_one("#text_w201812125c10ae978c041 > div > div > div > p:nth-child(1) > span").text ,
'Contact': dom.select_one("#text_w201812125c10ae978c041 > div > div > div > p:nth-child(3) > span > span").text ,
'NumOfClass': 1 ,
"Img" : dom.select_one("#img_w201812125c10bf1887cc8")["src"]
})
else :
JJ_Classes.append({
'Class_Names': EC_Wk_D[i].find("p").text.strip() ,
'Day_1': "Weekends" ,
'Day_2': EC_Wk_D[0].text ,
'Time_1': "Night" ,
'Time_2': EC_Wk_D[i].find("div").text.strip().replace(" ","").replace("\n","").split(".")[1] ,
'Genre': "" ,
'Link': "http://jerkdemy.com/16" ,
'Place': dom.select_one("#text_w201812125c10ae978c041 > div > div > div > p:nth-child(1) > span").text ,
'Contact': dom.select_one("#text_w201812125c10ae978c041 > div > div > div > p:nth-child(3) > span > span").text ,
'NumOfClass': 1 ,
"Img" : dom.select_one("#img_w201812125c10bf1887cc8")["src"]
})
# ---------------------------------------------------------------------------------------------------------------------------------------------------------
else :
# 주중 수업
EC_Wk_D = EC_Wks[a].find_all("li")
for i in range(2, len(EC_Wk_D)):
# 수업 단위
JJ_Classes.append({
'Class_Names': EC_Wk_D[i].find("p").text.strip() ,
'Day_1': "WeekDay" ,
'Day_2': EC_Wk_D[0].text ,
'Time_1': "Night" ,
'Time_2': EC_Wk_D[i].find("div").text.strip().replace(" ","").replace("\n","").split(".")[1] ,
'Genre': "" ,
'Link': "http://jerkdemy.com/16" ,
'Place': dom.select_one("#text_w201812125c10ae978c041 > div > div > div > p:nth-child(1) > span").text ,
'Contact': dom.select_one("#text_w201812125c10ae978c041 > div > div > div > p:nth-child(3) > span > span").text ,
'NumOfClass': 1 ,
"Img" : dom.select_one("#img_w201812125c10bf1887cc8")["src"]
})
JJ_Classes_DF = pd.DataFrame(JJ_Classes)
# 비어있는 클래스 항목 제외
No_Class = JJ_Classes_DF[JJ_Classes_DF['Class_Names'] == ""].index
JJ_Classes_DF = JJ_Classes_DF.drop(No_Class)
JJ_Classes_DF.to_csv('C:/Users/user/Desktop/Web_Study/Dance_Match/JJ.csv', mode = "a", encoding = 'utf-8-sig')
# Def_GangNam_SS_B.append({
# 'Class_Names': element.select_one(".view_02 > center > font").text ,
# 'Day_1': "Weekends" ,
# 'Day_2': doc.select_one("#bin_eng_lesson2 > div > ul > li:nth-child(3)").text ,
# 'Time_1': "" ,
# 'Time_2': element.select_one(".view_01").text ,
# 'Genre': "" ,
# 'Link': "https://www.defcompany.com/defdance/sub_dance_01_01.html" ,
# 'Place': doc.select_one("#footer_container > div.com_information > div.address1").text.split("\n")[2] ,
# 'Contact': doc.select_one("#timeboard_eng_tittle > div.view").text.split("\n")[0] ,
# 'NumOfClass': 2 ,
# "Img" : "https://www.defcompany.com/defdance/left_banner/def-menu-top2019.png"
# })2) SoulDance to CSV
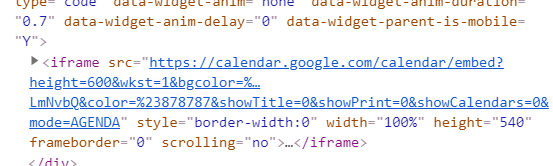
In this Situation,
If you meet iframe,
you have to click and enter one more time
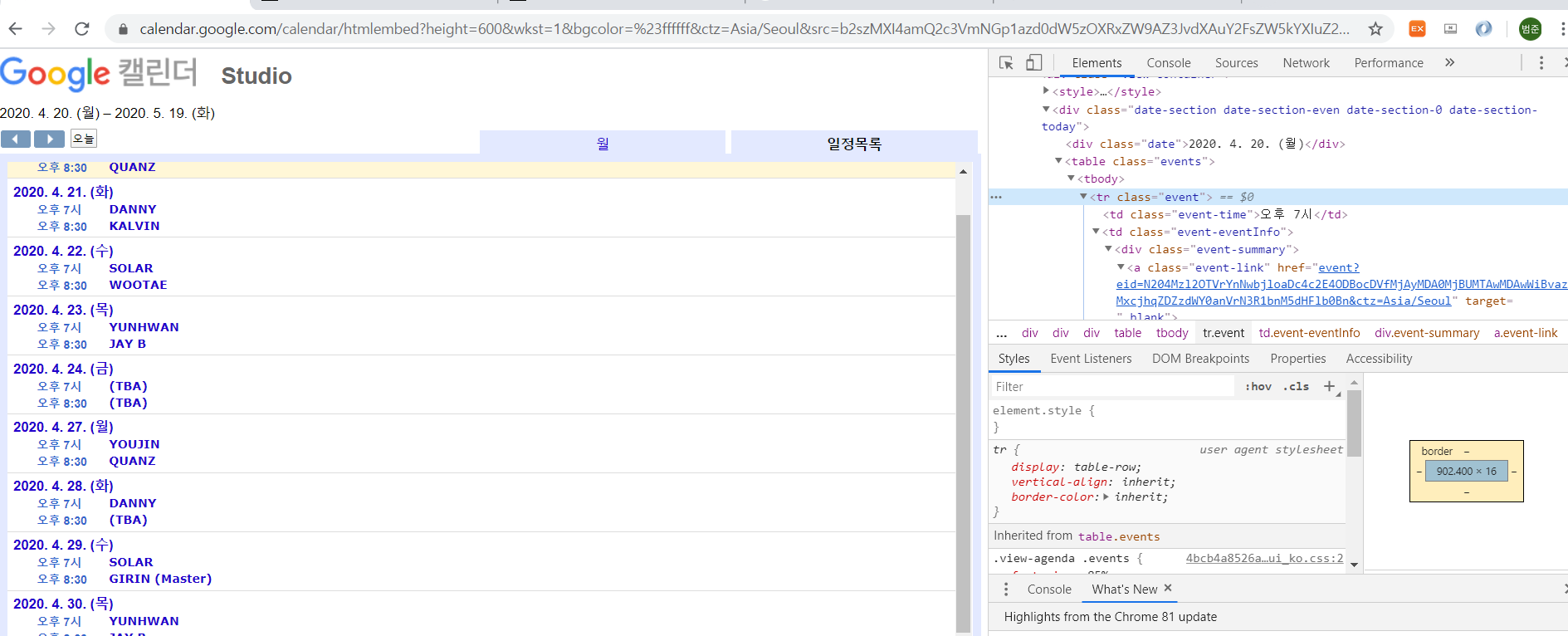
from here, you can properly scrap infos

Dream of being "물빵개" ( Go abroad for Dance and Programming)