데이터 전처리 과정에서의 결측값을 찾고 처리하는 과정을 학습했다.
결측값 ?
알려지지 않고, 수집되지 않거나 잘못 입력된 데이터 세트의 값.
데이터에 값이 없는 것을 뜻하며 줄여서 NA라고도 하고, Null 이라는 표현도 쓴다.
데이터 분석에서의 결측값이란 ?
- 결측치를 다 제거하면 막대한 데이터 손실을 부를 수 있다.
- 결측치를 잘못 대체하면 데이터에서 편향이 생길 수 있다.
- 분석결과가 매우 틀어질 수 있다.
아래 데이터를 통해 결측값을 찾고 처리하는 과정을 실습해보자.
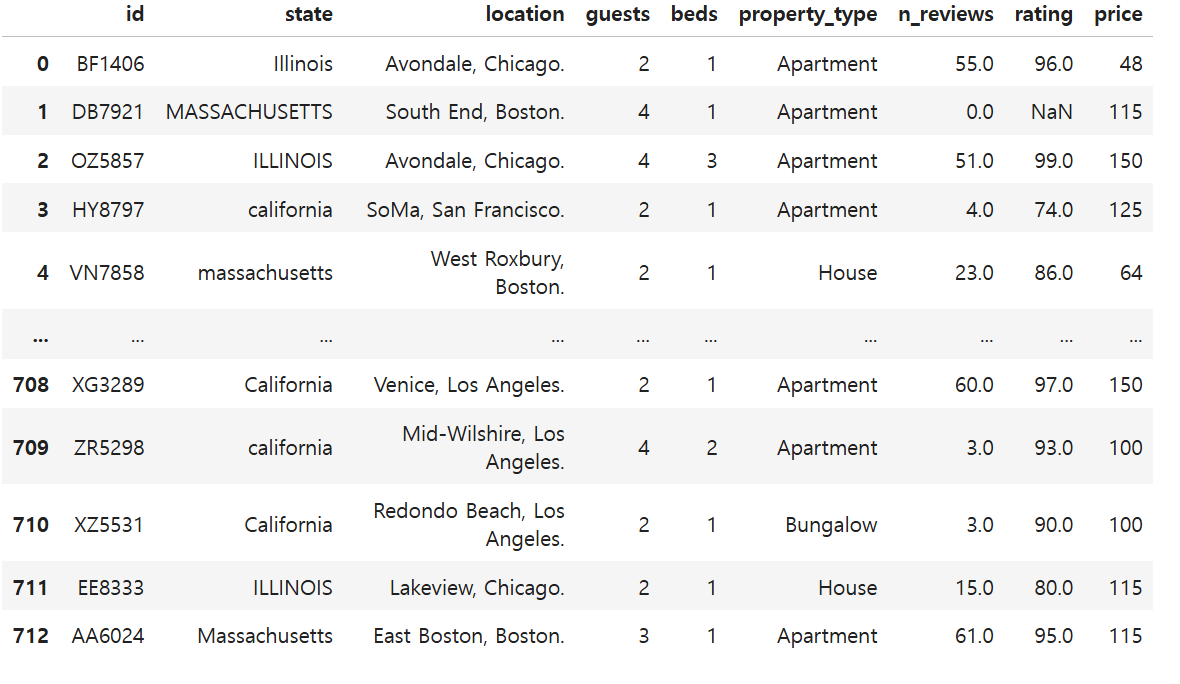
각각의 컬럼은 숙소번호, 숙소가 위치한 지역, 숙박 인원, 침대 개수, 숙소 타입, 리뷰 수 , 평점, 가격으로 되어있다.
- 결측값을 제외한 데이터를 확인해보자
airbnb_df.info()
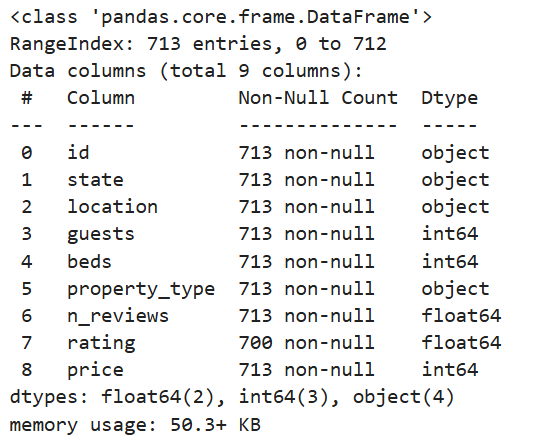
총 713 데이터에서 rating 컬럼의 데이터가 700개만 결측값이 아님을 확인할 수 있다.
=> 13개의 결측값이 존재함.
- 데이터프레임에서 각 위치에 있는 값이 결측값이면 True, 아니면 False인 함수를 사용해보자.
airbnb_df.isna()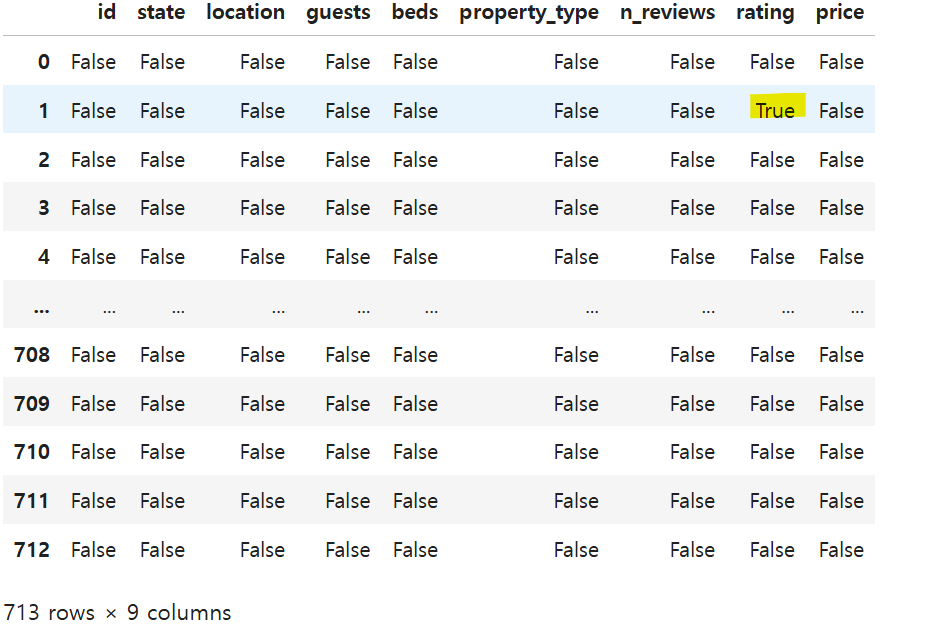
- 컬럼별로 결측값의 개수의 합이 몇개인지 확인해보자.
airbnb_df.isna().sum()
airbnb_df.isna().any(axis = 1)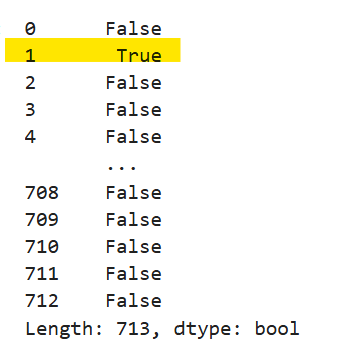
airbnb_df[airbnb_df.isna().any(axis = 1)]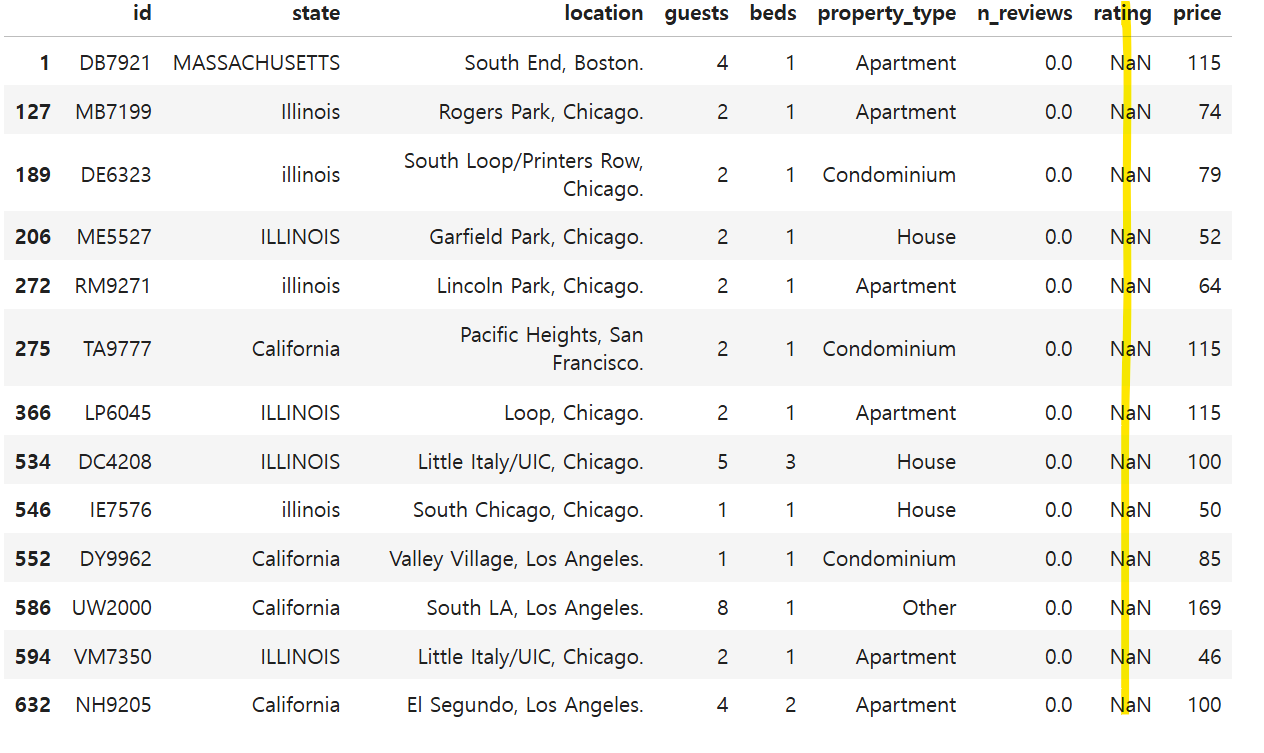
* 결측값을 삭제하는 함수 (dropna)
airbnb_df.dropna()
airbnb_df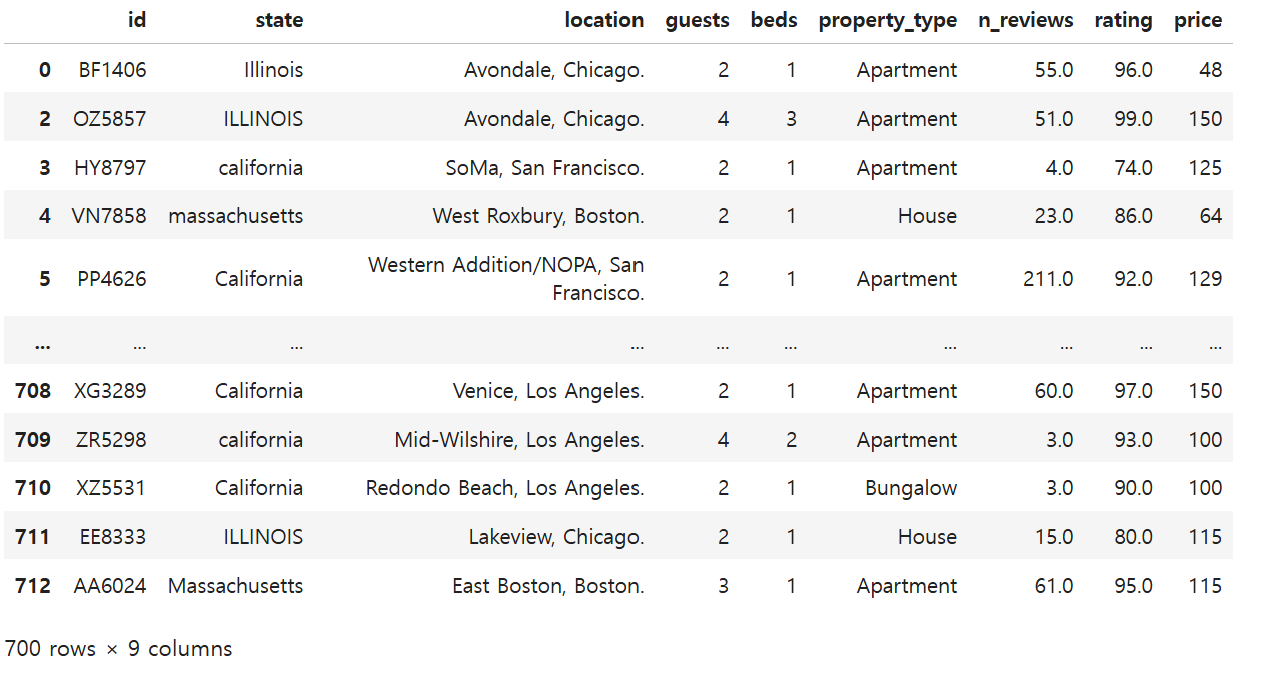
=> 인덱스 1번행이 삭제된 것을 확인할 수 있다.
* 결측값을 다른 값으로 채우는 함수 (fillna)
airbnb_df['rating'].fillna(rating_mean)=> rating 컬럼의 평균값으로 채우고자 한다. (94점)

이렇게 결측값을 확인하고 처리하는 방법에 대해 알 수 있었다!

멋있는 어른이 되고싶은 정만이의 벨로그