Kaggle, Netflix 데이터 설명
Netflix 데이터 분석 목표
- 데이터 파악
- 데이터 전처리
- 결측치 처리- 피쳐 엔지니어링(파생변수 생성)
- 데이터 분석을 통한 인사이트 도출
1. 오징어 게임("Squid Game") 검색- Movie & TV show 비율 시각화
- 연도별 Movie & TV show 수치 시각화
- 월별 Movie & TV show 수치 시각화
- 나라별 타겟팅하는 연령 시각화
- 워드클라우드(핵심 단어 시각화)
Netflix 데이터 분석 라이브러리 불러오기
- Pandas, Numpy, Matplotlib, Seaborn
# numpy 로드하여 np로 사용 # pandas 로드하여 pd로 사용 # matplotlib.pyplot 로드하여 plt로 사용 # seaborn 로드하여 sns로 사용 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
Netflix Pandas 파일 불러오기
# colab 업로드 메뉴를 통해 드라이브 업로드 # csv 파일 읽어오기 netflix = pd.read_csv("/content/netflix.csv")
Netflix 데이터 내용 확인
.columns: 컬럼명 확인.head(3): 데이터의 상단 3개 행 출력.info(): 데이터에 대한 전반적인 정보 제공- 행과 열의 크기
- 컬럼명
- 컬럼별 결측치
- 컬럼별 데이터 타입
# .columns : 컬럼명 확인 netflix.columns
# .info() : 데이터에 대한 전반적인 정보 제공 netflix.info()
Netflix 결측치 비율 확인
- for 반복문을 통해 각 컬럼별 결측치 비율을 계산하여 문자열로 출력
.isna( ): 결측 값은 True 반환, 그 외에는 False 반환
for 반복문을 통해 각 컬럼별 결측치 비율을 계산하여 문자열로 출력
# .isna( ) : 결측 값은 True 반환, 그 외에는 False 반환 for i in netflix.columns : missingValueRate = netflix[i].isna().sum() / len(netflix) * 100 if missingValueRate > 0 : print("{} null rate: {}%".format(i,round(missingValueRate, 2)))
Netflix 결측치 처리
-
.fillna( ): 결측 값을 특정 값으로 채우거나 대체하여 처리 -
.replace(np.nan, '문자'): 결측치를 문자열 바꾸기 함수를 통해 처리 -
.dropna(axis = 0): 결측치가 있는 행 전체 제거 -
원본 객체를 변경하려면 inplace = True 옵션 추가
결측치 처리 (1) - fillna
# .fillna( ) : 결측치를 특정 값으로 채우거나 대체하여 처리 # 원본 객체를 변경하려면 inplace = True 옵션 추가 # 결측치 비율 : country(9.44%) netflix['country'].fillna('No Data', inplace = True)
결측치 처리 (2) - replace
# .replace(np.nan, 'b') : 결측치를 문자열 바꾸기 함수를 통해 처리 # 원본 객체를 변경하려면 inplace = True 옵션 추가 # 결측치 비율 : director(29.91%), cast(9.37%) netflix['cast'].replace(np.nan, 'No Data',inplace = True) netflix['director'].replace(np.nan, 'No Data',inplace = True)
결측치 처리 (3) - dropna
# .dropna(axis = 0) : 결측치가 있는 행 전체 제거 # 원본 객체를 변경하려면 inplace = True 옵션 추가 # 결측치 비율 : date_added(0.11%), rating(0.05%), duration(0.03%) netflix.dropna(axis = 0, inplace=True)
Netflix 결측치 개수 확인
.info( ): 데이터에 대한 전반적인 정보 제공- 컬럼명
- 컬럼별 결측치
- 컬럼별 데이터 타입
- 행과 열의 크기
.isnull().sum()==.isna().sum(): 각 컬럼별 결측치 개수 반환- .isnull 함수는 결측 값은 True 반환, 그 외에는 False 반환하며, 데이터프레임 내에 결측 값을 확인하기 위해 사용
처리된 결측치 확인 (1) - info
# .info() : 데이터에 대한 전반적인 정보 제공 # 8807 rows(원본 데이터 행 개수) - 17 rows(결측치 행) = 8790 rows(결측치가 제거된 행 개수) netflix.info()
처리된 결측치 확인 (2) - .isnull().sum()
# 각 컬럼별 결측치 개수 반환 # .isnull() == .isna() : 결측 값은 True 반환, 그 외에는 False 반환하며, # 데이터프레임 내에 결측 값을 확인하기 위해 사용 netflix.isnull().sum()
# .head(2) : 데이터의 상단 2개 행 출력 netflix.head(2)
Netflix Feature Engineering (1)
Feature Engineering 이란, 기존에 존재하는 변수를 활용하여 새로운 정보를 추가로 생성하는 과정
-
Netflix의 date_added 변수를 이용하여 year_added(개봉한 연도)와 month_added(개봉한 월) 정보를 변수로 생성
.to_datetime(): 시간 형식의 object 타입의 컬럼을 datetime 타입으로 변환.dt.year: datetime에서 연도 정보 추출.dt.month: datetime에서 월 정보 추출
Feature-Engineering 과정은 기존에 존재하는 변수를 활용하여 새로운 정보를 추가로 생성하는 과정
# to_datetime( ) : 시간 형식의 object 타입의 컬럼을 datetime 타입으로 변환 netflix["date_added"] = pd.to_datetime(netflix['date_added']) netflix["date_added"]
- Netflix의 date_added 변수를 이용하여 개봉한 연도, 월 정보를 변수로 생성
# year_added 변수를 생성하여 개봉한 연도 정보 저장 # .dt.year : datetime에서 연도 정보 추출 netflix['year_added'] = netflix['date_added'].dt.year # month_added 변수를 생성하여 개봉한 월 정보 저장 # .dt.month : datetime에서 월 정보 추출 netflix['month_added'] = netflix['date_added'].dt.month netflix.head(3)
Netflix Feature Engineering (2)
-
시청 등급 설명표를 참고하여 Netflix의 rating 변수를 이용한 age_group(시청 등급) 정보를 변수로 생성
.map( ): 사전에 정의한 내용을 변수에 적용
rating 변수의 값 파악
netflix['rating'].unique()
- 시청 등급 설명표를 참고하여 Netflix의 rating 변수를 이용한 age_group 변수 생성
# netflix['age_group']를 생성하여 netflix['rating'] 값 삽입 netflix['age_group'] = netflix['rating'] # age_group 변수에 딕셔너리로 시청 등급에 대한 key, value 선언 age_group = {'TV-MA': 'Adults', 'R': 'Adults', 'PG-13': 'Teens', 'TV-14': 'Young Adults', 'TV-PG': 'Older Kids', 'NR': 'Adults', 'TV-G': 'Kids', 'TV-Y': 'Kids', 'TV-Y7': 'Older Kids', 'PG': 'Older Kids', 'G': 'Kids', 'NC-17': 'Adults', 'TV-Y7-FV': 'Older Kids', 'UR': 'Adults'} # .map( ) : 사전에 정의한 내용을 변수에 적용 netflix['age_group'] = netflix['age_group'].map(age_group)
Netflix Squid Game(오징어 게임) 검색
- 오징어 게임을 검색한 조건을 netflix 원본 데이터에 넣어서 True인 값만 출력
str.contains( ): 지정한 문자열이 포함되어 있으면 True 반환, 그 외에는 False 반환- na = False : 값이 NA일 경우, False로 처리
- case = Fasle : 대소문자를 구분하지 않고 검색
Squid Game(오징어 게임) 검색
# str.contains() : 지정한 문자열이 포함되어 있으면 True 반환, 그 외에는 False 반환 # na = False : 값이 NA일 경우, False로 처리 # case = Fasle : 대소문자를 구분하지 않고 검색 netflix["title"].str.contains('squid game', na = False, case = False)
오징어 게임을 검색한 조건을 netflix 원본 데이터에 넣어서 True인 값만 출력
netflix[netflix["title"].str.contains('Squid Game', na = False, case = False)]
Netflix Movie & TV show 비율 시각화
-
plt.pie( ): 파이 플롯 시각화- labels : 부채꼴 조각 이름
- autopct : 부채꼴 안에 표기될 숫자 형식 지정
문자열 % 포맷팅으로 %0.f 형태는 소수점 없이 정수처럼 인식
진짜 %를 표시하기 위해 %%로 작성 - startangle : 부채꼴이 그려지는 시작 각도 설정, 90이면 12시 방향
- explode : 부채꼴이 파이 플롯의 중심에서 벗어나는 정도 설정
- shadow : 그림자 효과 표시
-
plt.suptitle( ): 전체 플롯의 제목 -
plt.title( ): 서브 플롯의 제목
넷플릭스 브랜드 상징 색깔 시각화
sns.palplot(['#221f1f', '#b20710', '#e50914','#f5f5f1']) plt.title("Netflix brand palette ", loc='left', fontfamily='serif', fontsize=15, y=1.2) plt.show()

Movies & TV shows의 각각 value_counts 출력
# .value_counts( ) : 값의 개수 출력 netflix['type'].value_counts()
# .T : 전치(Transpose) 변환 ratio = pd.DataFrame(netflix['type'].value_counts()).T ratio
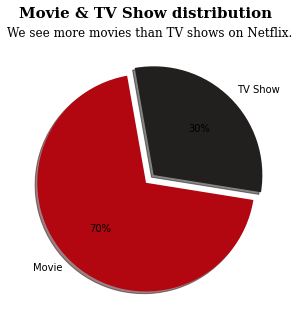
pie plot 통해 Movies & TV shows 각각 비율 시각화
plt.figure(figsize=(5, 5)) # plt.pie의 매개변수 설명 # labels : 부채꼴 조각 이름 # autopct : 부채꼴 안에 표시될 숫자 형식 지정 # 문자열에서 % 포맷팅으로 %0.f 형태로 사용하면 소수점 없이 정수처럼 인식 # 진짜 %를 표시하기 위해 %%로 작성 # startangle : 부채꼴이 그려지는 시작 각도 설정, 90이면 12시 방향 # explode : 부채꼴이 파이 플롯의 중심에서 벗어나는 정도 설정 # shadow : 그림자 효과 표시 plt.pie(ratio, labels=ratio.columns, autopct='%0.f%%', startangle=100, explode=[0.05, 0.05], shadow=True, colors=['#b20710', '#221f1f']) # plt.suptitle : 전체 플롯의 제목 # plt.title : 서브 플롯의 제목 plt.suptitle('Movie & TV Show distribution', fontfamily='serif', fontsize=15, fontweight='bold') plt.title('We see more movies than TV shows on Netflix.', fontfamily='serif', fontsize=12) plt.show()
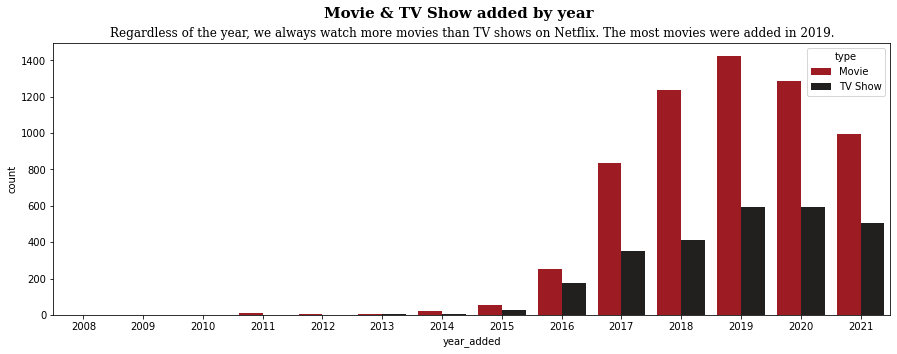
Netflix 연도별 Movie & TV show 수치 시각화
countplot( ): 각 범주에 속하는 데이터의 개수를 막대 그래프 시각화- data : 카운트 플롯에서 사용할 데이터 셋
- x : x축 설정
- hue : 특정 열 데이터로 색상을 구분하여 출력
연도별 Movies & TV shows 수치 시각화
# 항상 Movies가 TV shows보다 압도적인지 궁금! # countplot( ) : 각 범주에 속하는 데이터의 개수를 막대 그래프 시각화 # data : countplot에서 사용할 데이터 셋 # x : x축 설정 # hue : 특정 열 데이터로 색상을 구분하여 출력 plt.figure(figsize=(15, 5)) sns.countplot(data=netflix, x='year_added', hue='type', palette=['#b20710', '#221f1f']) plt.suptitle('Movie & TV Show added by year', fontfamily='serif', fontsize=15, fontweight='bold') plt.title('Regardless of the year, we always watch more movies than TV shows on Netflix. The most movies were added in 2019.', fontfamily='serif', fontsize=12) plt.show()
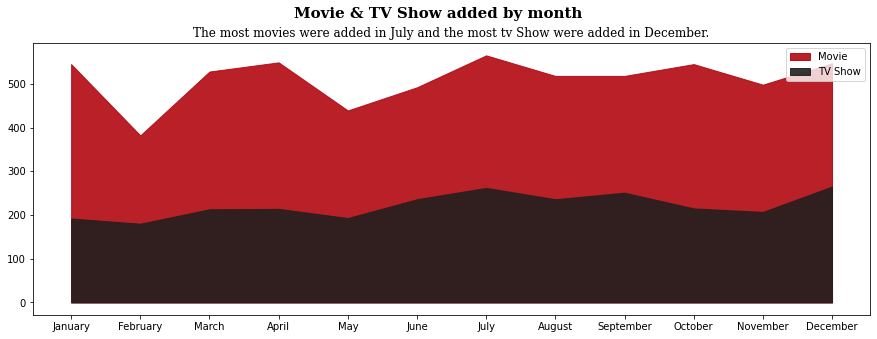
Netflix 월별 Movie & TV show 수치 시각화
-
unstack( ): 인덱스를 컬럼으로 바꾸는 역할- <-> stack( ) : 컬럼을 인덱스로 바꾸는 역할
-
fill_between( ): x축을 기준으로 그래프 영역을 채우는 함수- <-> fill_betweenx( ) : y축을 기준으로 그래프 영역을 채우는 함수
- x : 곡선을 정의하는 노드의 x 좌표
- y1 : 첫 번째 곡선을 정의하는 노드의 y 좌표
- y2 : 두 번째 곡선을 정의하는 노드의 y 좌표
- label : 'Movie', 'TV Show' 문자열 입력
- alpha : 투명도
-
xticks(x, month_name): x축의 눈금 레이블에 month_name 값의 순서대로 설정
월별로 Movies & TV shows 수치 출력
# .groupby( ) : 그룹별 집계, 개봉한 월로 묶고 타입의 개수 구하기 # .value_counts( ) : 값의 개수 출력 # .unstack( ) : 인덱스를 컬럼으로 바꾸는 역할(wide 포맷) netflix_month = netflix.groupby('month_added')['type'].value_counts().unstack() netflix_month
월별로 Movies & TV shows 수치 시각화
plt.figure(figsize=(15, 5)) # fill_between() : x축을 기준으로 그래프 영역을 채우는 함수 # x : 곡선을 정의하는 노드의 x 좌표 # y1 : 첫 번째 곡선을 정의하는 노드의 y 좌표 # y2 : 두 번째 곡선을 정의하는 노드의 y 좌표 # alpha : 투명도 # label : 'Movie', 'TV Show' 문자열 입력 plt.fill_between(x=netflix_month['Movie'].index, y1=0, y2=netflix_month['Movie'], color='#b20710', alpha=0.9, label = 'Movie') plt.fill_between(x=netflix_month['TV Show'].index, y1=0, y2=netflix_month['TV Show'], color='#221f1f', alpha=0.9, label = 'TV Show') # xticks(x, month_name) : x축의 눈금 레이블에 month_name 값의 순서대로 설정 plt.xticks([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December']) # legend() 함수를 사용해서 그래프에 범례 표시 plt.legend() plt.suptitle('Movie & TV Show added by month', fontfamily='serif', fontsize=15, fontweight='bold') plt.title('The most movies were added in July and the most tv Show were added in December.', fontfamily='serif', fontsize=12) plt.show()
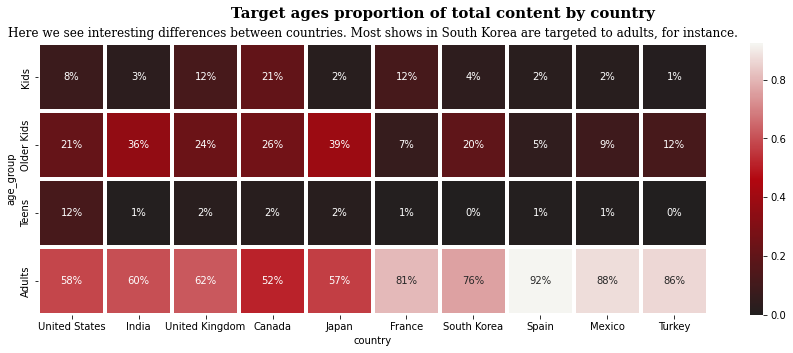
Netflix 나라별 타겟팅하는 연령 시각화
-
heatmap( ): 직사각형 데이터를 색으로 행렬을 표현하여 시각화
열을 뜻하는 heat와 지도를 뜻하는 map을 결합시켜 색상으로 다양한 정보를 제공- cmp : 시각화 시키는 컬러맵
- linewidth : 각 셀을 분할할 선의 너비
- annot : True라면 각 셀에 데이터 값 표시
- fmt : 문자열 형식화 코드
.0% = X
.1% = X.x
.2% = X.xx
-
plt.matplotlib.colors.LinearSegmentedColormap.from_list( ): 컬러맵 생성
나라별 타겟팅하는 연령 수치화
# .groupby( ) : 그룹별 집계, 시청 등급으로 묶고 나라의 개수 구하기 # .value_counts( ) : 값의 개수 출력 # .unstack( ) : 인덱스를 컬럼으로 바꾸는 역할(wide 포맷) netflix_age_country = netflix.groupby('age_group')['country'].value_counts().unstack() netflix_age_country
특정 나라별 타겟팅하는 특정 연령 선택하여 수치화
# .loc[] : 행 이름과 열 이름을 사용하여 특정 행과 열 선택 age_order = ['Kids','Older Kids','Teens','Adults'] country_order = ['United States', 'India', 'United Kingdom', 'Canada', 'Japan', 'France', 'South Korea', 'Spain', 'Mexico', 'Turkey'] netflix_age_country = netflix_age_country.loc[age_order, country_order] # .fillna(0, inplace = True) : 결측치를 0으로 대체하여 원본 데이터에 저장 netflix_age_country.fillna(0, inplace = True) netflix_age_country
나라별 타겟팅하는 연령별 비율을 알고 싶기 때문에 열(나라)마다 총합을 구하여 각각 나누어주면 연령별 비율을 알 수 있음
# .sum(axis=0) : 열 기준으로 더하기 # .div(axis=1) : 행 기준으로 나누기 netflix_age_country = netflix_age_country.div(netflix_age_country.sum(axis=0), axis=1) netflix_age_country
나라별 타겟팅하는 연령 시각화하여 인사이트 얻기
plt.figure(figsize=(15, 5)) # plt.matplotlib.colors.LinearSegmentedColormap.from_list( ) : 컬러맵 생성 cmap = plt.matplotlib.colors.LinearSegmentedColormap.from_list("", ['#221f1f', '#b20710','#f5f5f1']) # heatmap() : 직사각형 데이터를 색으로 행렬을 표현하여 시각화 # 열을 뜻하는 히트(heat)와 지도를 뜻하는 맵(map)을 결합시켜 색상으로 다양한 정보를 제공 # cmp : 시각화 시키는 컬러맵 # linewidth : 각 셀을 분할할 선의 너비 # annot : True라면 각 셀에 데이터 값 표시 # fmt : 문자열 형식화 코드 # .0% = X # .1% = X.x # .2% = X.xx sns.heatmap(netflix_age_country, cmap = cmap, linewidth=2.5, annot=True, fmt='.0%') plt.suptitle('Target ages proportion of total content by country', fontweight='bold', fontfamily='serif', fontsize=15) plt.title('Here we see interesting differences between countries. Most shows in South Korea are targeted to adults, for instance.',fontsize=12,fontfamily='serif') plt.show()
Netflix 워드 클라우드
-
워드 클라우드란, 문서의 키워드, 개념 등을 직관적으로 파악할 수 있도록 핵심 단어를 시각화하는 기법
-
from wordcloud import WordCloud: 워드 클라우드 생성에 필요한 모듈 -
from PIL import Image: 워드 클라우드를 원하는 형태로 그리기 위해 그림을 불러오는 패키지
-
WordCloud( ).generate(text): 선언해준 text에서 wordcloud를 생성text 변환: wordcolud에서 작동할 수 있도록 데이터프레임을 list로 1차 변환시키고 str(문자열)로 2차 변환mask: 단어를 그릴 위치 설정, 흰색(#FFFFFF) 항목은 마스킹된 것으로 간주plt.matplotlib.colors.LinearSegmentedColormap.from_list( ): 컬러맵 생성
-
plt.imshow( ): array에 색을 채워서 이미지로 표시 -
plt.axis('off'): 축 삭제
넷플릭스 데이터의 description 변수를 이용한 워드 클라우드 생성
# from wordcloud import WordCloud : 워드 클라우드 생성에 필요한 모듈 from wordcloud import WordCloud # from PIL import Image : 워드 클라우드를 원하는 형태로 그리기 위해 그림을 불러오는 패키지 from PIL import Image plt.figure(figsize=(15, 5)) # wordcolud에서 작동할 수 있도록 데이터프레임을 list로 1차 변환시키고 str(문자열)로 2차 변환 text = str(list(netflix['description'])) # mask : 단어를 그릴 위치 설정, 흰색(#FFFFFF) 항목은 마스킹된 것으로 간주 mask = np.array(Image.open('/content/netflix_logo.jpg')) # plt.matplotlib.colors.LinearSegmentedColormap.from_list( ) : 컬러맵 생성 cmap = plt.matplotlib.colors.LinearSegmentedColormap.from_list("", ['#221f1f', '#b20710']) # WordCloud( ).generate(text) : 선언해준 text에서 wordcloud를 생성 wordcloud = WordCloud(background_color = 'white', width = 1400, height = 1400, max_words = 170, mask = mask, colormap=cmap).generate(text) plt.suptitle('Keywords in the description of Movies and TV shows', fontweight='bold', fontfamily='serif', fontsize=15) # plt.imshow( ) : array에 색을 채워서 이미지로 표시 plt.imshow(wordcloud) # plt.axis('off') : 축 삭제 plt.axis('off') plt.show()

