이전 게시물과 같은 데이터를 사용하여 멀티인덱스를 해보자!
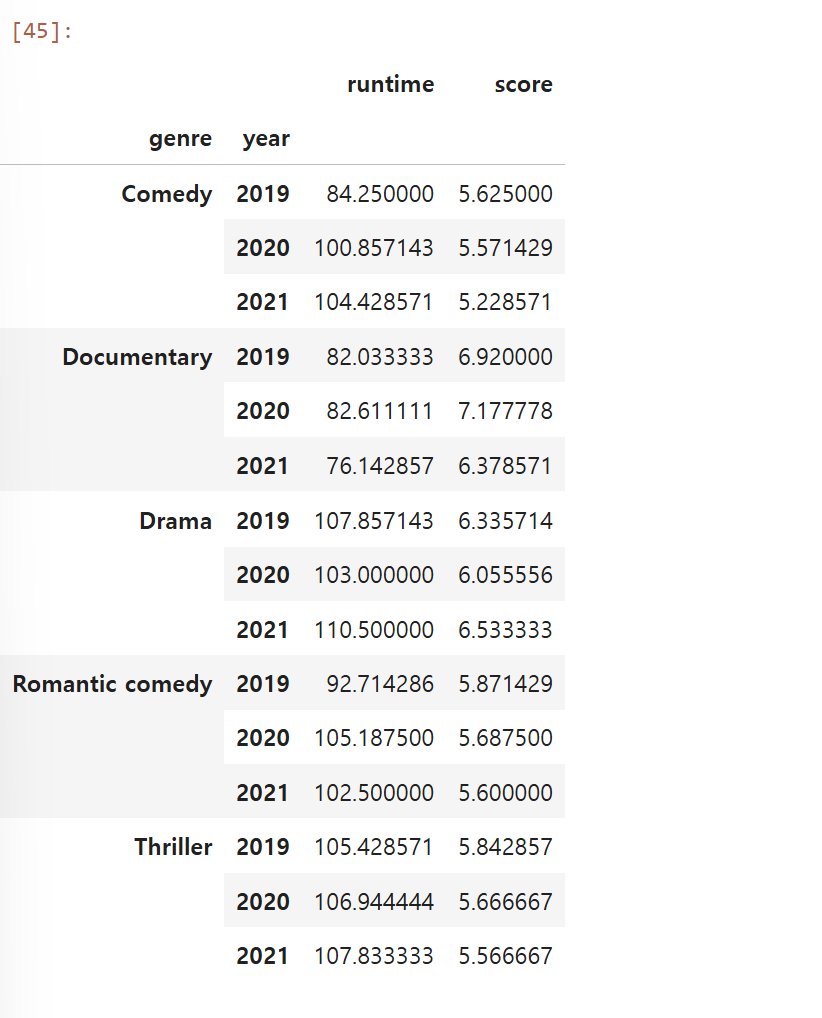
netflix_df.groupby(['genre', 'year']).mean(numeric_only = True)넷플릭스 데이터에 장르와 연도를 numeric_only = True를 사용해 평균치에 대한 멀티 인덱싱을 해보았다.
다음은 연도와 장르의 순서를 바꿔서 해본 결과이다.
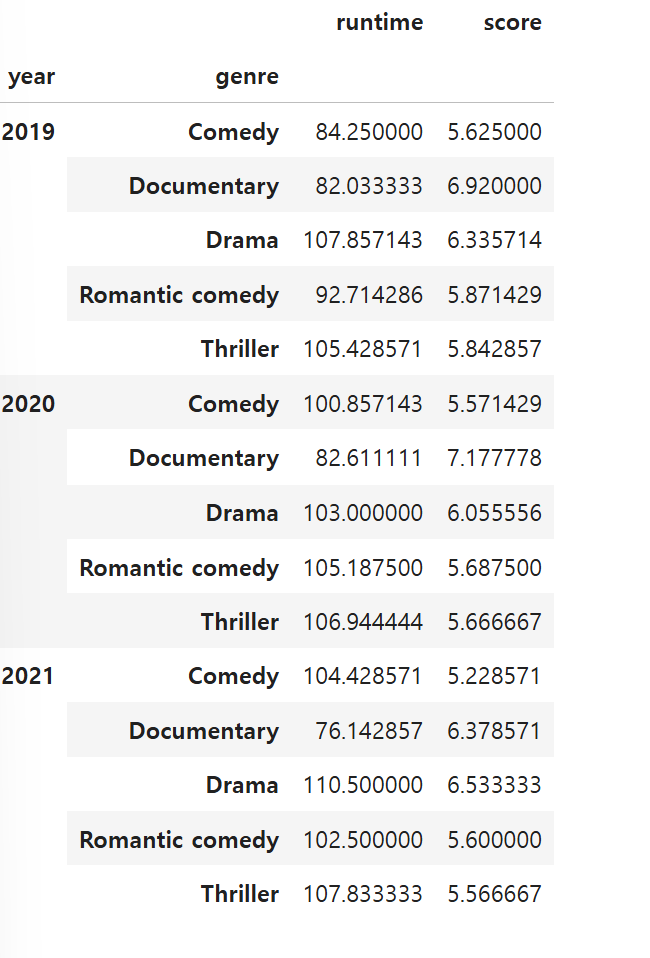
여기서 연도가 2020년인 데이터만 뽑고싶으면 loc을 사용해 2020을 지정한다.
netflix_df.groupby(['year', 'genre']).mean(numeric_only = True).loc[2020]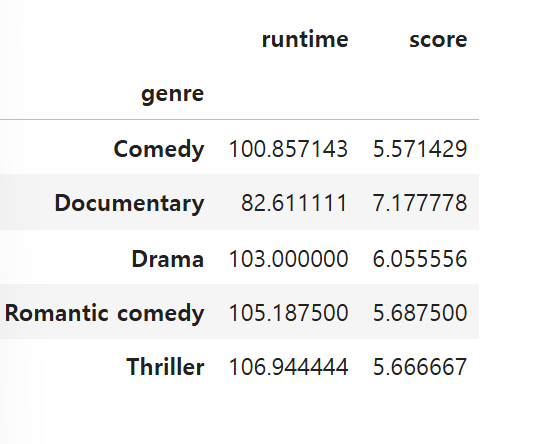
반대로, 장르가 드라마인 데이터만 추출도 가능할까? 정답은 X이다. 왜일까?
netflix_df.groupby(['year', 'genre']).mean(numeric_only = True).loc['Drama']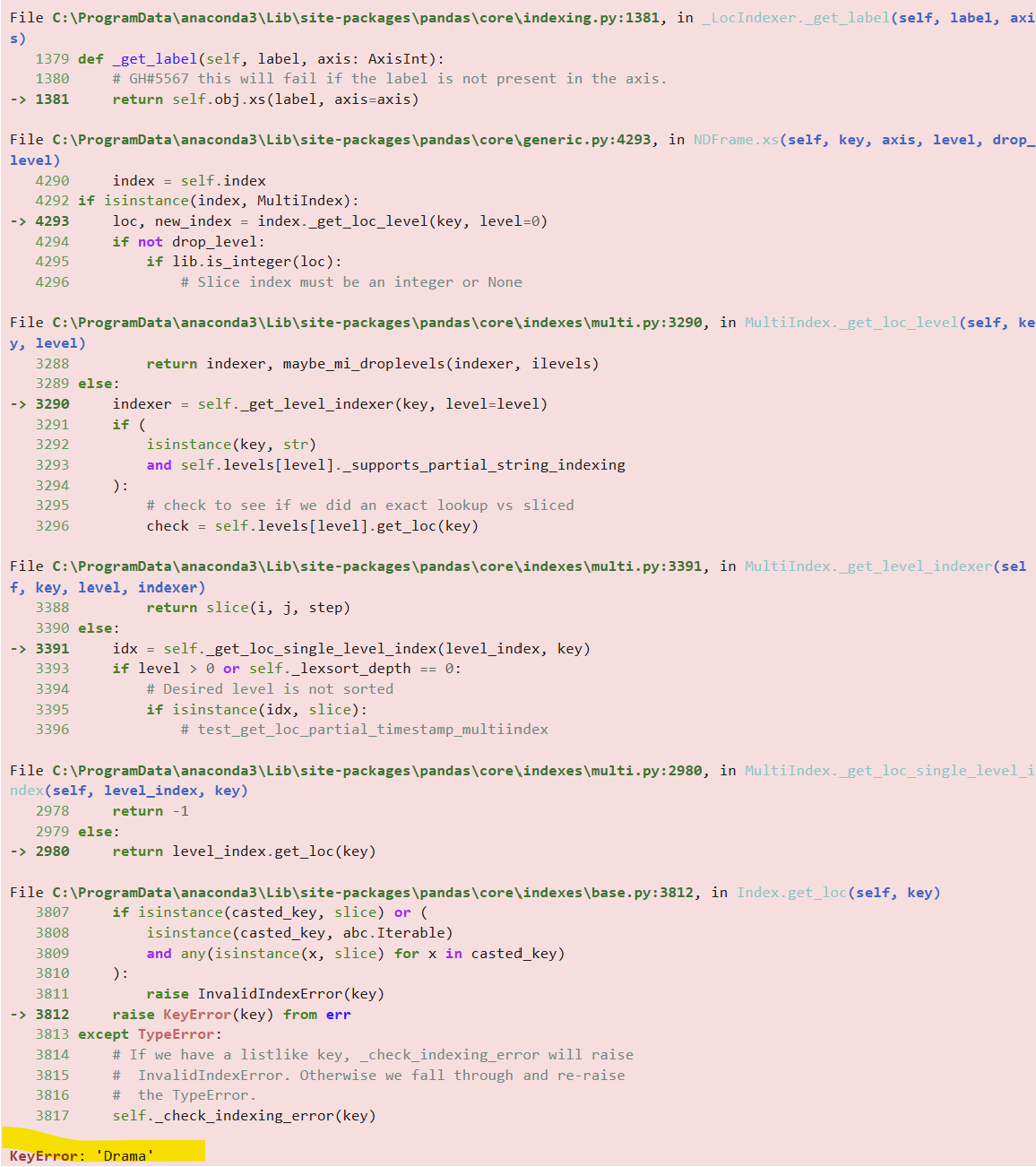
사진처럼 빨간색으로 에러창이 쫘악~하고 뜨는데 맨 밑에 키에러라고 뜬다.
바깥쪽에 있는 인덱스는 직접 불러올 수 있지만, 안쪽 인덱스는 불가하기 때문이다.
=>
netflix_df.groupby(['year', 'genre']).mean(numeric_only = True).loc[2020, 'Drama']이렇게 지정해주면 찾을 수 있다. 하지만, 여기서 문제점은 연도 데이터가 무수히 많을 경우에 일일이 적는게 어렵다. 이럴 경우에는 어떻게 할까?
years = sorted(netflix_df['year'].unique())unique() 함수와 sorted 를 이용해 years 라는 변수에 따로 저장해준다.
netflix_df.groupby(['year', 'genre']).mean(numeric_only = True).loc[(years, 'Drama'),:]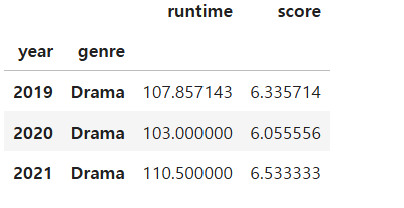
이렇게 하면 연도를 일일이 쓰지 않아도 데이터 처리가 가능하다!

멋있는 어른이 되고싶은 정만이의 벨로그