정규화 ?
데이터의 값을 특정 범위로 변환하거나, 데이터의 중복과 불일치를 제거하는 작업이다.
목적
- 데이터의 중복과 불일치를 제거하여 데이터를 쉽게 소비하고 분석할 수 있도록 한다.
- 데이터의 스케일을 조정하여 범위를 일치시킨다
- 데이터의 분포를 정규분포와 같은 특정 분포를 따르도록 값을 조정한다.
- 머신 러닝 모델의 과적합을 수정하여 일반화 가능성을 높인다.
=> 정규화 실습해보자.
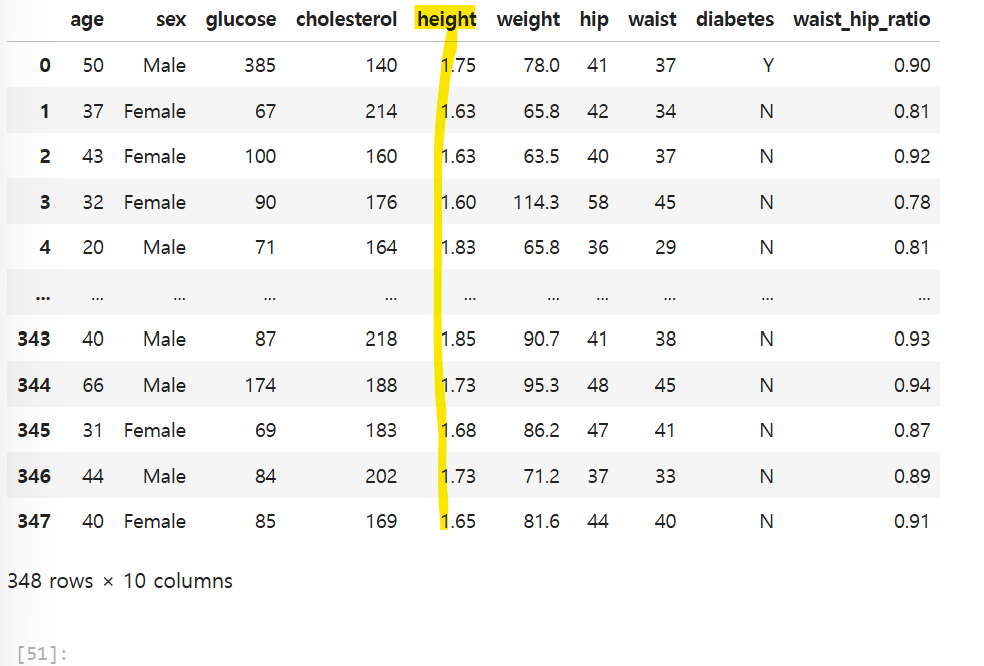
Hight컬럼에 대해 정규화를 진행해볼건데, 정규화 식은
원본 데이터 - 최소값 / 최대값 - 최소값
이다.
먼저 선언을 해주고,
import pandas as pd
patient_df = pd.read_csv('Data/patient.csv')
patient_df
정규화 식에 따라 연산을 수행한다.
patient_df['height'] = (patient_df['height'] - patient_df['height'].min()) / \
(patient_df['height'].max() - patient_df['height'].min())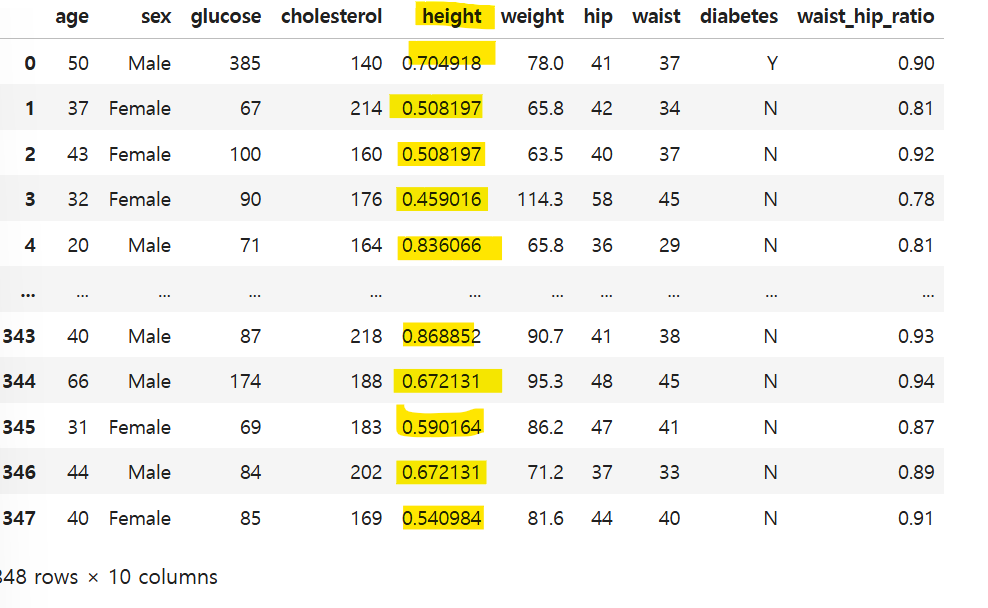
통계정보로도 확인할 수 있다.
patient_df['height'].describe()
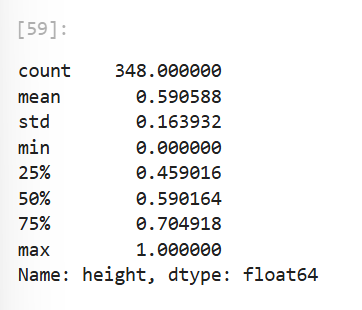
=> 정규화가 정상적으로 수행된 것을 확인할 수 있다.

멋있는 어른이 되고싶은 정만이의 벨로그