pandas에는 category라는 데이터 타입이 있는데, 범주형 데이터를 표현할 때 사용한다.
범주형 데이터는 연속적인 값을 갖는 연속형 데이터와 달리, 보통 어느 정도 제한된 범위 안에서 몇 가지 값을 가진다.
예를 들어, 옷 사이즈는 XS/S/M/L/XL, 혈액형은 A형/B형/O형/AB형, 연령대는 10대/20대/30대 등의 범주를 가지는 것을 예시로 들 수 있다.
지난 게시물을 예시로 한다면, genre 컬럼은 Comedy, Documentary, Drama, Romantic comedy, Thriller 이렇게 다섯 종류의 값을 가진 범주형 데이터로 되어 있다고 할 수 있지만, genre 컬럼의 데이터 타입은 object이다.
텍스트로 되어 있는 데이터는 pandas가 기본적으로 object 타입으로 불러오기 때문이다.
object 타입이 있는데 굳이 category 타입이 존재하는 이유는?
먼저 category 타입은 좀 더 메모리 사용량이 적다는 특징이 있다.
그리고 가장 중요한 특징으로는 각 범주에 순서를 매길 수 있다는 점이 있다.
아래 예시를 봐보자. 옷 사이즈와 판매량 정보가 들어 있는 DataFrame이 있다.
import pandas as pd
clothes_df = pd.DataFrame({
'size': ['L', 'S', 'XS', 'L', 'S', 'XL', 'L', 'S', 'M', 'XS',
'M', 'M', 'XS', 'L', 'XL', 'XS', 'M', 'S', 'L', 'XL'],
'sales': [130, 200, 120, 120, 140, 160, 190, 90, 110, 100,
150, 180, 100, 200, 80, 140, 150, 90, 80, 130]
})
clothes_df
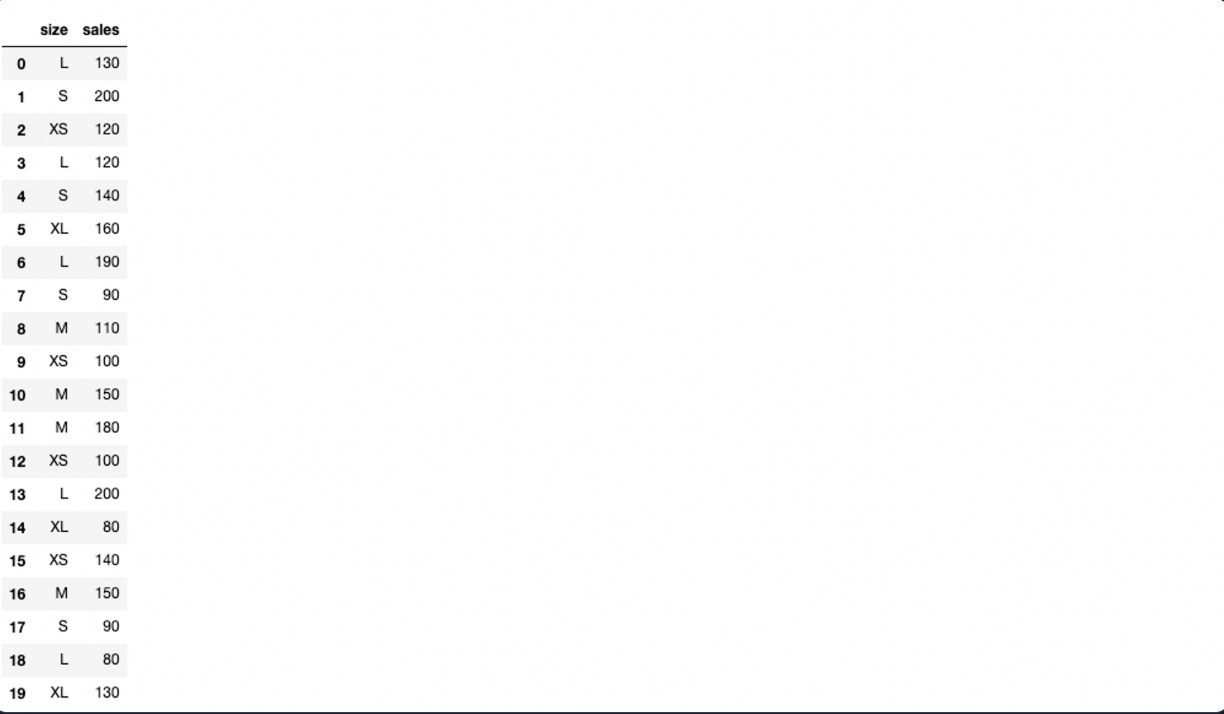
여기서 size 컬럼을 기준으로 오름차순 정렬을 하면,
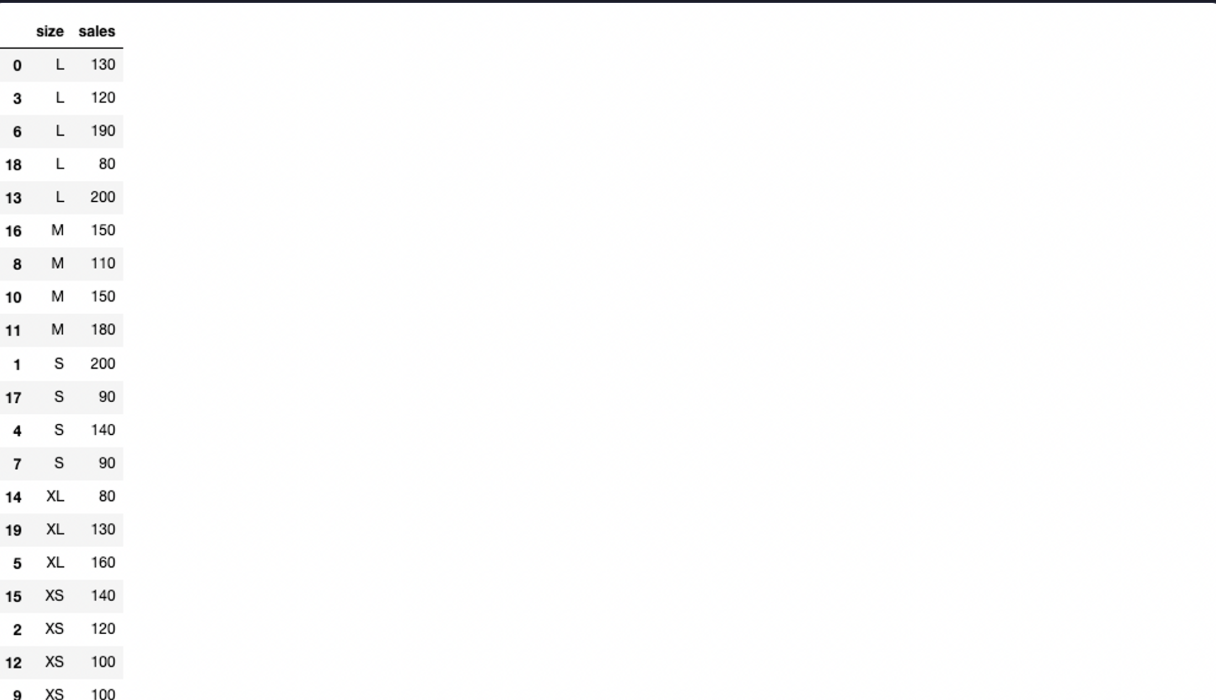
이렇게 L-M-S-XL-XS 순으로 정렬이 된다. 사이즈의 크고 작음은 고려하지 않고 그냥 abc 순으로 정렬되는 것을 확인 할 수 있다.
원하는 대로 순서를 매겨서 보고 싶은 경우에 category 타입을 활용하면 된다.
pandas의 Categorical()이라는 함수 안에 category 타입으로 바꿀 데이터를 넣고, ordered라는 파라미터 값을 True로 설정하면 된다.
(참고로, ordered 파라미터의 디폴트 값은 False이기 때문에, 범주별 순서를 매기려면 이 값을 따로 True로 설정해야 한다.)
그리고 categories라는 파라미터에 리스트를 활용해서 각 범주 값을 원하는 순서대로 넣어 주면 끝.
아래 코드처럼 ['XS', 'S', 'M', 'L', 'XL']을 넘겨주면 사이즈가 XS-S-M-L-XL 순으로 순서가 매겨진다.
pd.Categorical(clothes_df['size'], ordered=True, categories=['XS', 'S', 'M', 'L', 'XL'])
['L', 'S', 'XS', 'L', 'S', ..., 'XS', 'M', 'S', 'L', 'XL']
Length: 20
Categories (5, object): ['XS' < 'S' < 'M' < 'L' < 'XL']
size 컬럼에 값을 다시 저장하고 오름차순 정렬을 하면,
clothes_df['size'] = pd.Categorical(
clothes_df['size'],
ordered=True,
categories=['XS', 'S', 'M', 'L', 'XL']
)
clothes_df.sort_values(by='size')

순서대로 정렬이 잘 된 것을 알 수 있다.
