merge()
데이터 프레임을 병합하는 함수로, 두 개 이상의 데이터 프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합한다.
pd.merge() 함수를 사용하여 데이터 프레임을 병합할 수 있다.
join()
SQL에서 테이블 간의 조인 작업을 수행하는 알고리즘으로, NL Join, Sort Merge Join, Hash Join 등이 있다.
조인해야 할 데이터의 양, 데이터 세트의 크기, 조인 방식에 따라 다양한 조인 알고리즘이 사용됩니다 ex) inner, left, right, full outer ..
concat()
데이터 프레임을 순차적으로 연결하는 함수로, pd.concat() 함수를 사용하여 데이터 프레임을 연결할 수 있다.
데이터 프레임으로 이루어진 리스트를 만들어 concat()의 인풋으로 넣어주면 데이터 프레임들이 모두 연결 된다.
merge 실습
- 문제
소행성 정보를 담고 있는 asteroid_df와 각 소행성이 속한 궤도 관련 정보를 담고 있는 orbit_df를 하나로 합쳐서, 각 소행성이 지구와 충돌할 위험이 있는지 확인하려고 한다.
두 데이터를 inner join한 결과물을 nasa_df라는 변수에 저장하시오.
참고로 asteroid_df와 orbit_df는 NASA에서 제공한 데이터를 가공해서 만든 데이터로, 조인 연산 과정에 좀 더 집중해서 데이터를 탐색하면 된다.
가장 마지막 줄에는 nasa_df라고 입력해서 DataFrame을 출력하라.
-
head() 함수로 각 데이터 확인
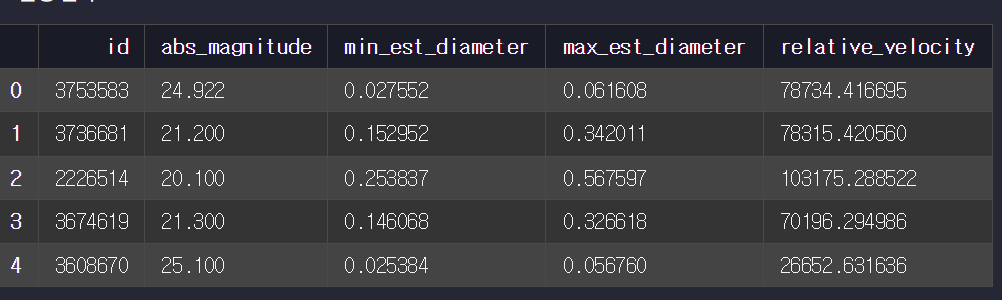
-> asteroid_df
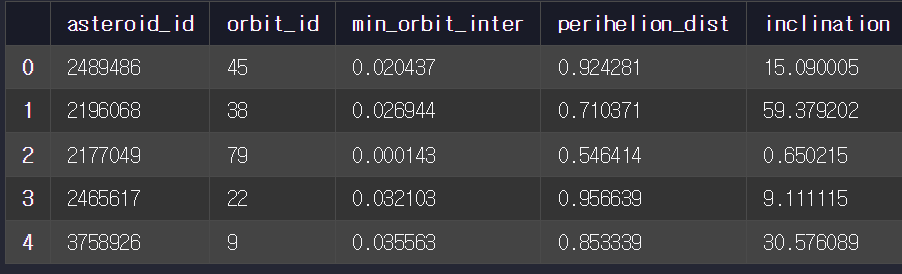
-> orbit_df -
asteroid_df의 id 컬럼과 orbit_df의 asteroid_id 컬럼을 이용하기
nasa_df = pd.merge(asteroid_df, orbit_df, left_on = 'id', right_on = 'asteroid_id')- nasa_df에 저장하여 출력
import pandas as pd
asteroid_df = pd.read_csv('data/asteroid.csv')
orbit_df = pd.read_csv('data/orbit.csv')
nasa_df = pd.merge(asteroid_df, orbit_df, left_on = 'id', right_on = 'asteroid_id')
nasa_df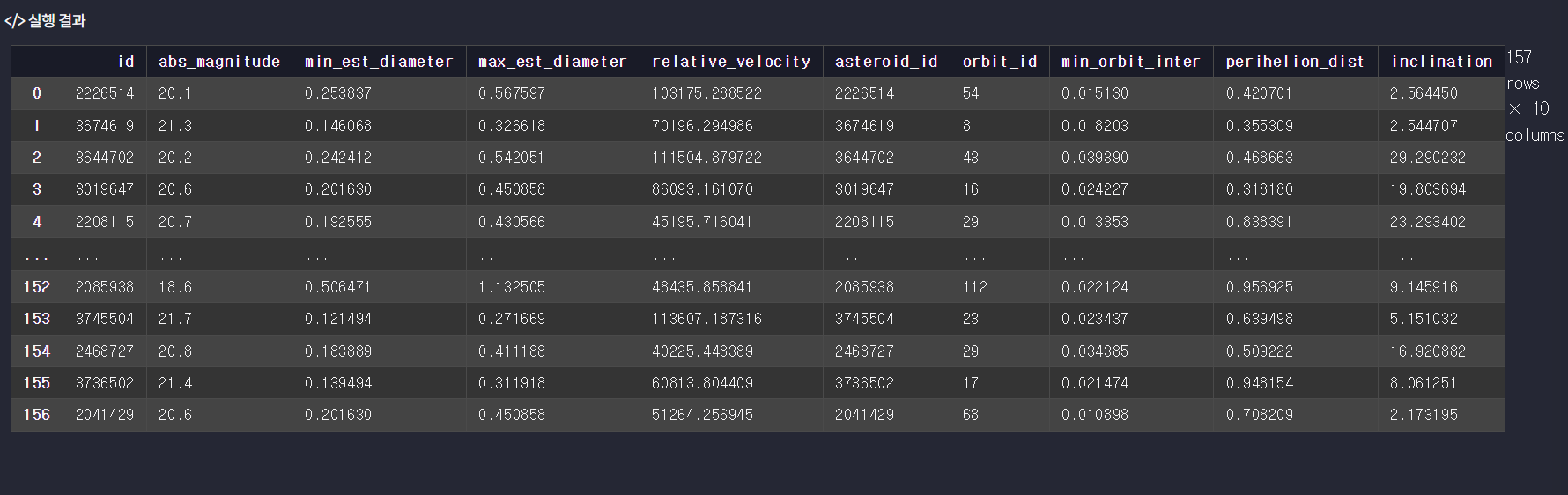
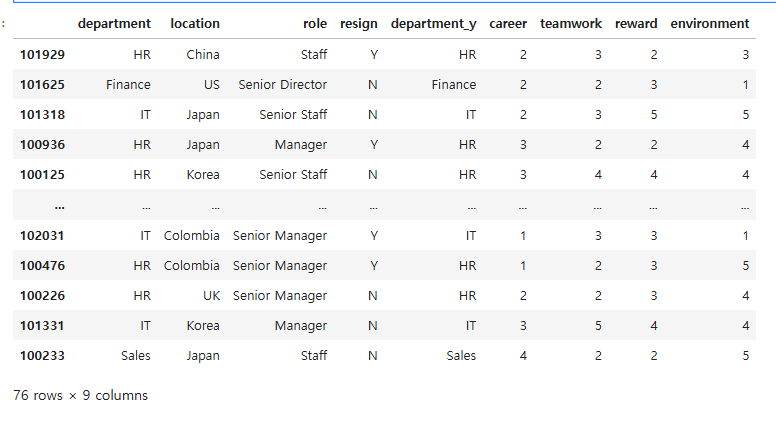
* Join 실습
- employee, survey 두 데이터를 가지고 join을 실습해보자.
employee_df.join(survey_df)조인을 실행하면 오류가 난다. 왜?
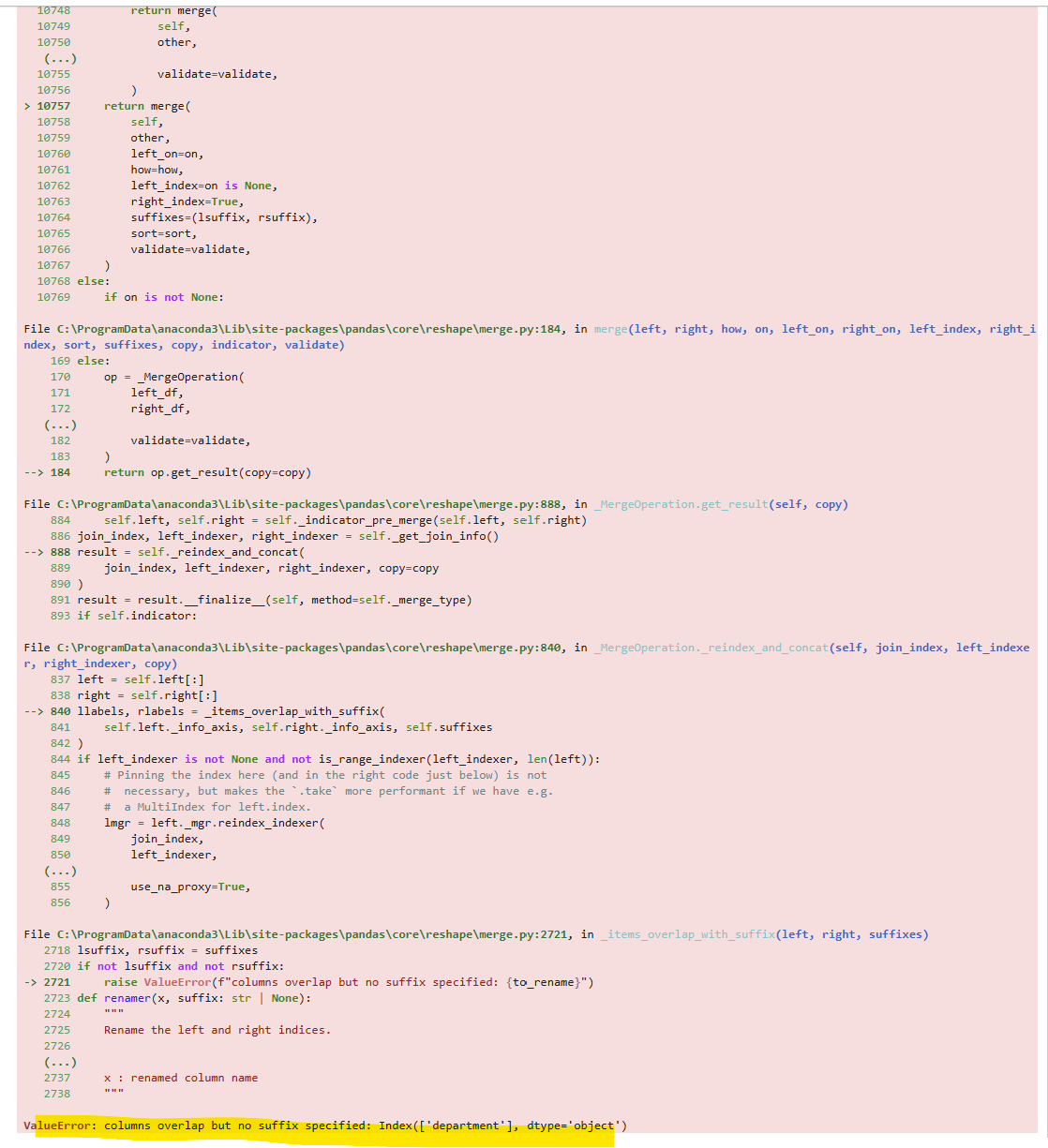
merge는 중복된 컬럼이 있으면 자동으로 suffix를 해주지만 join은 따로 설정해줘야하기 때문에 오류가 난다.
employee_df.join(survey_df, lsuffix = '_x', rsuffix = '_y')=> suffix 설정 후,
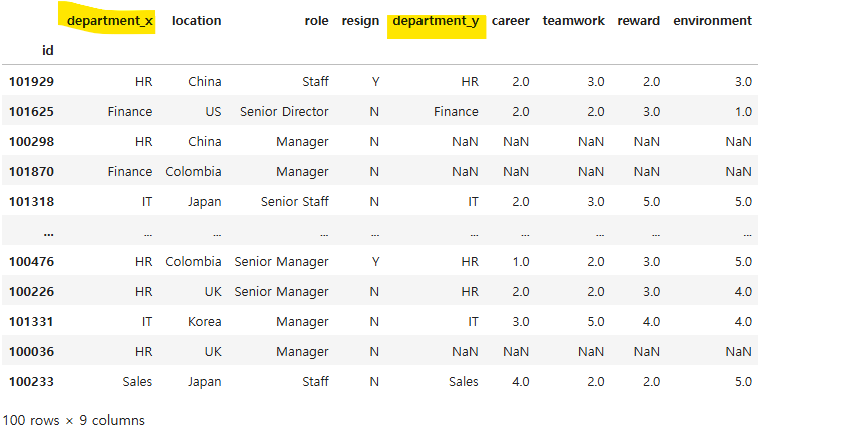
=> 결측값이 없는 inner join을 하기 위해선 how = 'inner'을 설정하면 된다.
company_df = employee_df.join(survey_df, rsuffix = '_y', how = 'inner')
company_df