kaggle survey
데이터 소개
- 데이터의 첫번째 Row에는 각 질문이 어떤 것이었는지 대한 내용이 적혀있다
라이브러리 및 데이터 불러오기
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns pd.options.display.max_rows = 100 import warnings warnings.filterwarnings('ignore') # 데이터 불러오기 survey = pd.read_csv('kaggle_survey_2021_responses.csv')
# 불러온 dataframe의 정보를 요약 정보를 확인한다 survey.info() # 데이터셋이 column이 너무 많아 일부만 사용 survey.iloc[:, :7]
한국사람 찾기
# 잘라온 데이터에서 한국은 어떤 텍스트로 표현이 되는지 호가인 survey.Q3.value_counts() survey.Q3.unique() # 한국 사람들을 불러오기 korean = survey.loc[survey.Q3 == "South Korea", :]
성별에 대한 분석
# 성별에 해당하는 column의 countplot을 그려보세요 plt.figure(figsize=(8,6)) sns.countplot(data=korean, x="Q2") plt.show()
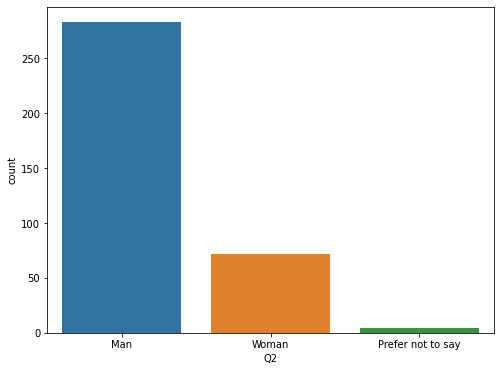
최종학력에 대한 분석
# 최종학력에 해당하는 column의 counplot을 그려보기 plt.figure(figsize=(8,6)) sns.countplot(data=korean, x="Q4") plt.show()
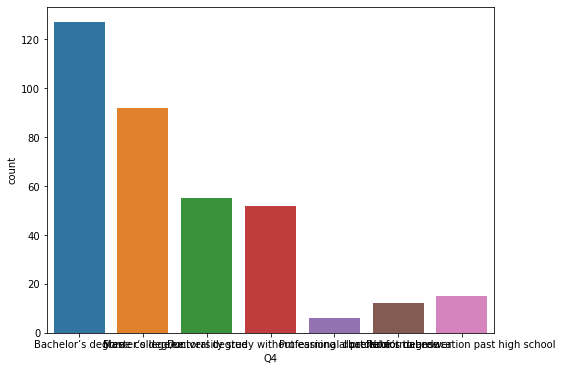
각 나라별 학력 통계 계산하기
- pivot table을 이용하여 나라별 통계 계산하기
pivot table 만들기
countries = pd.pivot_table(data=survey.loc[1:, ["Q3", "Q4"]], index='Q3', columns="Q4", aggfunc={"Q4":"count"}, fill_value=0)
특정 국가 가져오기
# 미국과 캐나다 가져오기 usa = countries.loc["United States of America"] canada = countries.loc["Canada"] display(usa) display(canada) plt.subplot(2,1,1) plt.title("the highest level of formal education in USA", fontsize=14) usa.plot(kind="barh") plt.subplot(2,1,2) plt.title("the highest level of formal education in Canada", fontsize=14) canada.plot(kind="barh") plt.show()

프로그래밍 언어 선호도 분석
- 어떤 column을 가져와야 하는지
- Q7과 관련된 column들은 어떻게 다 가져올지
프로그래밍 언어 선호도를 포함하는 column들을 불러오기
Q7_columns = survey.columns[survey.columns.str.startswith("Q7")] survey[["Q3"] + list(Q7_columns)]
언어별 정보가 합쳐진 DataFrame 만들기
Q7_list = [] for _, row in survey[Q7_columns][1:].iterrows(): #print(row[~row.isnull()].values) # 각 row별로 응답한 정보만 리스트로 출력 Q7_list.append(row[~row.isnull()].values) survey["PL"] = ["PL"] + Q7_list
한국인 응답자의 데이터만 뽑아보기
korean = survey.loc[survey.Q3 == "South Korea", ["Q3"] + list(Q7_columns)]
countplot 그리기
# x축을 프로그래밍 언어별로 정렬하여 counplot을 출력 Q7_list = [] for _, row in survey[Q7_columns][1:].iterrows(): #print(row[~row.isnull()].values) # 각 row별로 응답한 정보만 리스트로 출력 Q7_list.append(row[~row.isnull()].values.tolist()) Q7_list
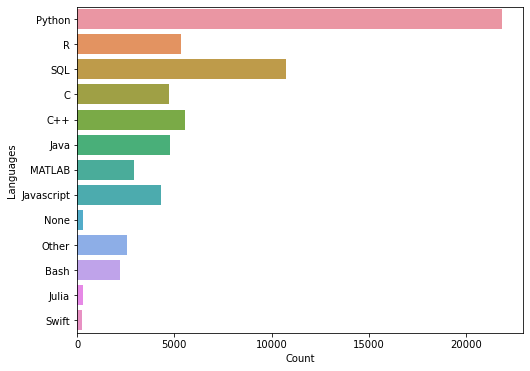
from collections import Counter q7_data = [] for row in Q7_list: q7_data = q7_data + row counter = Counter(q7_data) df = pd.DataFrame({'Languages' : counter.keys(),"Count" : counter.values()}) plt.figure(figsize=(8,6)) sns.barplot(data=df, x="Count", y="Languages") plt.show()

가보자가보자~