데이터분석
1.[Python] 숫자형 연산(floor division, round)

3월부터 국비훈련으로 4주간 파이썬 데이터 분석 교육을 수강하고 있다.앞으로 수강 내용을 따라가며 학습한 기록을 남겨보려 한다.\* floor division : 기호로는 "//"를 사용해서 연산에 이용한다.정수부분만 출력되기 때문에 이에 유의해야한다.\* round:
2.[Python] 문자열 출력 오류
Python에서 문자열을 출력할때 할 수 있는 방법은 두가지가 있다."" : 큰 따옴표 사용'' : 작은 따옴표 사용여기서 유의해야할 점은 시작한 따옴표와 끝 따옴표가 같아야한다는 점이다.하지만, 출력문에 "" 와 ''을 같이 써야하는 경우에 대해 알아보자.위 실행 예
3.[Python] 형 변환
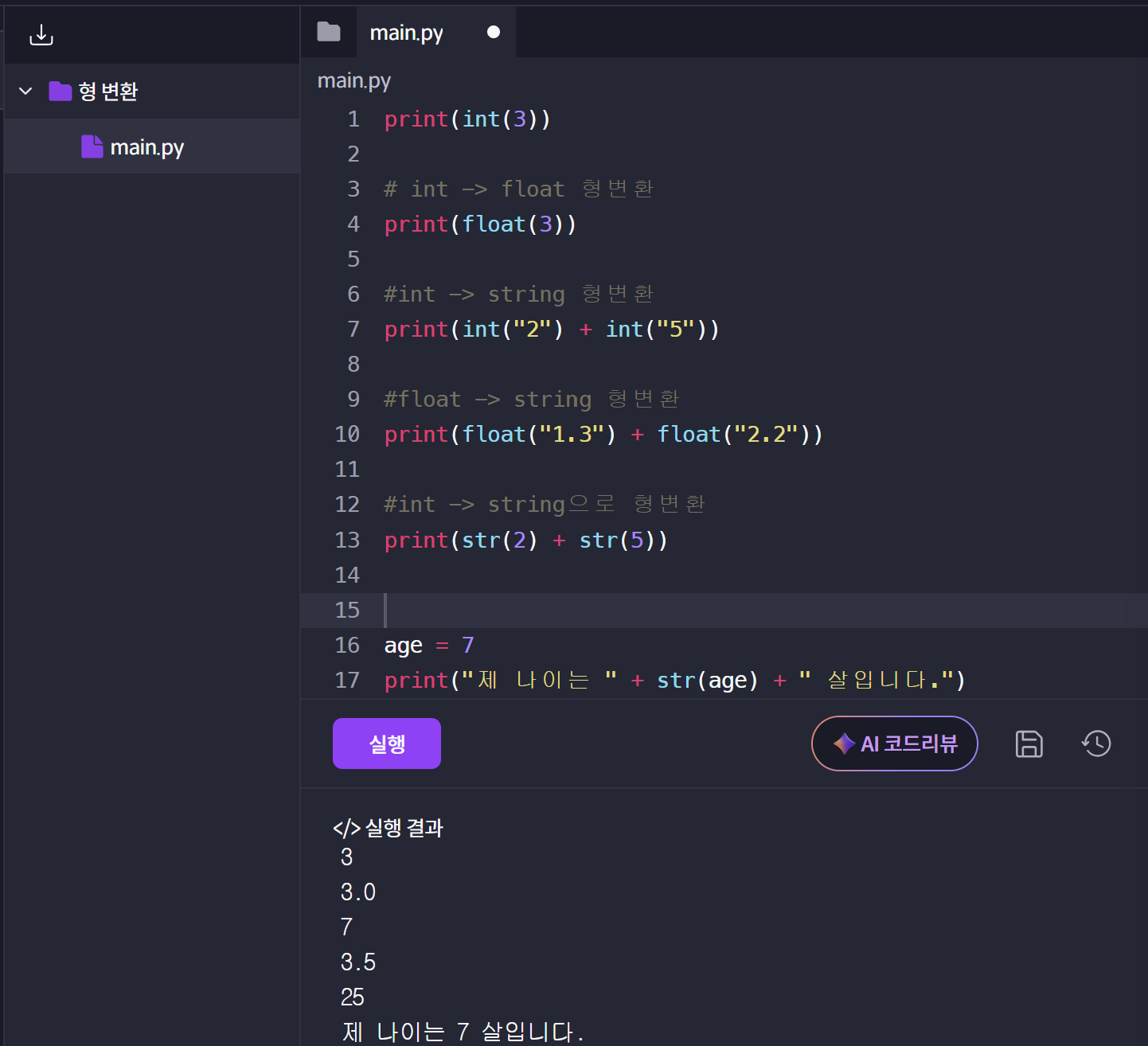
: 다른 데이터 타입을 원하는 타입으로 변환시키는 것을 의미한다.형 변환 종류 정수 변환 - int()실수 변환 - float()문자열 변환 - str()문자 변환 - chr()불리언 변환 - bool()형변환 코드 예제 output주의 할 부분\-> hello wor
4.[Python] end 옵션, file 옵션, format() 메소드, %기호
파이썬 완전 기초, print 사용법 등을 학습한 내용이다.
5.[Python] 정렬, 포맷팅
파이썬 3가지 Print Formatting, 정렬에 대해 학습했다.
6.[Python] 변수 선언
파이썬 변수 선언과 동시 선언, 오브젝트 참조에 대해 학습하였다.
7.[Python] 문자열 len(), 이스케이프 문자, 탭, 줄바꿈, 연산, 문자열 함수, 슬라이싱
8.[Python] 리스트 인덱싱, 슬라이싱, 수정, 삭제
9.[Python] 튜플 선언, 인덱싱, 슬라이싱, 연산, 패킹&언팩킹
10.[Python] 딕셔너리 선언, dict_keys, dict_values, dict_items, in 연산자
11.[Python] 옵셔널 파라미터
: 파라미터에 기본값을 설정해 두면 함수를 호출할 떄 파라미터에 꼭 값을 넘겨주지 않아도 되는 파라미터. 필수가 아니다.예시 1.내 이름은 오정민나이는 1살국적은 미국내 이름은 오정민나이는 1살국적은 한국def hello(name, city="한국", age):
12.[Numpy] 메소드 (.zeros, .arange, .size, .shape ... )
Numerical Python을 줄여서 Numpy라고 하며, 넘파이는 수학 연산을 위한 파이썬 패키지이다.행렬이나 대규모 다차원 배열을 쉽게 처리할 수 있도록 강력한 기능을 제공한다. \- numpy import \- numpy shapenp.shape로 해당 arra
13.[Numpy] 슬라이싱, 인덱싱
14.[Numpy] 실습- 비트코인 가격 정보 탐색하기
문제 bitcoin_array에는 비트코인 투자 열풍이 불었던 2017년의 월별 비트코인 가격이 들어있습니다. 여기서 3분기(7월~9월)의 비트코인 가격을 출력하세요.답
15.[Numpy] 2차원 배열 슬라이싱, 인덱싱
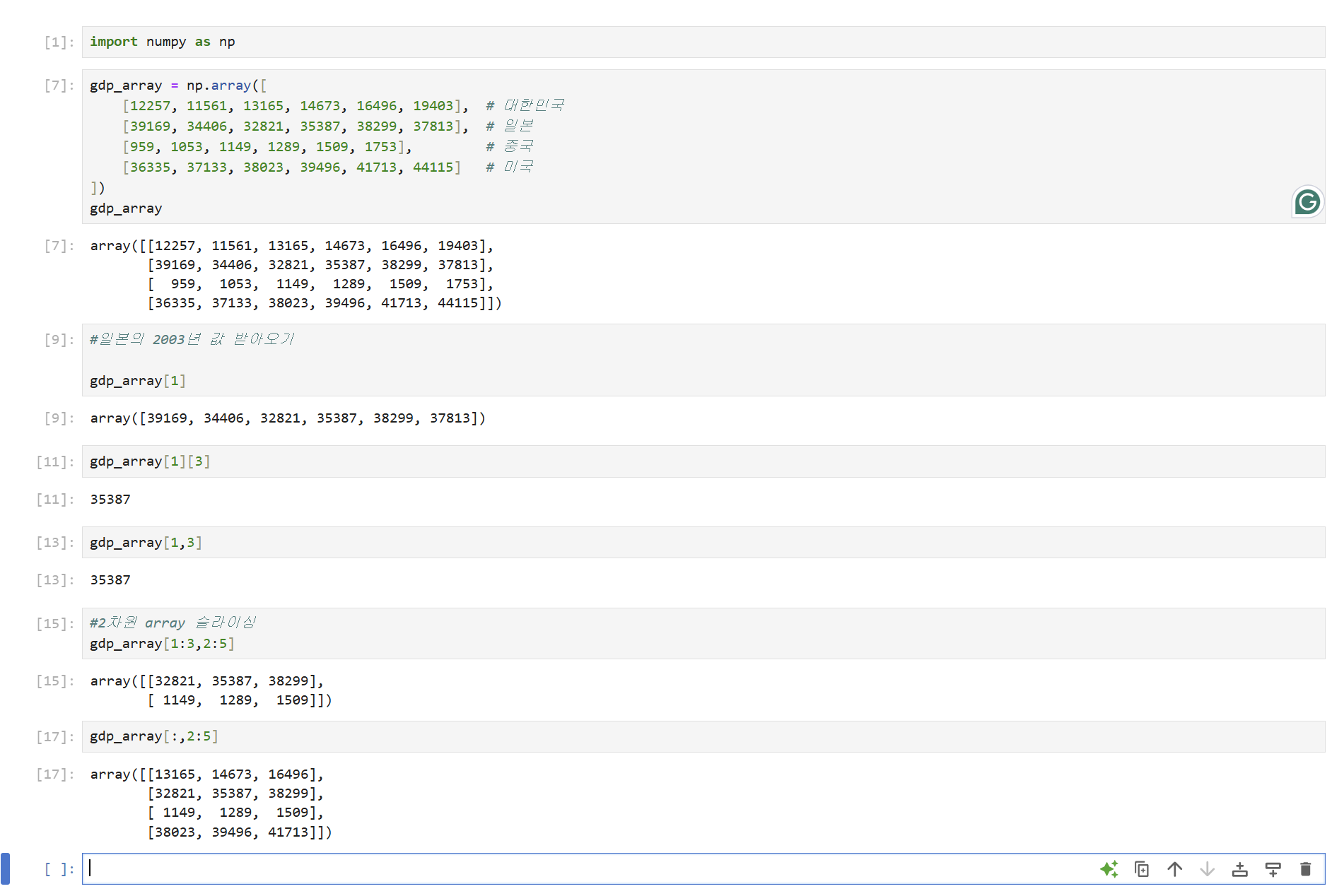
예제
16.[Numpy] 실습- 비트코인 가격 정보 탐색하기2
문제bitcoin_array는 2017년 월별 비트코인 가격과 거래량 정보가 들어 있는 2차원 array입니다. 첫 번째 로우에는 가격 정보, 두 번째 로우에는 거래량(천만 기준) 정보가 들어 있습니다. 여기서 7월의 비트코인 거래량 정보를 출력하세요.답
17.[Numpy] 실습- 쇼핑몰 매출액 계산하기
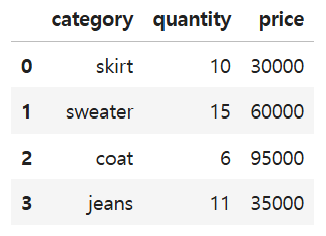
문제소원이는 부업으로 인터넷 쇼핑몰 운영을 시작했습니다. 가격은 price_array, 판매 수량은 quantity_array에 저장되어있습니다. 치마, 티셔츠, 원피스, 스웨터, 코트, 청바지, 신발 순서대로 정보가 들어 있다고 합니다. 각 상품별 매출액을 계산하세요
18.[Matplotlib] 그래프 그리기
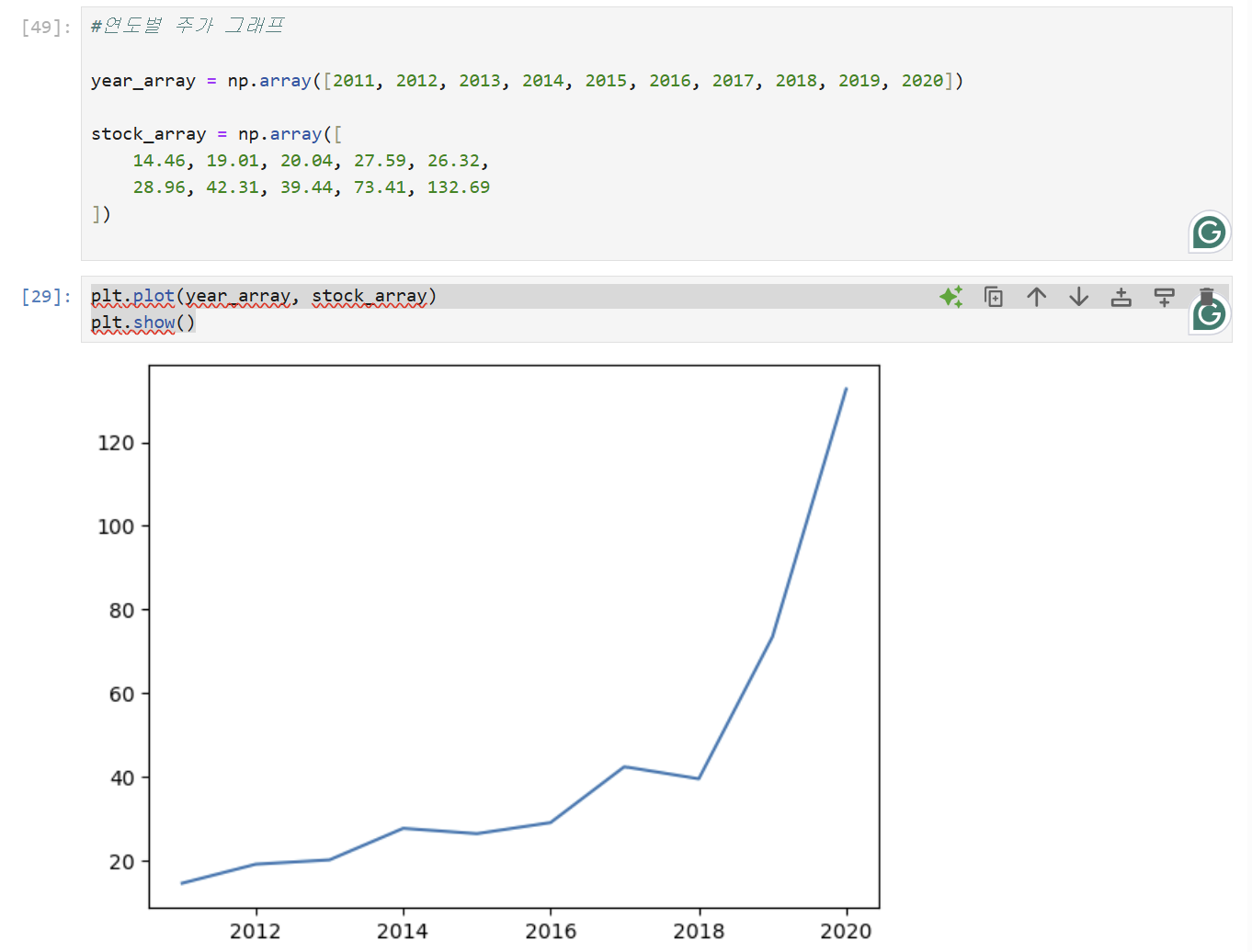
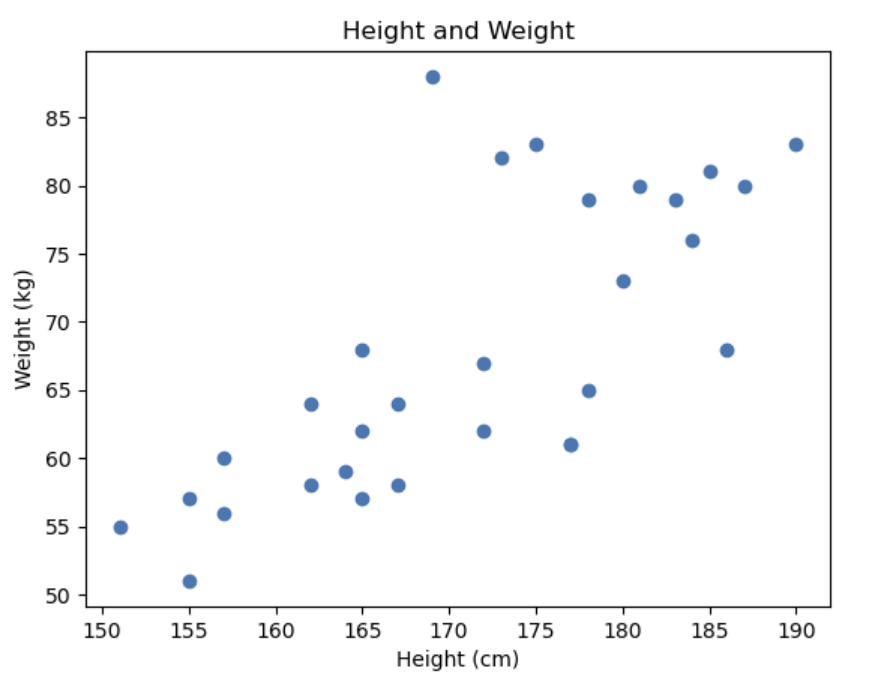
: 파이썬에서 데이터를 시각화해주는 라이브러리이다.예시 1. 연도별 주가 그래프 시각화하기예시 2. 반장선거 - 막대 그래프 시각화하기 예시 3 . 키와 몸무게에 따른 선점도 그래프
19.[Matplotlib] 실습- 쇼핑몰 매출액 데이터 시각화
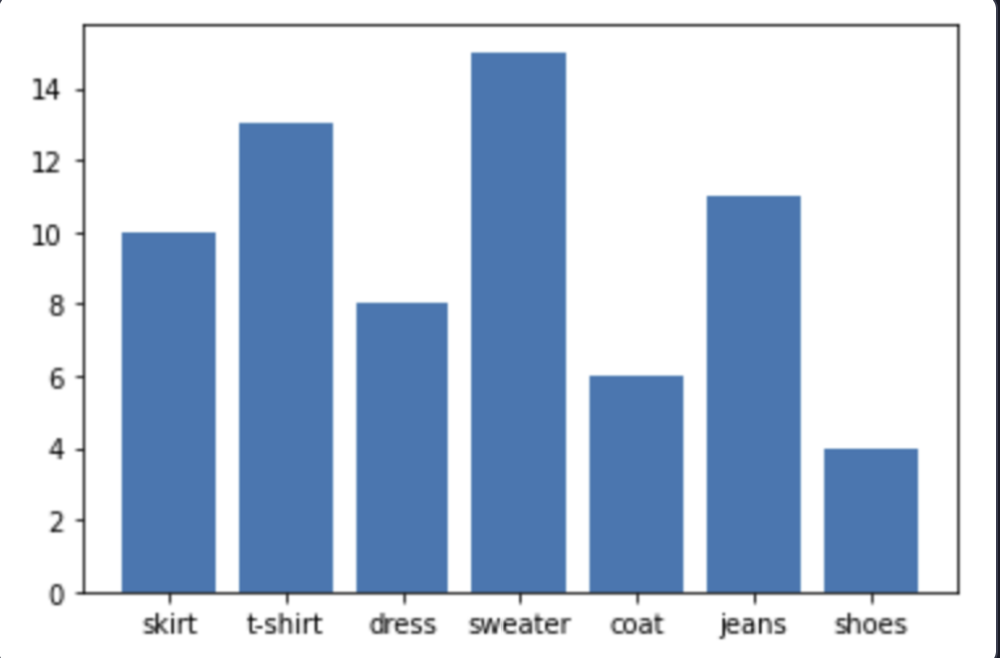
소원이는 운영 중인 인터넷 쇼핑몰에서 어떤 상품들이 잘 팔리는지 확인해 보려고 합니다. 각 품목별 판매수량을 한눈에 볼 수 있도록 아래와 같은 막대 그래프를 그려 주세요.
20.[Matplotlib] 그래프 꾸미기
그래프 색깔 변경하기기존 그래프 색 변경 => 위 코드처럼 RGB 튜플이나, HEX 코드, HTML에서 사용하는 색이름도 입력 가능하다. 아래 색상표를 참고하자. 그래프 모양 변경하기 => 위 코드처럼 'marker = '를 통해 그래프 모양 변경이 가능하다. 아래 표
21.[Matplotlib] 실습- 연봉 데이터 시각화
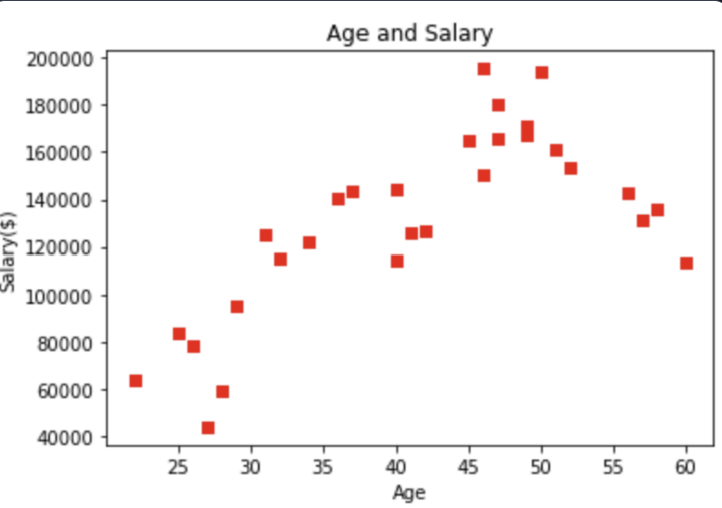
어떤 회사 직원들의 나이와 연봉 정보를 시각화하자. 아래 요구 사항을 모두 지켜서 실습 결과와 동일한 그래프를 그려라.그래프 제목: Age and Salaryx축 제목: Agey축 제목: Salary($)점의 색깔: 빨간색(red)점의 모양: 네모답
22.[Matplotlib] 한글 깨짐 오류 해결법
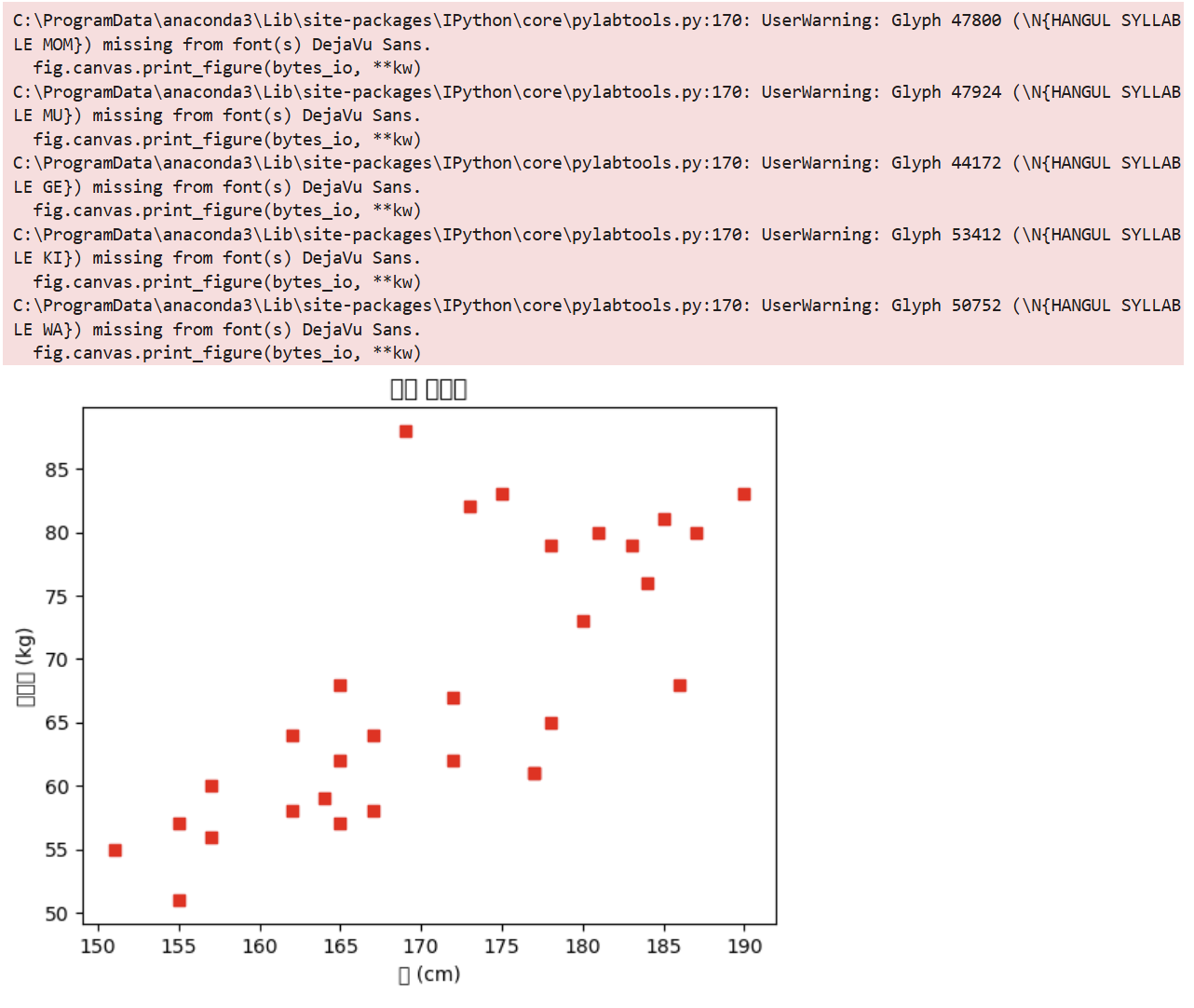
\* 오류 현상=> 위와 같이 x축과 y축을 한글로 작성하면 오류가 뜨면서 정상적으로 그래프가 출력되지 않는 문제가 발생한다.\* 해결법 윈도우인 경우맥북인 경우 => 그래프 정상 출력 확인
23.[Pandas] 정의, numpy array 단점, DataFrame 자료형
빠르고 유연하며 표현이 풍부한 데이터 구조를 제공하는 Python 패키지.파이썬에서 사용하는 데이터 분석 라이브러리이다.: Numpy는 복잡한 수학 연산을 할 때 주로 사용하고,Pandas는 표 형태의 데이터를 간편하게 다루고 싶은 경우에 사용한다.: Numpy에는 P
24.[Pandas] 데이터 불러오기
실제 컴퓨터에 저장되어있는 데이터를 pandas를 이용해 불러오는 실습을 진행하자.나는 c드라이브 내에 "burger.csv" 파일을 담아놨다.파일 데이터는 Jupyter Notebook에서도 확인이 가능하다.=> 성공적으로 실제 저장되어있는 데이터를 불러왔다.
25.[Pandas] iloc, loc으로 원하는 데이터 확인하기
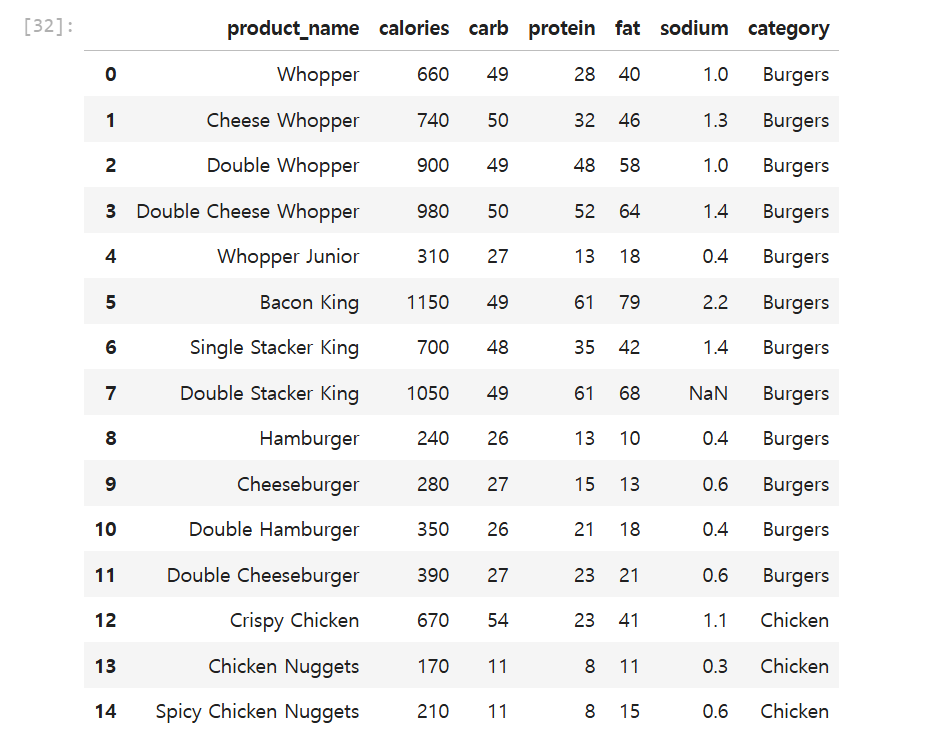
lioc : 데이터프레임의 행이나 컬럼에 인덱스 값으로 접근한다.loc : 데이터프레임의 행이나 컬럼에 label이나 boolean array로 접근한다.iloc 예시위 데이터의 Double Whopper와 Double Cheese Whopper의 Carb, Prote
26.[Pandas] 불린 인덱싱, 필터링 분석
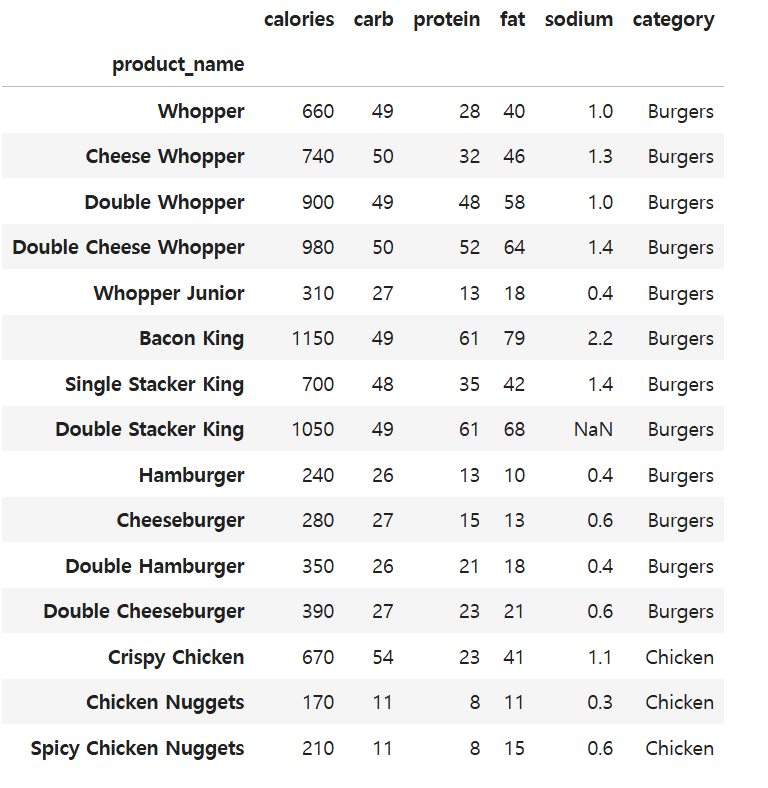
불린 인덱싱을 통한 필터링 분석을 실습해보았다.아래는 원본 데이터이다.=> 여기서 칼로리가 500 미만인 데이터가 뭐가 있는지 확인한다.True인 데이터들만 데이터를 추출하려면?\* 답!! 원하는 컬럼만 추출하고 싶다면?
27.[Pandas] 데이터 수정 및 추가하기
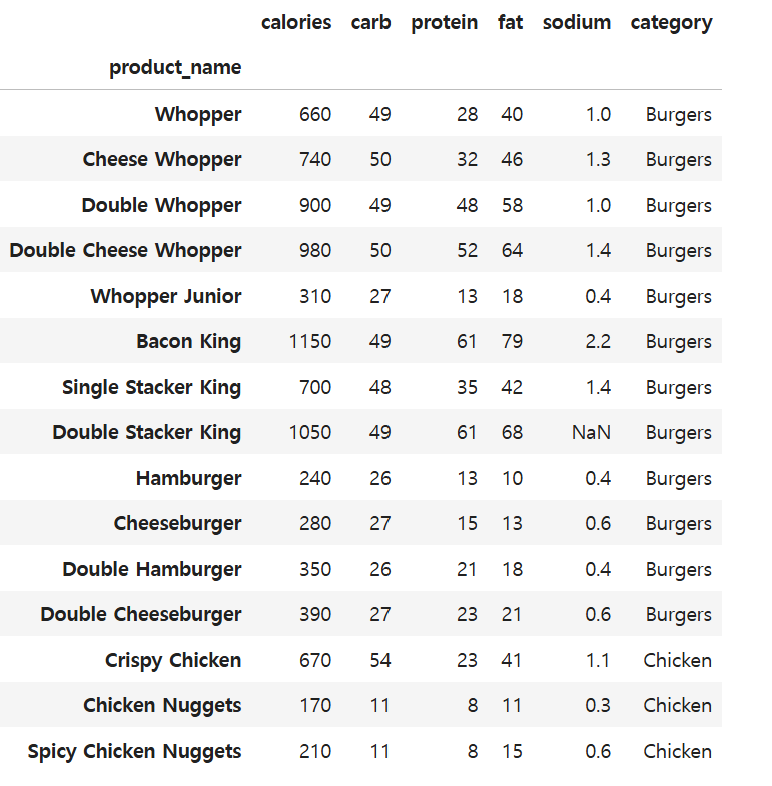
=> Double Stacker King의 누락된 값을 수정해본다.로우 한 줄 수정하기
28.[데이터분석] 박스 플롯과 이상점
통계 정보와 분포를 시각적으로 보여주는 시각화 차트.막대 그래프와 비슷하게 x축에는 대상을 두고 y축에 값을 두어 x축 대상 별로 y축 대표 값의 크기 차이를 보여줄 수 있다.특징 데이터의 분포와 이상치를 동시에 보여준다. 서로 다른 데이터군을 쉽게 비교할 수 있다.데
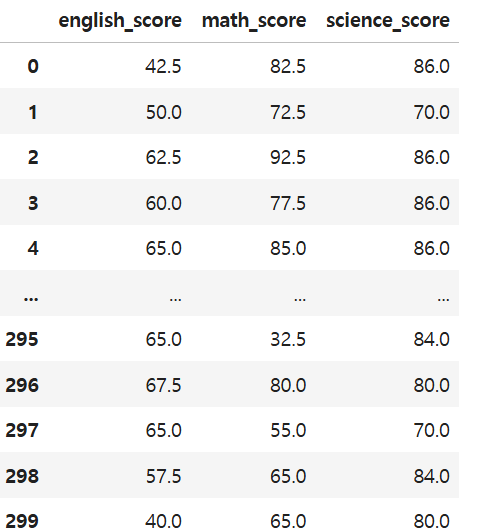
29.[실습] 중고차 데이터 분석 1
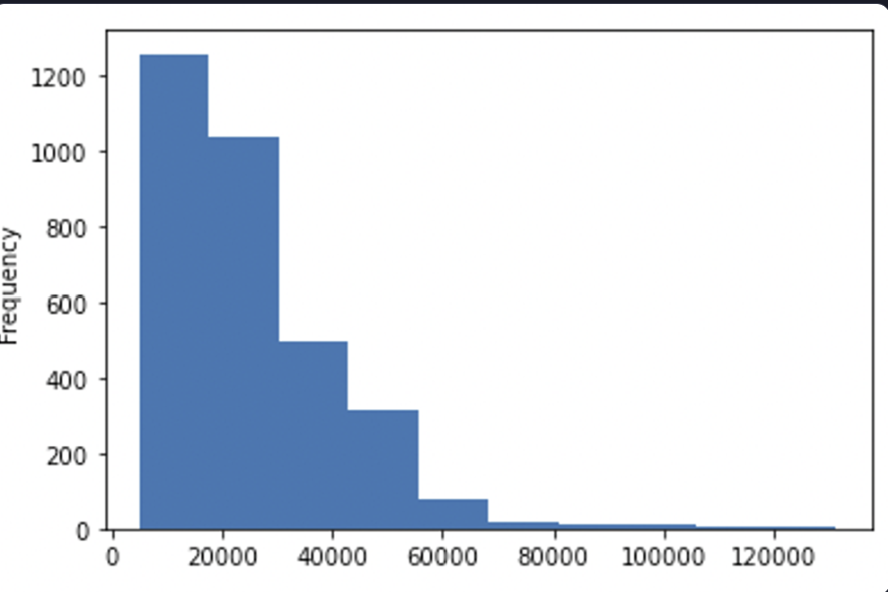
윤수는 오랜 취업 준비 끝에 중고차 거래 플랫폼에 취업했다고 한다. 첫 업무로 현재 판매되고 있는 중고차 데이터를 분석해 보려고 하는데, 현대자동차의 가격대 분포를 한눈에 볼 수 있도록 아래와 같이 히스토그램(막대 10개)을 그려라.원본 데이터 불린 인덱싱으로 제조사가
30.[Seaborn] set_theme() 그래프 커스터마이징
스타일 설정하기아래와 같이 set_theme() 함수를 사용하면, 따로 파라미터 값을 넘겨준 게 없는데도 자동으로 그래프의 배경이 흰 가로선이 있는 회색 배경으로 설정된다. style이라는 파라미터의 기본값이 darkgrid라는 값으로 되어 있기 때문이다.style 파
31.[Seaborn] 실습- 공유 자전거 데이터 1
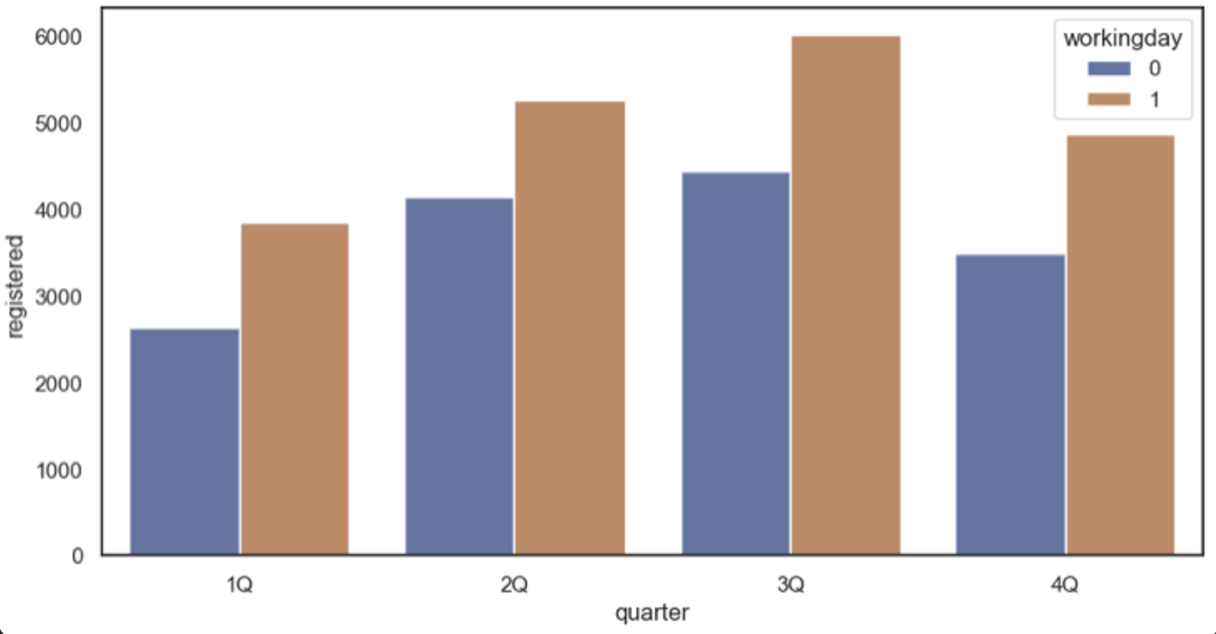
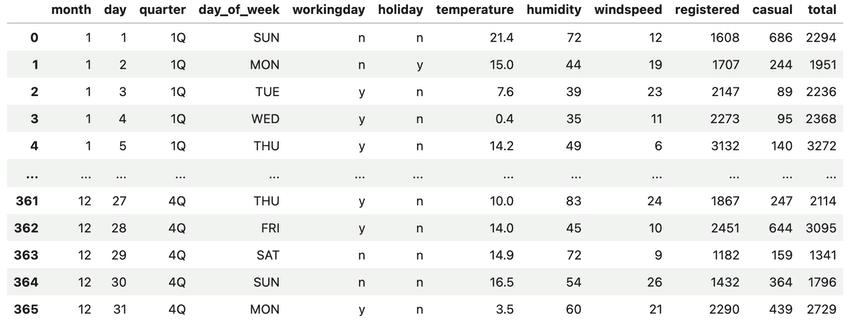
분기별로 정기권을 이용하는 사람들의 평균 대여 건수를 막대 그래프로 그려보자.아래와 같이 영업일과 영업일이 아닌 날을 한눈에 비교할 수 있게 코드를 작성하라.seaborn의 barplot() 함수를 사용막대 위에 있는 검은색 선을 안 보이게 하기 위해 errorbar라
32.[Seaborn] 데이터 분포 시각화, 산점도, stripplot, swarmplot
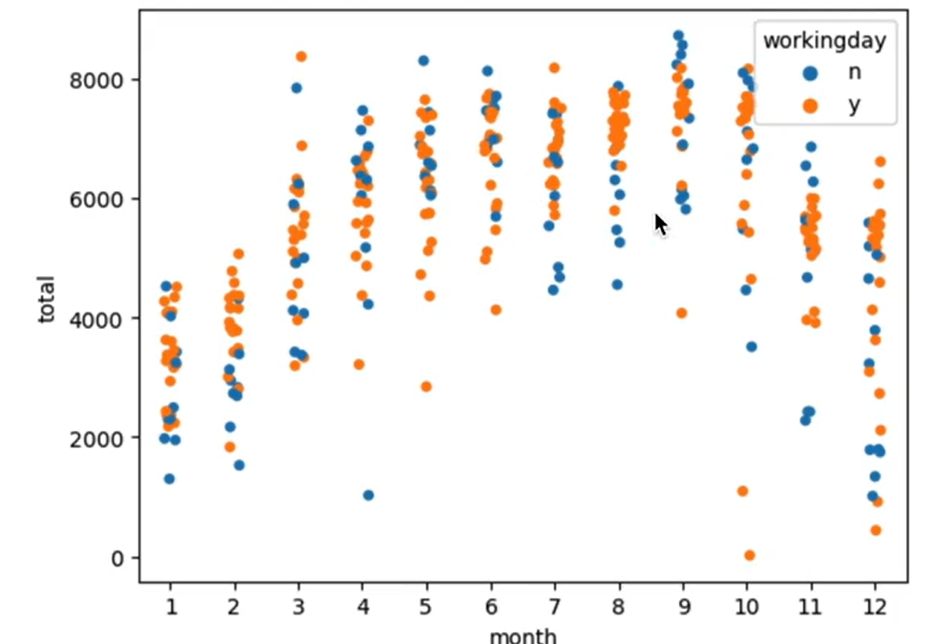
[stripplot] > 데이터 포인트가 중복되어 범주별 분포를 그린다. [swarmplot] > 위 그래프는 데이터의 분산까지 고려하여, 데이터 포인트가 서로 중복되지 않도록 그린다. 데이터가 퍼져 있는 정도를 입체적으로 볼 수 있다. 아래 데이터를 이용해보자.
33.[Seaborn] 데이터 분포 시각화2, Violin Plot
=> 가로축의 컬럼 순서를 변경하고 싶을 때 order = \[]박스 플롯과 동일하게 일변량, 연속형 데이터의 분포를 설명하기 위해 사용되는 그래프=> 가운데 흰 점 : 중앙값, 가운데 굵은 선 : IQR , 굵은 선의 양 끝 : 각각 1사분위, 3사분위 수, 박스 플
34.[Pandas] DataFrame 기본기, info(), describe(), head(), tail(), 정렬
info()전체 레코드 수, null값, 컬럼 수, 데이터 타입 등을 확인할 때 사용합니다 .데이터프레임을 구성하는 행과 열의 크기, 컬럼명, 컬럼을 구성하는 값의 자료형 등을 출력해볼 수 있습니다 .describe() 데이터 프레임의 기본 통계량을 확인할 때 사용합니
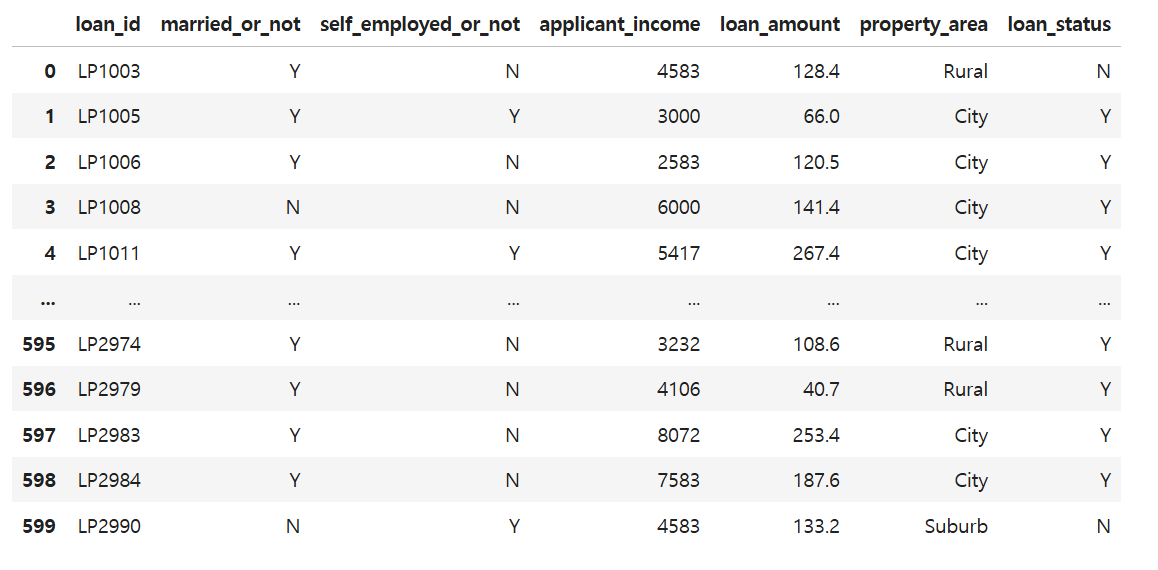
35.[Pandas] 실습- 불린 인덱싱
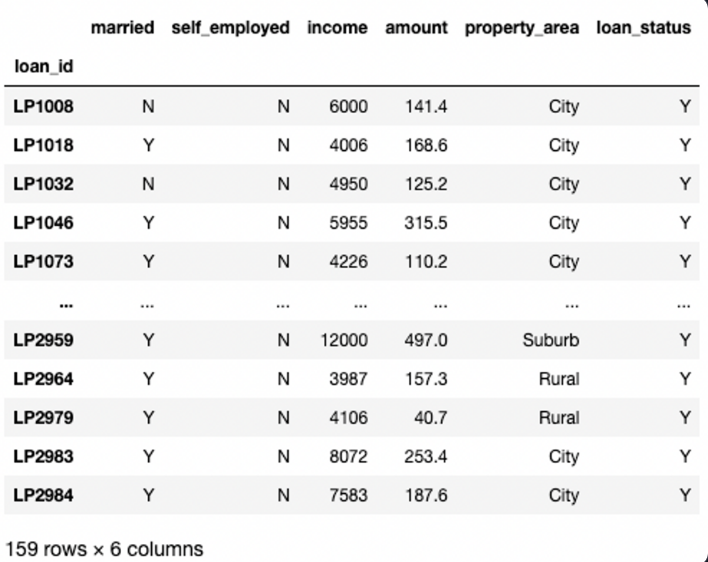
대출 신청자들을 여러 개의 그룹으로 나누려고 합니다. 일단 대출이 승낙된 사람들 중에서 자영업자가 아니고, 수입이 중간값 이상인 사람들을 추출하려고 합니다.불린 인덱싱을 사용해서 세 가지 조건을 모두 만족하는 데이터를 group1이라는 변수에 저장해 주세요.
36.[Pandas] 데이터 전처리 - 결측값 찾기, 처리하기
데이터 전처리 과정에서의 결측값을 찾고 처리하는 과정을 학습했다.알려지지 않고, 수집되지 않거나 잘못 입력된 데이터 세트의 값. 데이터에 값이 없는 것을 뜻하며 줄여서 NA라고도 하고, Null 이라는 표현도 쓴다.데이터 분석에서의 결측값이란 ?결측치를 다 제거하면 막
37.[실습] - 결측값 처리하기
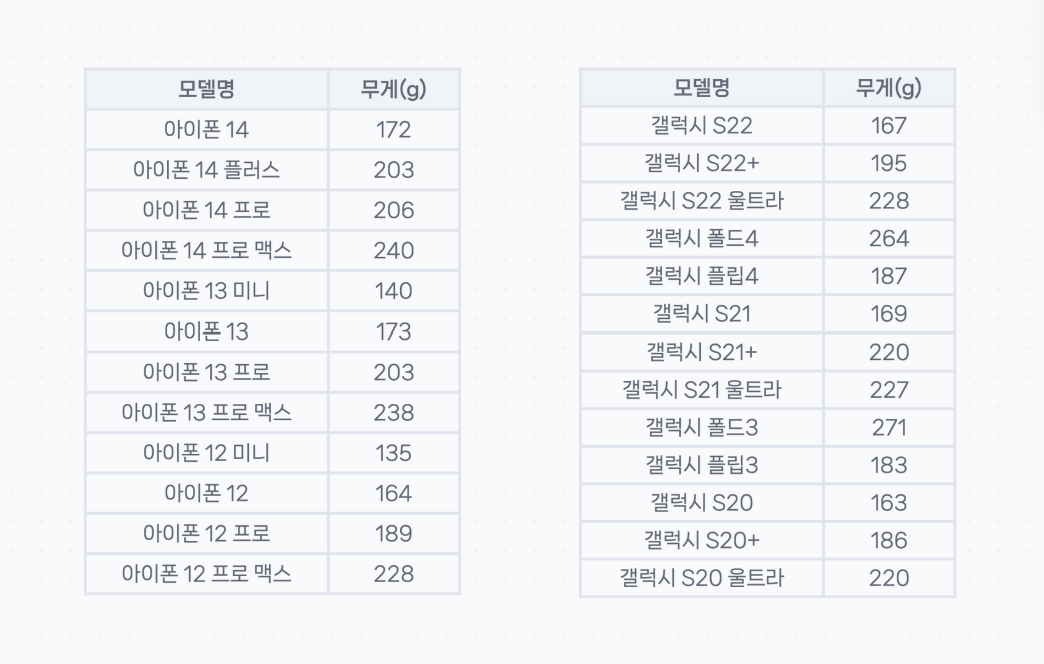
효준이는 새로운 스마트폰을 구입하기 위해 애플과 삼성의 스마트폰 데이터를 수집했습니다. 그런데 실수로 특정 모델의 무게를 입력하는 것을 깜빡했다고 합니다.다행히 한 가지 모델만 누락되어 있고, 모델명이 같으면 용량이나 색상과 관계없이 무게가 동일하다고 합니다. 아래 표
38.[Pandas] 데이터전처리- 중복값 찾기, 처리하기
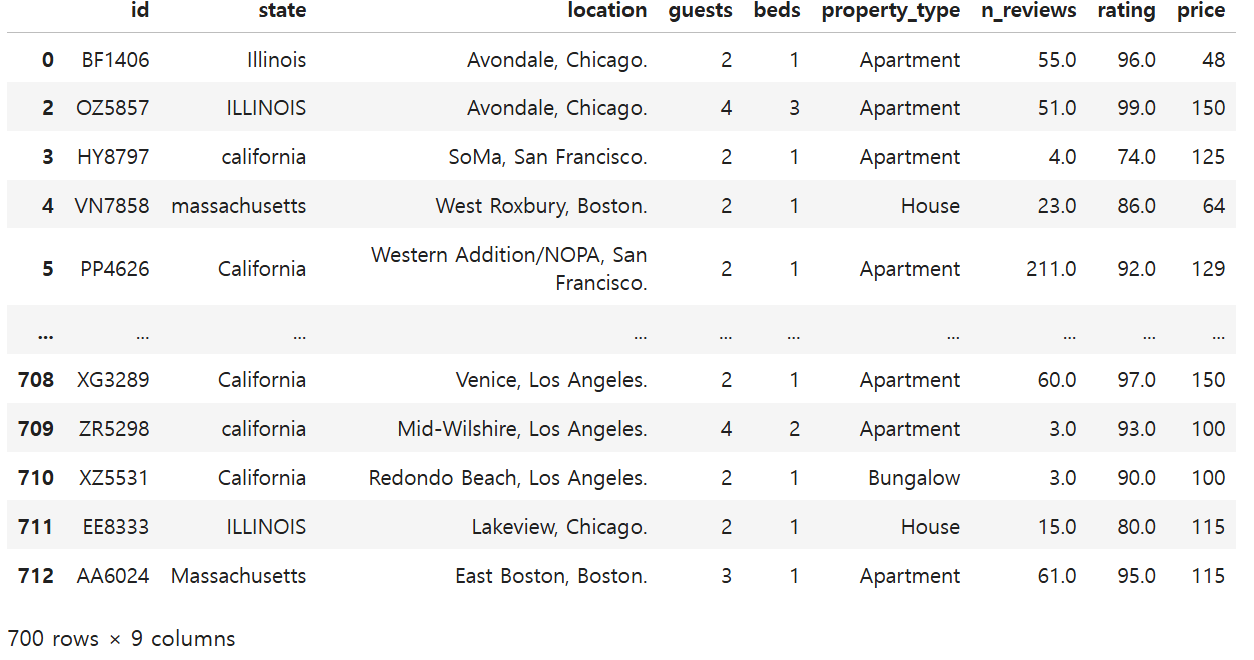
데이터의 중복값을 찾고 처리하는 방법에 대해 학습했다.\* 원본 데이터 중복값 찾기 중복된 로우 수 확인하기=> 2 컬럼별 중복값 찾기 (예.id)모든 중복값들을 확인하기.\* 중복값 삭제( drop_duplicates())중복값에서 가장 첫번째만 남기고 삭제하는 경우
39.[Pandas] 데이터전처리- 이상값 찾기, 처리하기
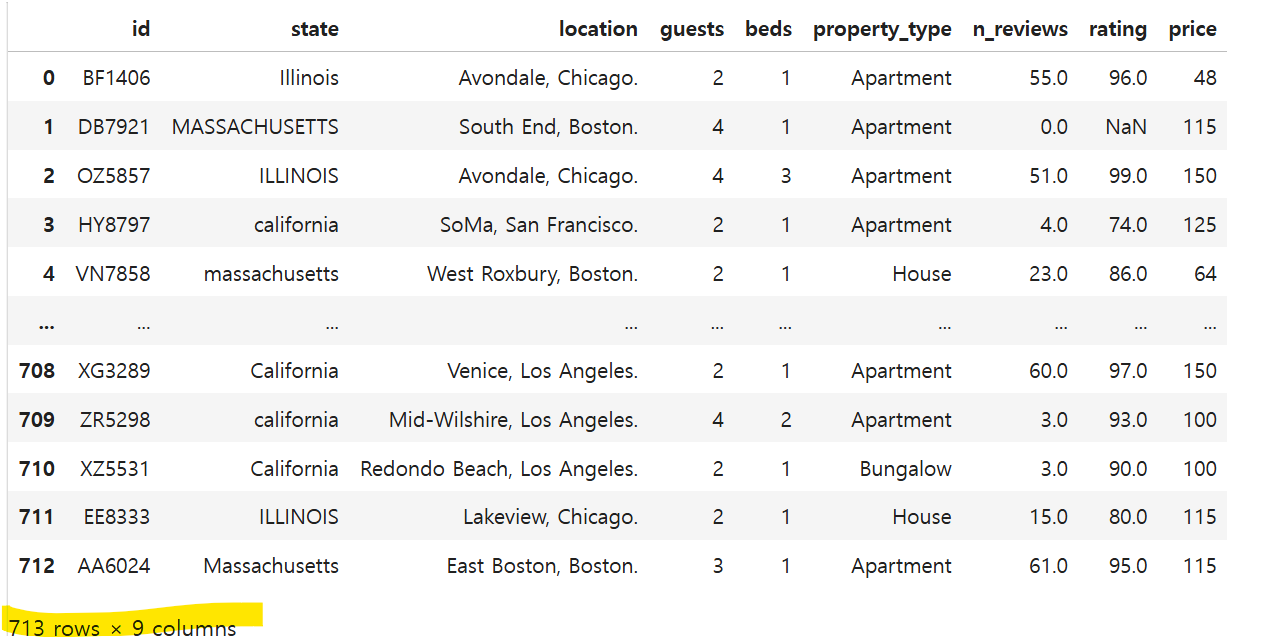
이상값을 찾고 처리하는 방법에 대해 학습하였다.일반적인 데이터 분포에서 벗어난 값, 즉 다른 데이터와 차이가 큰 값을 가진 데이터 포인트.극단적으로 크거나 작은 값일 수 있다.데이터분석에서의 이상값처리법 \- 결측값으로 대체한 다음 결측값 처리하기 \- 이상치를 제
40.[Pandas] 대소문자 처리하기
대문자를 포함한 String 데이터를 모두 소문자로 바꾸는 함수 소문자를 포함한 String 데이터를 모두 대문자로 바꾸는 함수문자열의 첫글자는 대문자, 나머지는 소문자로 바꾸는 함수
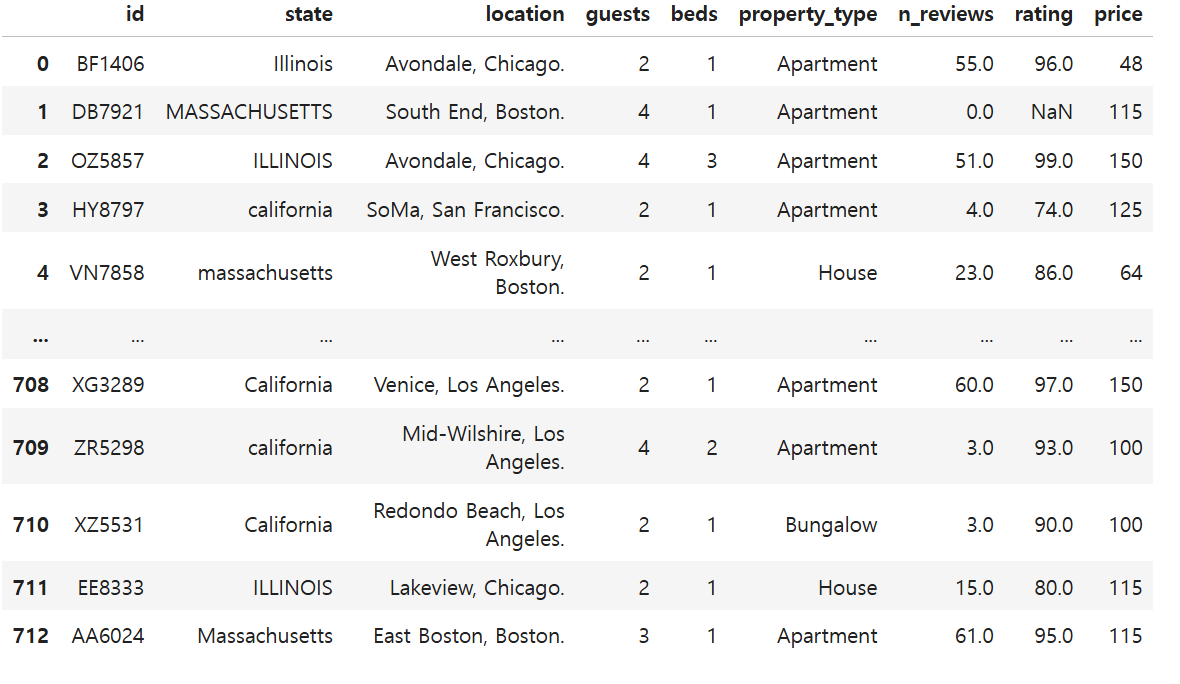
41.[Pandas] 문자열 분리하기
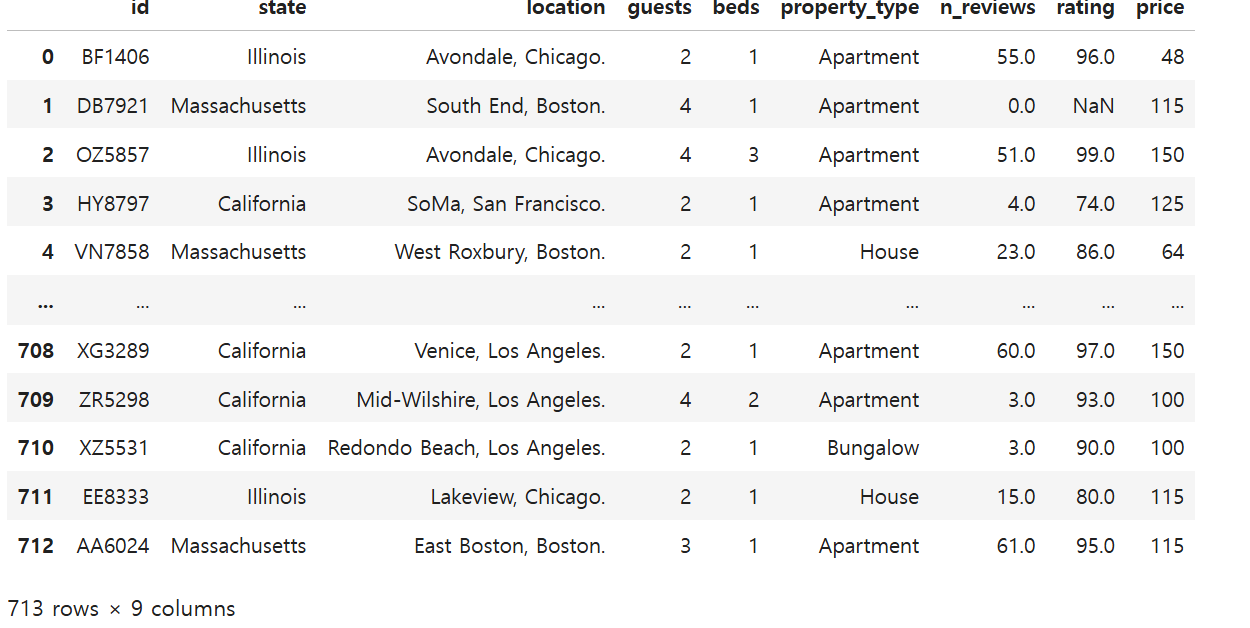
\- 원본 데이터 => 'location'의 데이터 값이 2개이므로 이를 분리하려면?우선, 콤마(,)로 구분되어있기에 값들을 가져와본다.각각 인덱스 0,1 번이므로 값들을 분리해서 새로운 컬럼에 추가한다.업로드중..이제 기존 location 컬럼을 삭제한다.업로드중..
42.[Pandas] 실습- 문자 데이터 처리하기
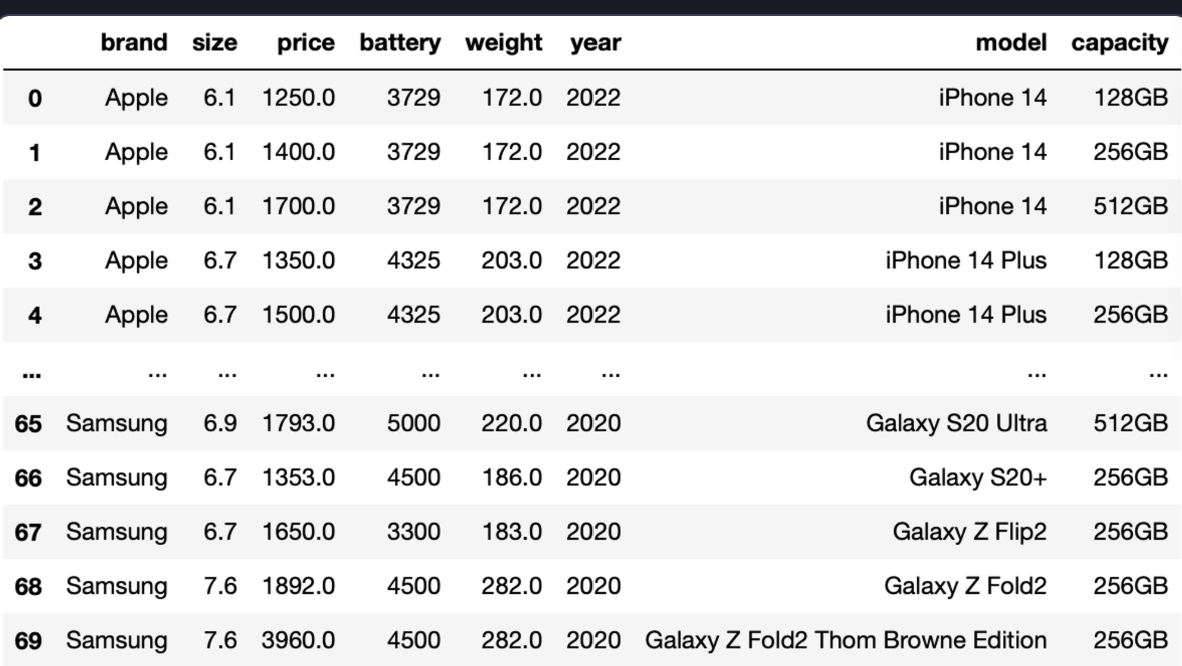
brand 컬럼에 저장된 제조사명의 대소문자 표기를 통일해 주세요. 첫 글자는 대문자로, 나머지 글자는 소문자로 바꿔 주시면 됩니다.name 컬럼에는 iPhone 14 Pro (256GB)와 같이 스마트폰의 모델명(iPhone 14 Pro)과 용량(256GB) 정보가
43.[Pandas] 실습- 데이터프레임 사칙연산
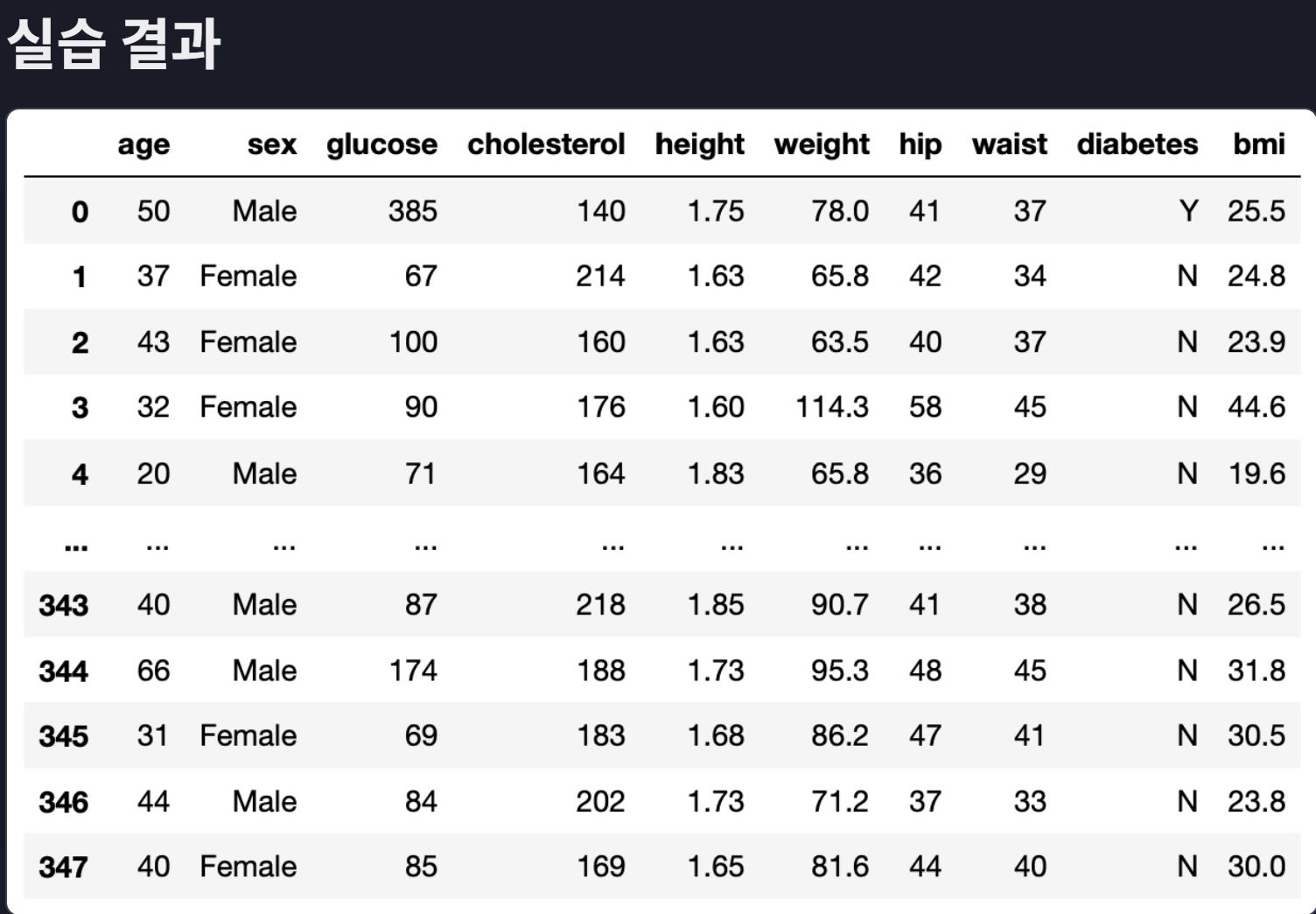
비만도를 나타내는 지표로 'BMI(Body Mass Index)'라는 것도 많이 사용합니다. BMI를 계산하려면 몸무게(kg)를 키(m)의 제곱으로 나눈 값입니다.예를 들어, 키가 180cm이고, 몸무게가 70kg인 사람의 BMI는 70을 1.8의 제곱으로 나눈 값인
44.[Pandas] 정규화(Normalization)
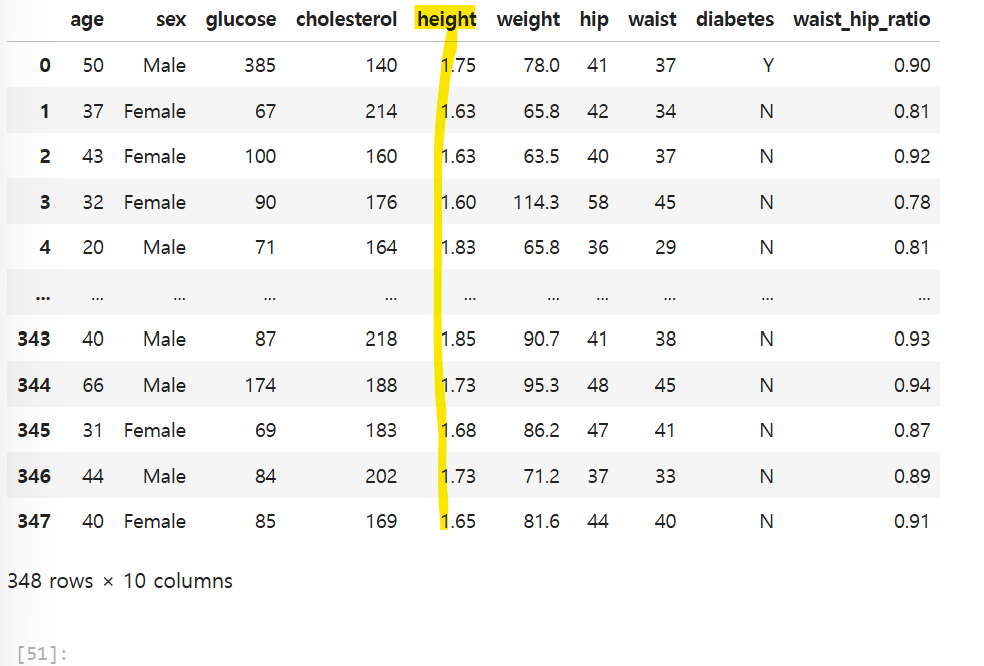
데이터의 값을 특정 범위로 변환하거나, 데이터의 중복과 불일치를 제거하는 작업이다. 목적데이터의 중복과 불일치를 제거하여 데이터를 쉽게 소비하고 분석할 수 있도록 한다. 데이터의 스케일을 조정하여 범위를 일치시킨다데이터의 분포를 정규분포와 같은 특정 분포를 따르도록 값
45.[Pandas] 표준화(Standardization)
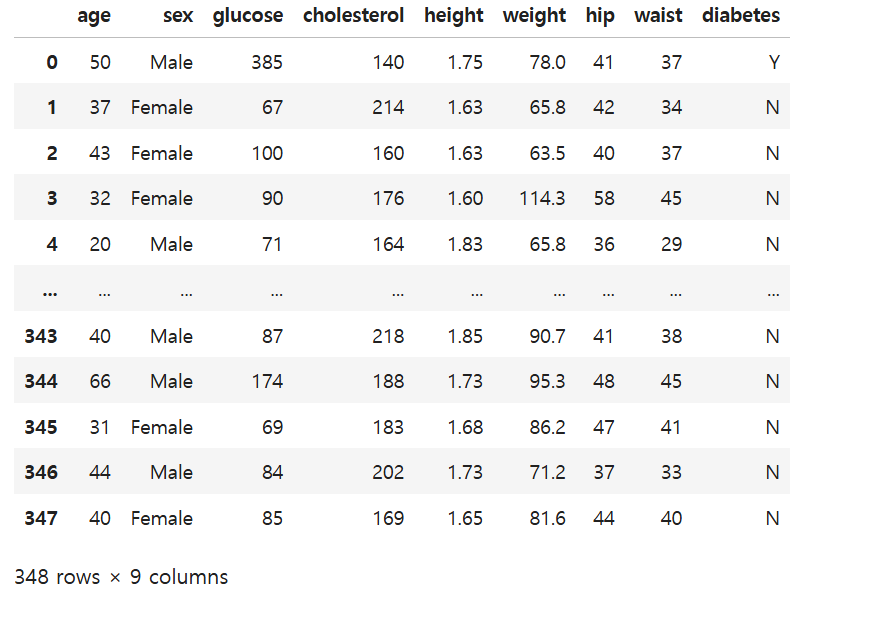
정규분포의 형태로 값의 범위를 바꿔준다는 의미이다. 즉, 평균은 0, 표준편차는 1이 되도록 값을 치환하는 것이다.아래 데이터로 표준화 실습을 해보자.원본 값 - 평균 / 표준편차문제 weight 컬럼에 있는 값들이 평균은 0, 표준편차는 1이 되도록 표준화(Stand
46.[국비교육] ★파이썬 데이터 분석과정 수료★!!!!!!!!!!!!!!!!!!!!!!!!!!!!!

국비교육으로 수강했던 데이터분석 과정 수료했다!!!!!!!!!!!! 더 열심히, 좋은 곳에서 경험과 경력을 쌓고싶다!
47.[Pandas] 날짜와 시간 데이터 다루기
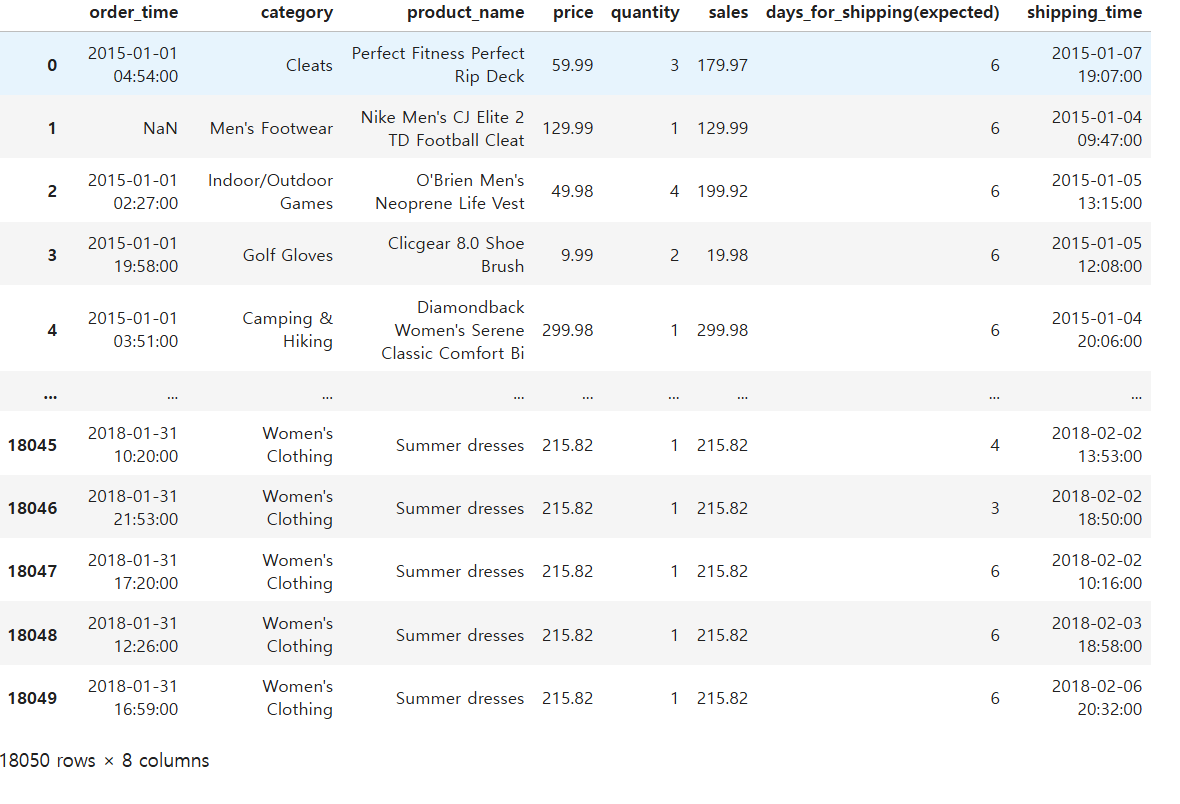
날짜와 시간 데이터를 다루는 법에 대해 학습했다.우선 사용할 데이터를 가져온다.order_time과 shipping_time 컬럼에 날짜와 시간 값이 들어 있는데, 두 컬럼 모두 날짜가 연도-월-일 형태로 되어 있다. pandas datetime의 기본 형식인데, 아
48.[Pandas] 실습- 날짜와 시간데이터 인덱싱
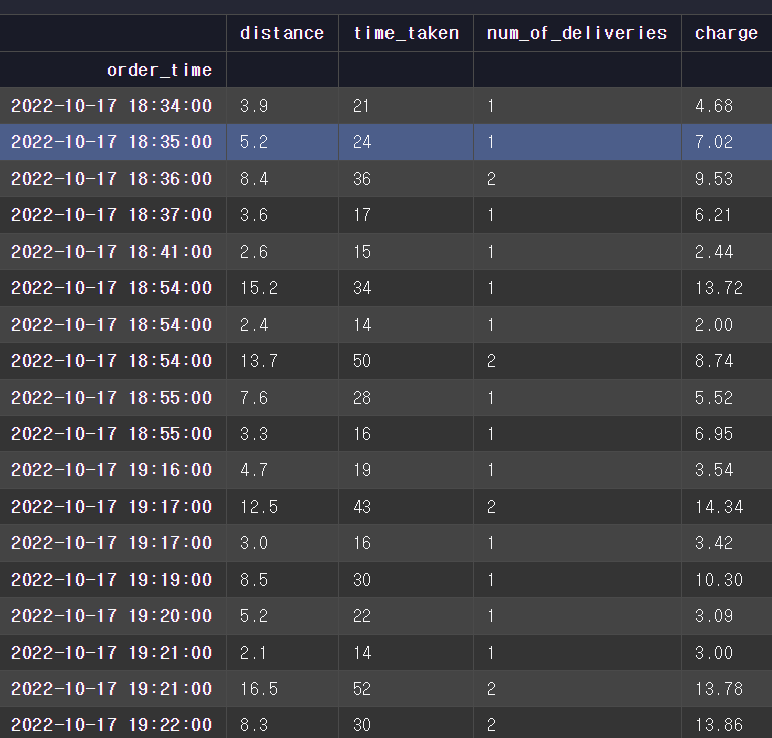
홍길동은 배달 전문 음식점을 운영하고 있다. 저녁 시간대에 들어오는 주문이 엄청 많아져서 새로운 배달 업체와 계약을 했다. 일주일 정도 서비스를 이용해 본 뒤, 배달이 빠르게 잘 되고 있는지 배달 수수료로 얼마를 내고 있는지 등을 전반적으로 확인해 보려고 한다.2022
49.[Pandas]실습- timedelta, unit
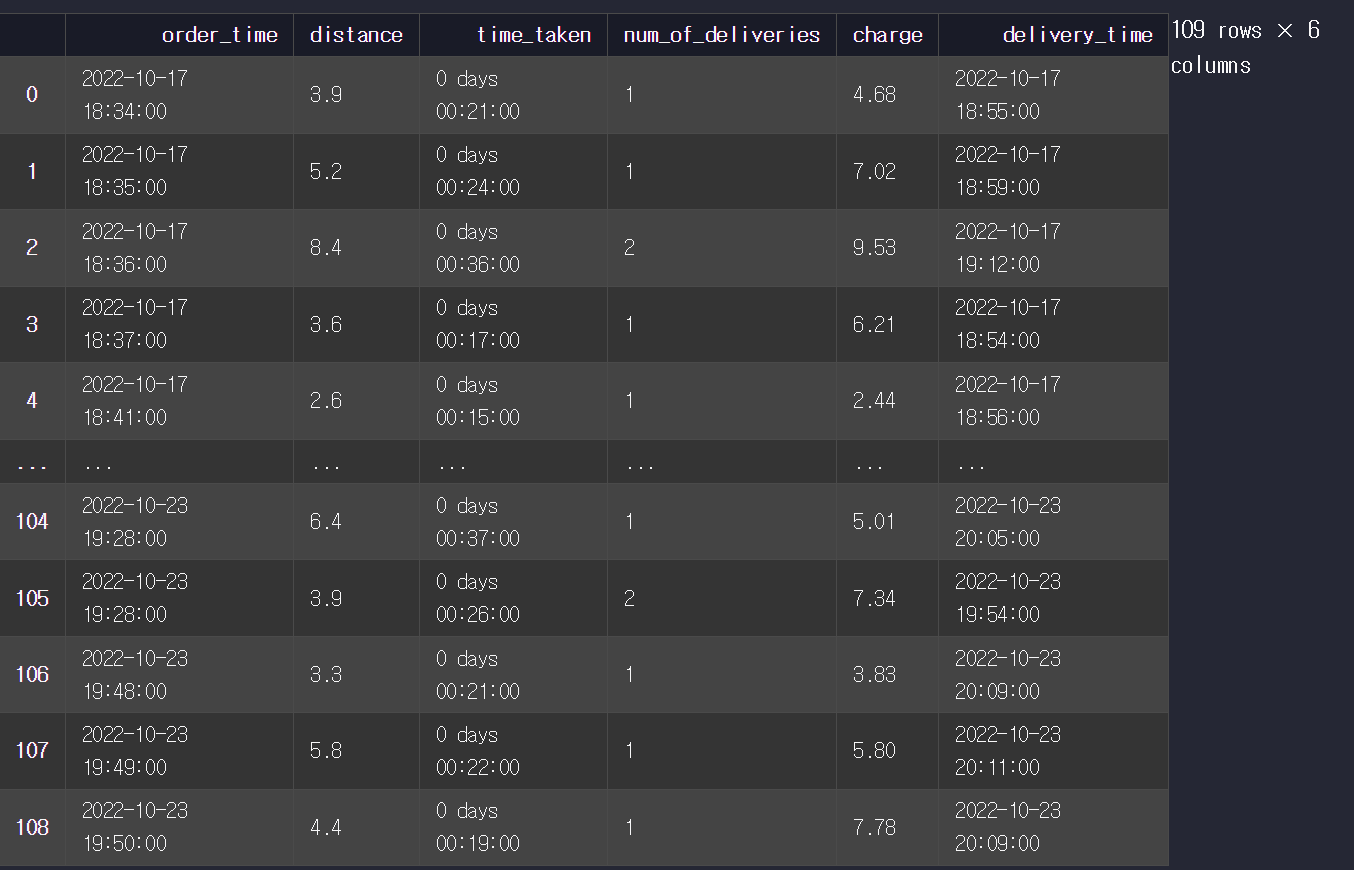
배달 음식이 고객에게 도착한 시각을 계산해 보자. 주문 시각(order_time)과 배달 소요 시간(time_taken)을 가지고 배달 완료 시간을 계산해서 DataFrame에 delivery_time이라는 컬럼을 추가해라.참고로 time_taken 컬럼은 배달에 몇
50.[Pandas] 데이터 병합하기 - merge(), join(), concat()
데이터 프레임을 병합하는 함수로, 두 개 이상의 데이터 프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합한다.pd.merge() 함수를 사용하여 데이터 프레임을 병합할 수 있다.SQL에서 테이블 간의 조인 작업을 수행하는 알고리즘으로, NL Join, So
51.[Pandas] Join데이터로 새로운 인사이트 얻기
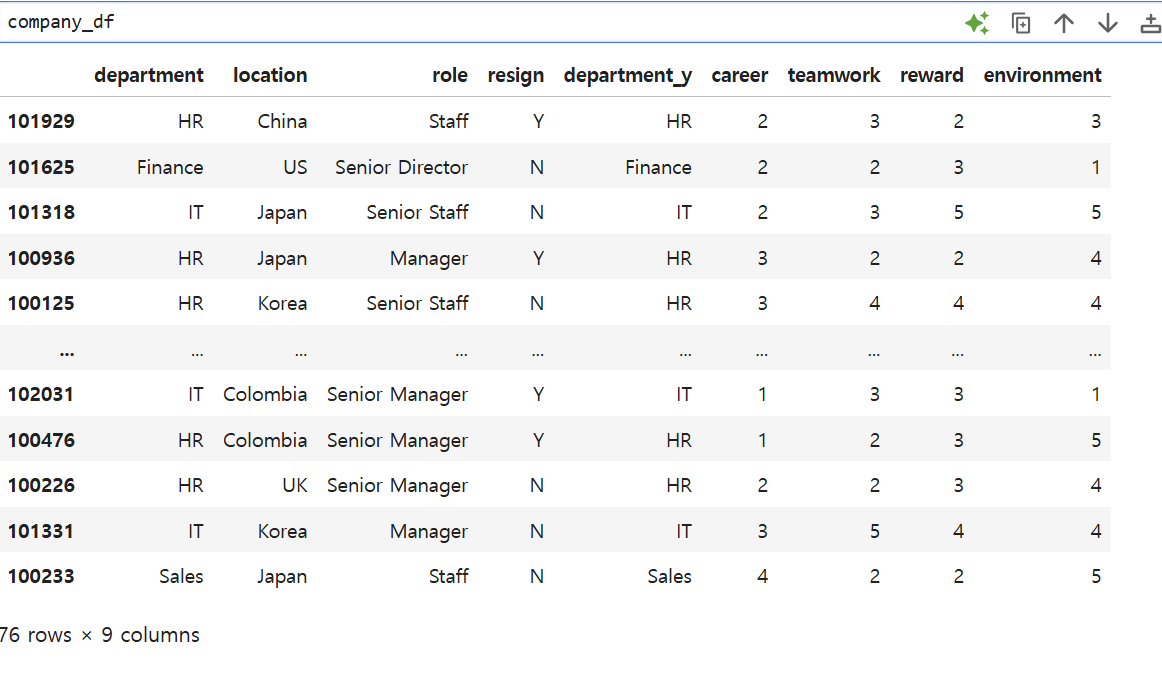
employee, survey 데이터를 조인한 campany 데이터에 대해서 새로운 인사이트를 얻어보자.=> 퇴사한 직원 정보 확인 (resign 컬럼이 Y)이 데이터에 대한 통계를 내보자.=> 해당 통계만으로는 정보를 알 수 없기에, 퇴사하지 않은 직원의 정보랑 비교
52.[Pandas] 그룹화 - groupby()
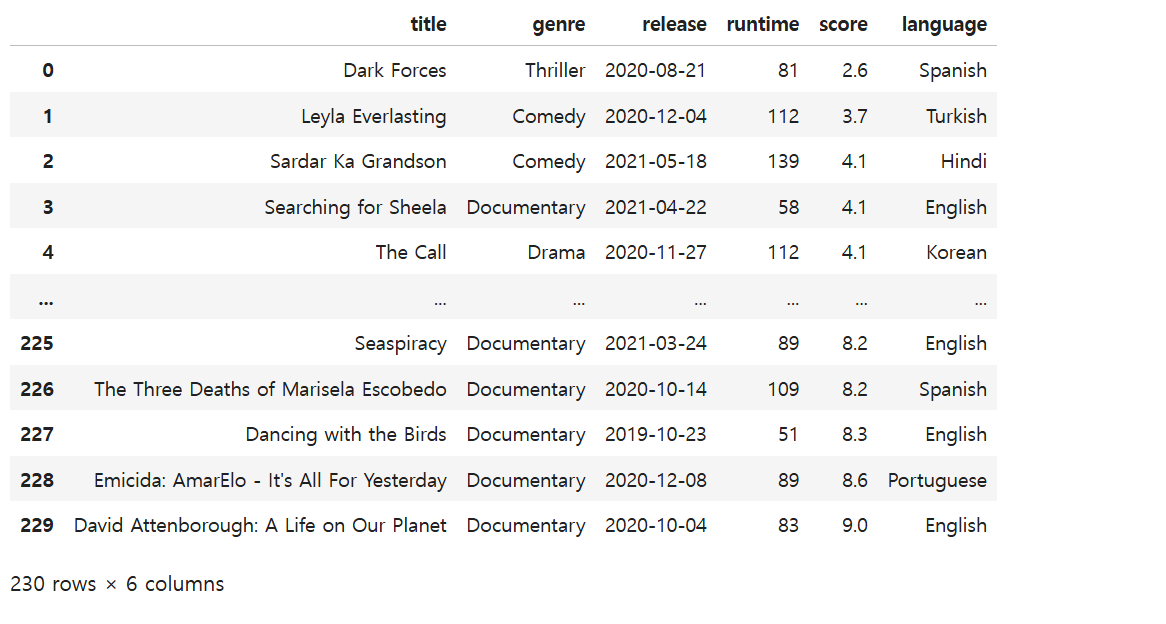
groupby 메서드는 데이터를 그룹화하여 연산을 수행하는 메서드이다.\-> 관련하여 넷플릭스 콘텐츠 평점에 대한 데이터 분석을 해보자.그룹별 통계정보를 분석하고 싶을 경우 groupby함수를 사용할 수 있다.예를들어 장르별 등등... 장르별 숫자 데이터의 최소값을 확
53.[Pandas] category 데이터 타입 다루기

pandas에는 category라는 데이터 타입이 있는데, 범주형 데이터를 표현할 때 사용한다. 범주형 데이터는 연속적인 값을 갖는 연속형 데이터와 달리, 보통 어느 정도 제한된 범위 안에서 몇 가지 값을 가진다. 예를 들어, 옷 사이즈는 XS/S/M/L/XL, 혈
54.[Pandas] plotly express, legend 변경, x축, y축 설정
plotly expree로 만든 그래프의 세부 요소들을 변경해보는 시간을 가졌다.fig.update_layout(): 전체 레이아웃(제목, 범례, 여백 등)을 수정fig.update_xaxes(): x축의 속성(제목, 글꼴, 눈금 등)을 수정fig.update_yaxe
55.[Pandas] group by()와 멀티인덱스
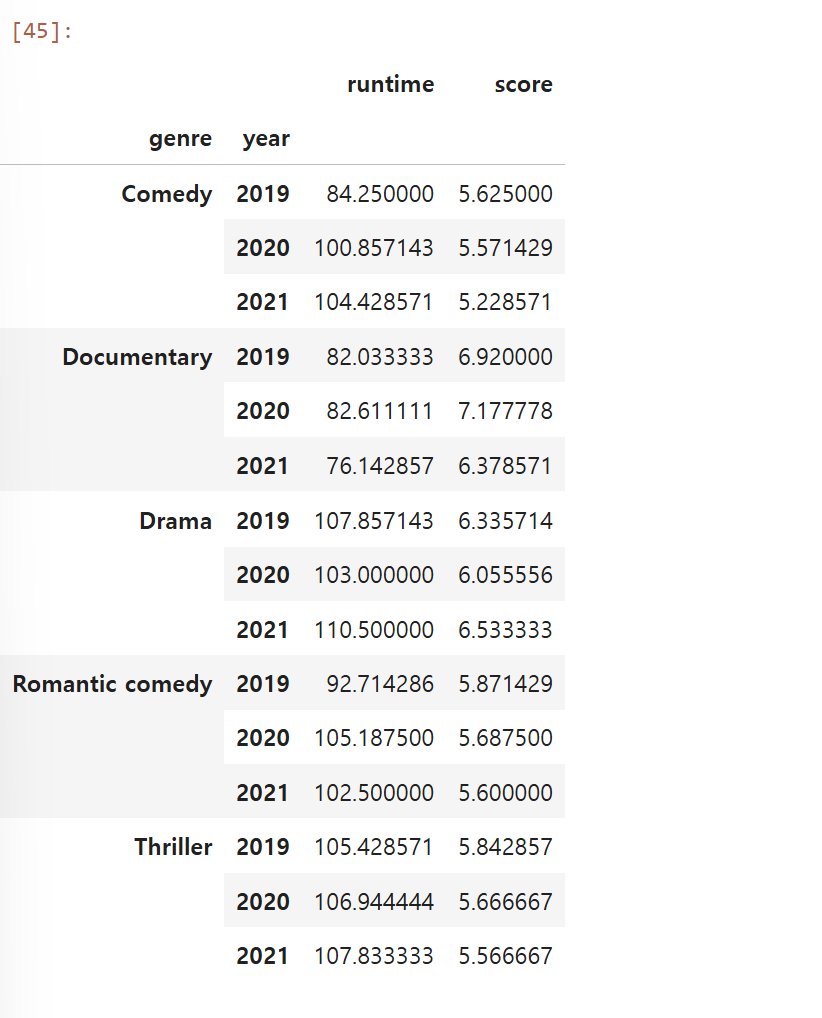
이전 게시물과 같은 데이터를 사용하여 멀티인덱스를 해보자!넷플릭스 데이터에 장르와 연도를 numeric_only = True를 사용해 평균치에 대한 멀티 인덱싱을 해보았다.다음은 연도와 장르의 순서를 바꿔서 해본 결과이다.여기서 연도가 2020년인 데이터만 뽑고싶으면
56.[Pandas] 피벗 테이블, aggfunc()
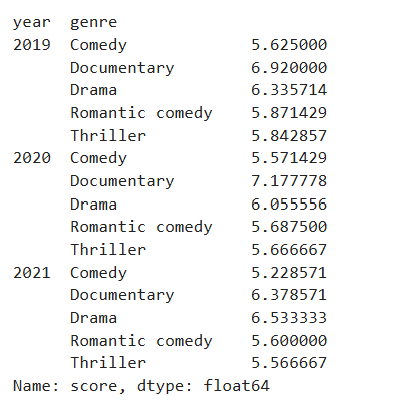
Pivot Table은 데이터를 원하는 형태로 집계할 때 아주 유용하게 사용할 수 있다.데이터 분석을 할 때 반드시 알아야 할 필수적인 데이터 전처리 방법! group by 와 피벗 테이블의 차이를 알아보자.group by : 데이터를 피봇팅하여 통계량을 볼 수 있도록
57.[Pandas] 피벗 테이블 실습
피벗 테이블로 몬트리올 올림픽의 국가별 금메달, 은메달, 동메달의 개수를 계산하자. 이때 결측값은 0으로 채우고, 금메달, 은메달, 동메달 개수, 나라 이름 순서대로 내림차순 정렬해라. 메달 정보는 medal 컬럼에 저장되어 있고, 1st는 금메달, 2nd는 은메달,
58.[데이터분석] EDA와 데이터 타입에 따른 시각화 기법
위치 추정 VS 변이 추정위치 추정: 방대한 데이터의 대푯값을 구해서, 해당 feature의 일종의 요약 정보 도출보통은 평균을 쓴다.변이 추정: 방대한 데이터의 분포 (밀집해 있는지, 퍼져 있는지)를 알아내어, 역시 해당 feature의 일종의 요약 정보 도출수학에서
59.[데이터분석] RFM 분석

RFM 분석이란 RFM은 Recency, Frequency, Monetary 각각의 앞 글자를 따서 만들어진 약자예요. 이 세 항목의 의미는 다음과 같습니다. Recency: 고객이 얼마나 최근에 상품을 구매했는가? Frequency: 고객이 얼마나 자주 상품을 구매
60.[데이터분석] 탐색적 데이터분석- 시계열 데이터 시각화
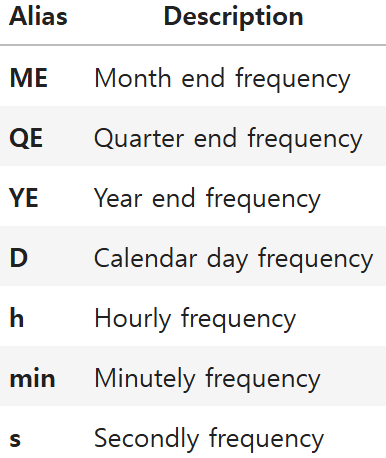
날짜 데이터의 간격이 규칙적이지 않은 경우를 다룰 때, 원하는 주기의 날짜 데이터를 생성하기 위해 pandas의 date_range 함수(메서드)를 활용할 수 있다.start / end: 날짜를 생성하기 위한 시작과 끝 값 (string or datetime 형식)p
61.[데이터분석] 탐색적 데이터분석- 상관관계 그래프
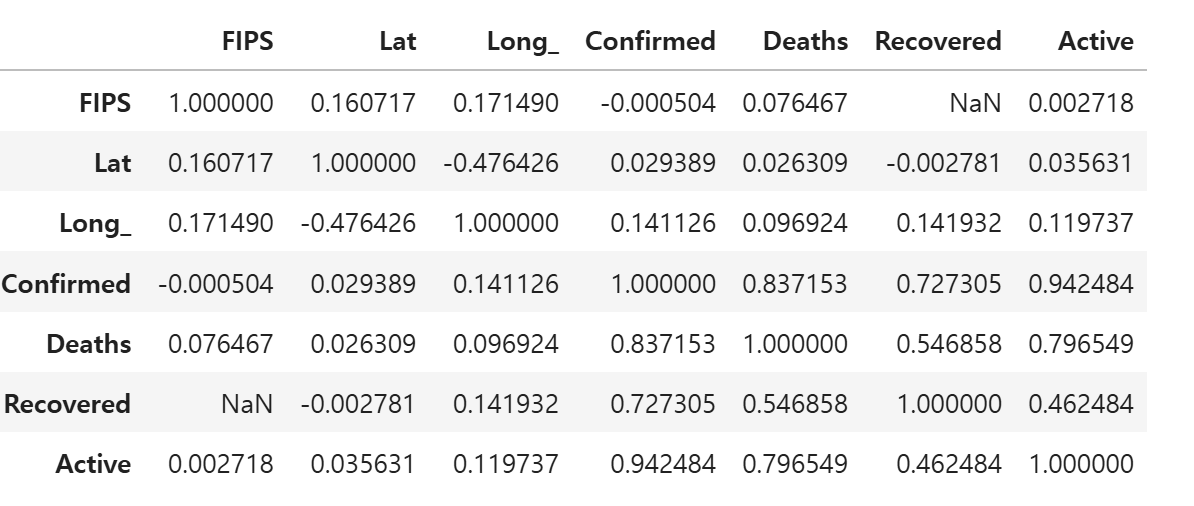
Heatmap 그래프산점도(Scatter) 그래프히트맵 그래프 예시그래프 이해하는법 corr(method=상관계수): 각 속성간 상관 관계 확인하기 피어슨 상관계수는 선형 상관 관계를 조사하며, 일반적으로\+1에 가까우면, 양의 선형 상관 관계 0에 가까우면 상관관계가