
Differentiable Augmentation for Data-Efficient GAN Training, Shengyu Zhao, et al., NeurIPS, 2020
본 논문은 GAN 학습에 적합한 data augmentation 기법을 제안한다. 같은 주제로 연구된 아래 논문을 함께 읽는 것을 추천한다.
- Training Generative Adversarial Networks with Limited Data, Tero Karras et al., NeurIPS, 2020
1. Problems
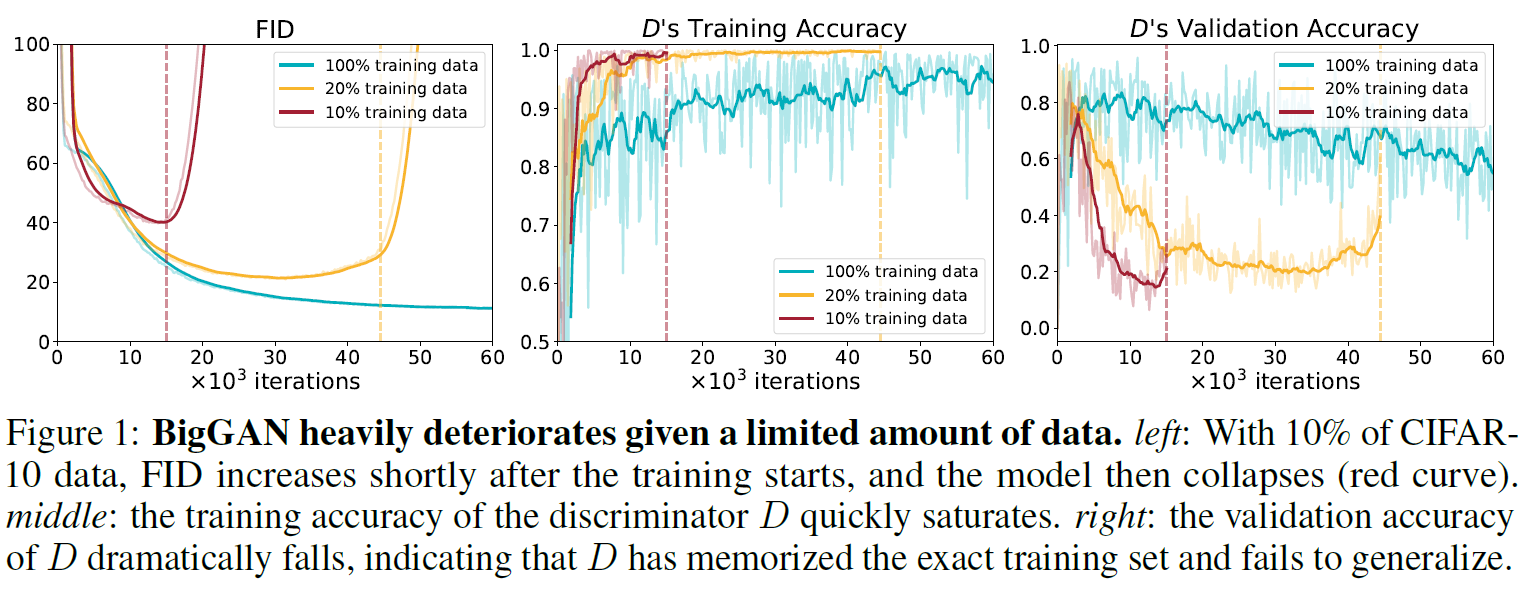
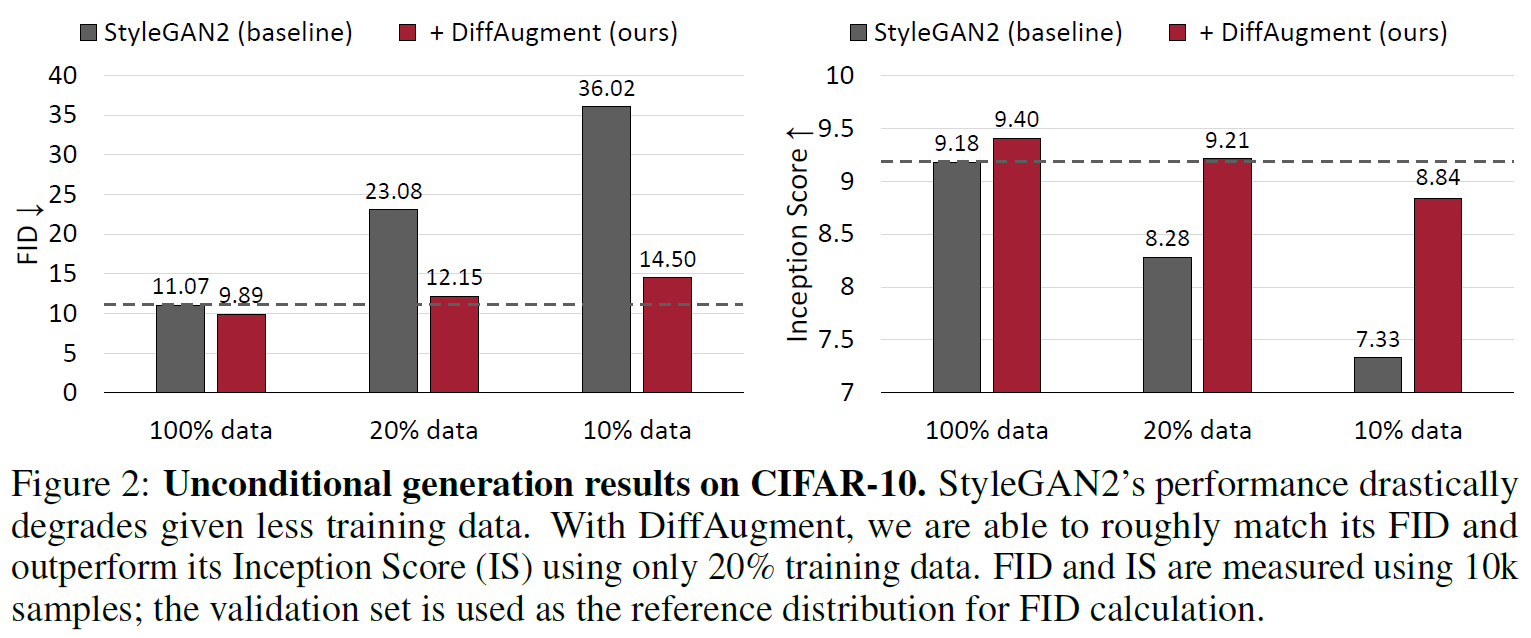
GAN(Generative Adversarial Networks)은 영상 합성 기술을 크게 발전시켰다. 하지만 GAN은 high fidelity 영상을 합성하기 위해 많은 양의 데이터와 연산을 요구한다. Fig. 1과 2와 같이 CIFAR-10 데이터셋의 일부(10%, 20%)만 사용하여 StyleGAN2를 학습한 경우, 모델의 성능(FID, Inception score)이 크게 저하되는 것을 볼 수 있다. GAN에서 데이터 부족은 discriminator의 overfitting 문제를 일으킨다고 알려져 있다. 본 논문에서는 학습 데이터를 줄였을 때 discriminator의 training accuracy와 validation accuracy의 차이가 벌어짐을 Fig.1에서 제시함으로써 discriminator의 overfitting 문제가 발생하는 것을 확인했다.
Data augmentation은 모델의 overfitting 문제를 해결하기 위해 영상 처리에서 사용하는 대표적인 방법의 하나다. 하지만 data augmentation 기법을 GAN에 직접 적용하는 경우, 모델의 성능이 오히려 저하된다. 본 논문은 이러한 근거를 바탕으로 GAN 학습에 적합한 data augmentation 기법을 제안하고, 제안한 방법이 GAN 학습을 크게 개선함을 실험적으로 보였다.
2. Related works
Regularization for GANs
- GAN의 학습 불안정성을 해소하기 위한 여러 가지 regularization 기법에 관한 연구
Data Augmentation
- 영상 처리 분야에서 데이터 부족을 완화하기 위한 대표적인 방법인 data augmentation에 관한 연구
3. Method
Challenge: Discriminator Overfitting
Discriminator가 학습 데이터를 암기하여 유의미한 feedback을 generator에게 주지 못함.
3.1. Revisiting Data Augmentation
Data augmentation을 GAN과 일반적인 image classifier에 적용했을 때 차이가 발생하는 이유를 고찰
Augment reals only (case 1)
일반적인 image classifier를 학습하는 것과 같이 Real data(Ground truth)만을 증강(augment)한 경우
수식에서 T(·)는 데이터 증강(augmenting data)을 뜻한다.
이 경우, 모델이 실제 데이터 x 대신 증강된 데이터 T(x)의 분포를 학습한다. 생성 모델의 기본 목적(x의 데이터 분포를 학습)과 차이가 발생한다.

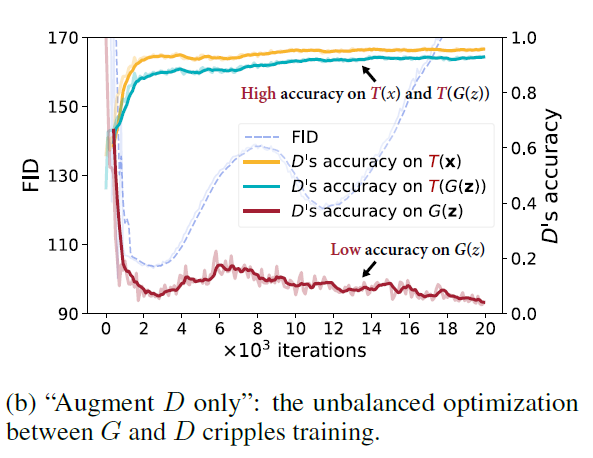
Augment D only (case 2)
Real data x와 fake data G(z)를 증강(augment)하되 discriminator의 학습에만 적용한 경우
Generator가 성공적으로 real data x의 분포를 학습한 경우, Discriminator는 G(z)와 x뿐만 아니라 T(G(z))와 T(x)를 분간할 수 없어야 한다. 해당 기법을 적용했을 때, Table 1처럼 모델의 성능이 감소했다. 아래 figure처럼, Discriminator가 증강된 데이터(T(G(z))와 T(x))를 분류하는 것은 성공(90% 이상의 정확도)했지만 증강하지 않은 G(z)를 인식하는 것은 실패(10% 미만의 정확도)하였다.
3.2 Differentiable Augmentation for GANs
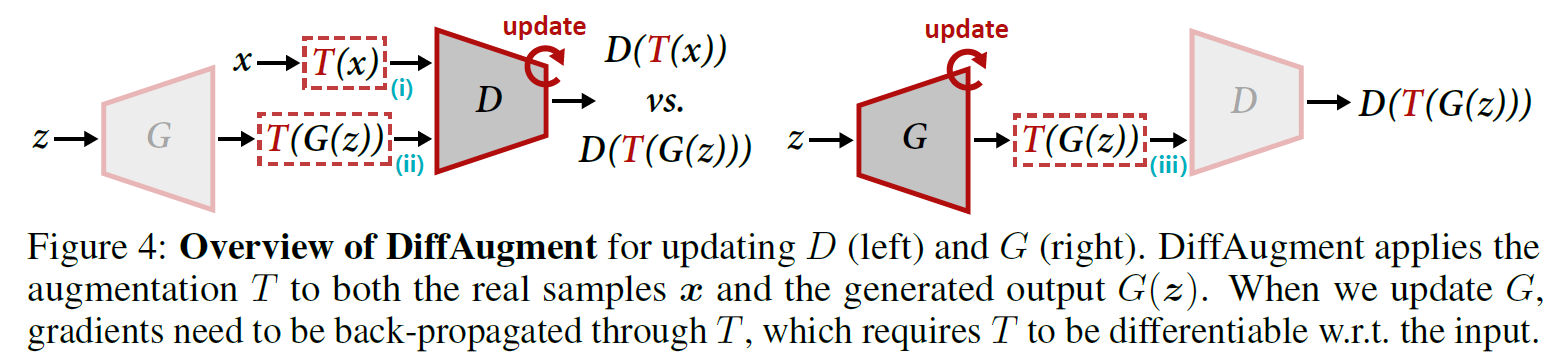
"Augment reals only (case 1)"의 실패는 real과 fake samples 모두 증강하는 방향으로 이끌었고, "Augment D only (case 2)"는 generator가 augmented samples를을 무시하면 안 된다는 것을 경고하였다.
두 가지를 전제로 real과 fake samples 모두를 증강하되, augmentation T를 미분 가능하게 만들어 샘플이 증강되었다는 feedback을 generator에 전달하는 방법을 시도하였다.
Differentiable Augmentation (case 3, DiffAugment)
DiffAugment 방법은 discriminator의 높은 수준의 validation accuracy를 유지함으로써 overfitting 문제를 완화하였고 결과적으로 GAN 모델이 더 좋게 수렴함을 보였다. 본 논문은 DiffAugment의 효용성을 검증하기 위해 Translation, Cutout, Color jittering 기법을 적용하였다.
4. Experiments
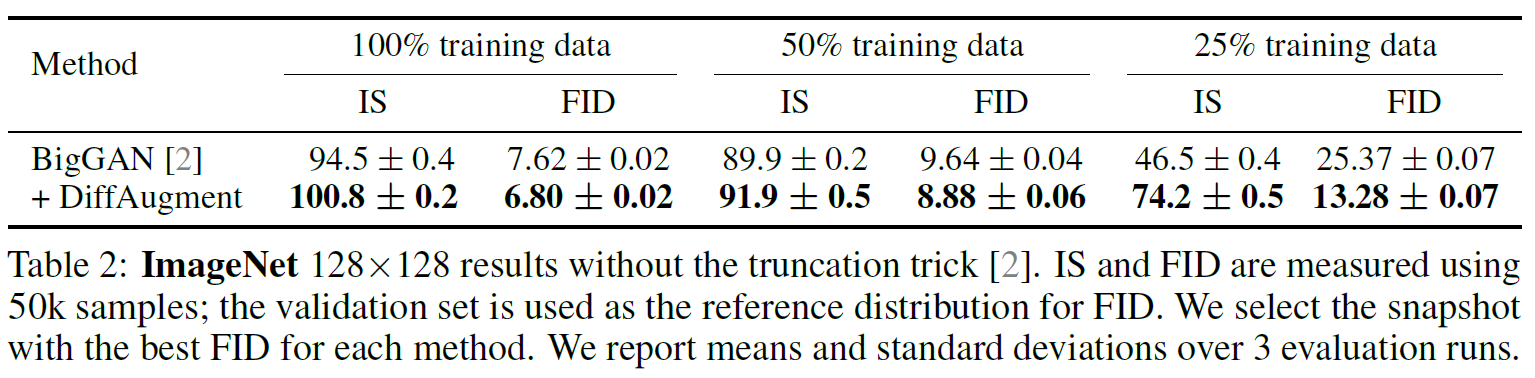
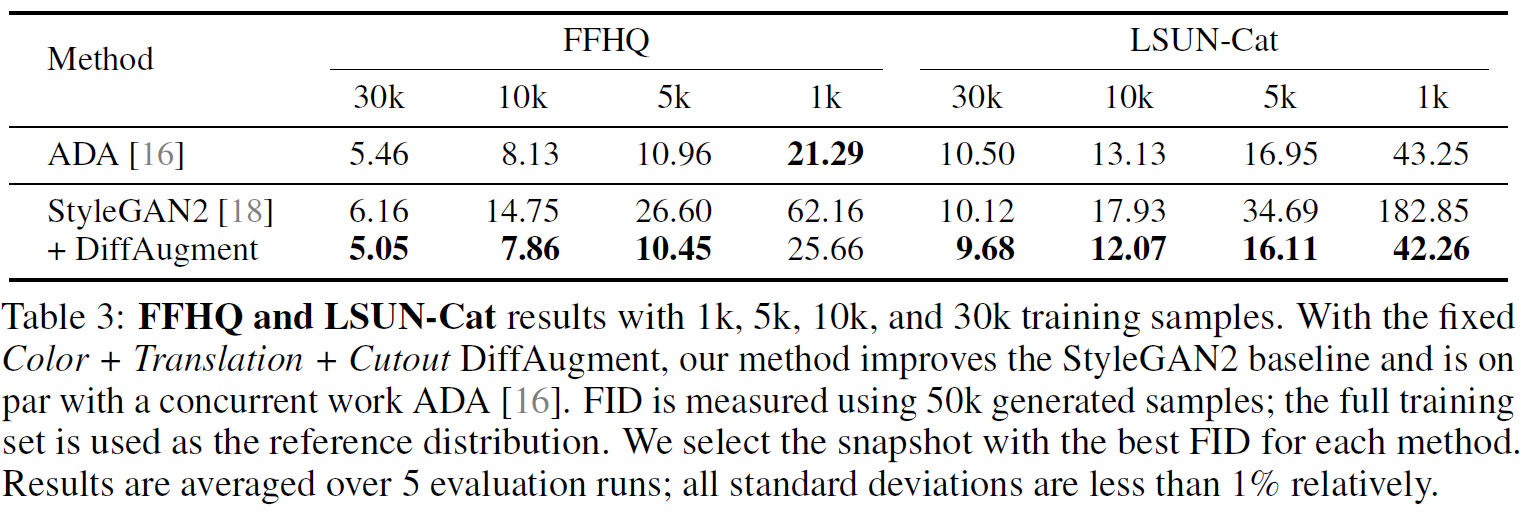
DiffAugment 방법의 타당성을 검증하기 위해 여러 가지 이미지 벤치마크 데이터셋에 대해서 실험을 진행하였다. 4.1-4.3에서는 1만 장 이상의 영상으로 이루어진 데이터셋에 대해서 실험한 결과를 보였다. 데이터를 전체 다 사용한 경우와 일부만 사용한 경우를 나누었고, DiffAugment를 적용한 결과와 적용하지 않은 결과를 비교하였다. Table 2-4에서 볼 수 있듯이, DiffAugment를 적용하였을 때 전체적으로 유의미한 성능 개선이 있었다.
4.1. ImageNet
4.2 FFHQ and LSUN-Cat
4.3 CIFAR-10 and CIFAR-100
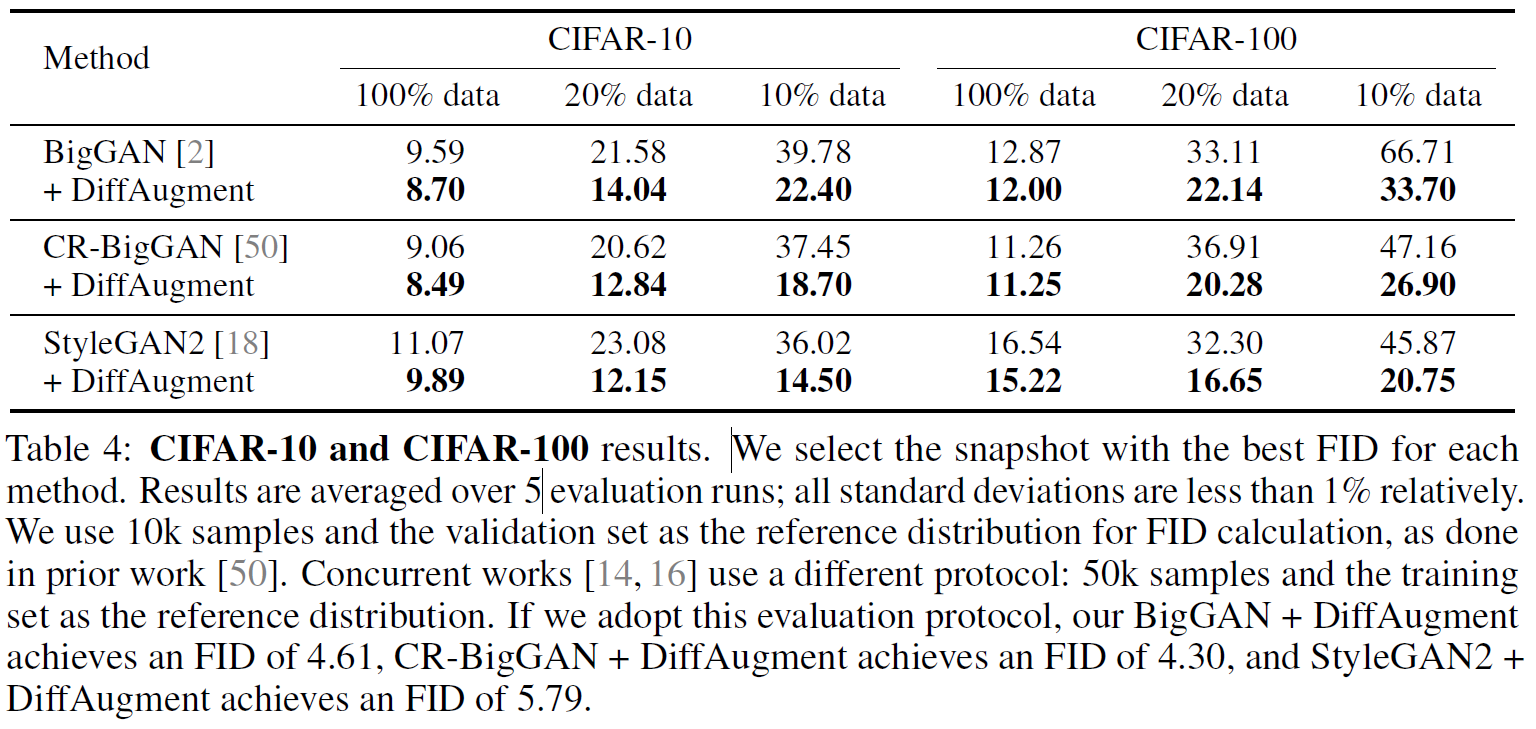
베이스라인 모델들은 Spectral Normalization, Consistency Regularization, R1 regularization 등의 최신 regularization technique 들을 적용하여 학습하였다. 하지만, 10% 이하 데이터 세팅에서는 만족스러운 결과를 얻지 못했다.
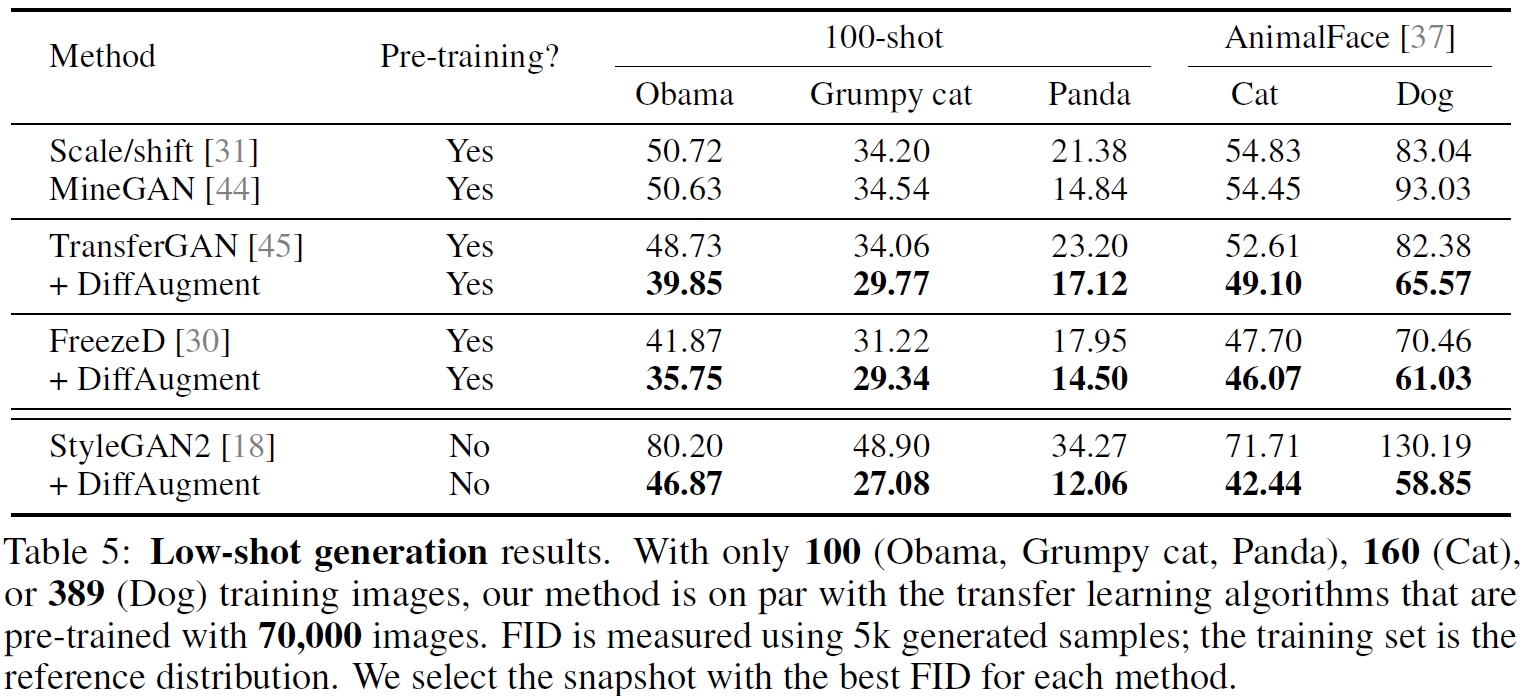
4.4 Low-Shot Generation
Table 5는 영상의 수가 1000개 미만의 데이터셋들에 대해 모델을 학습하여 평가한 결과이다. TransferGAN, FreezeD 등 기존 Transfer learning 기반 모델들도 DiffAugment를 적용하였을 때 성능 개선이 있었다.
4.5 Analysis
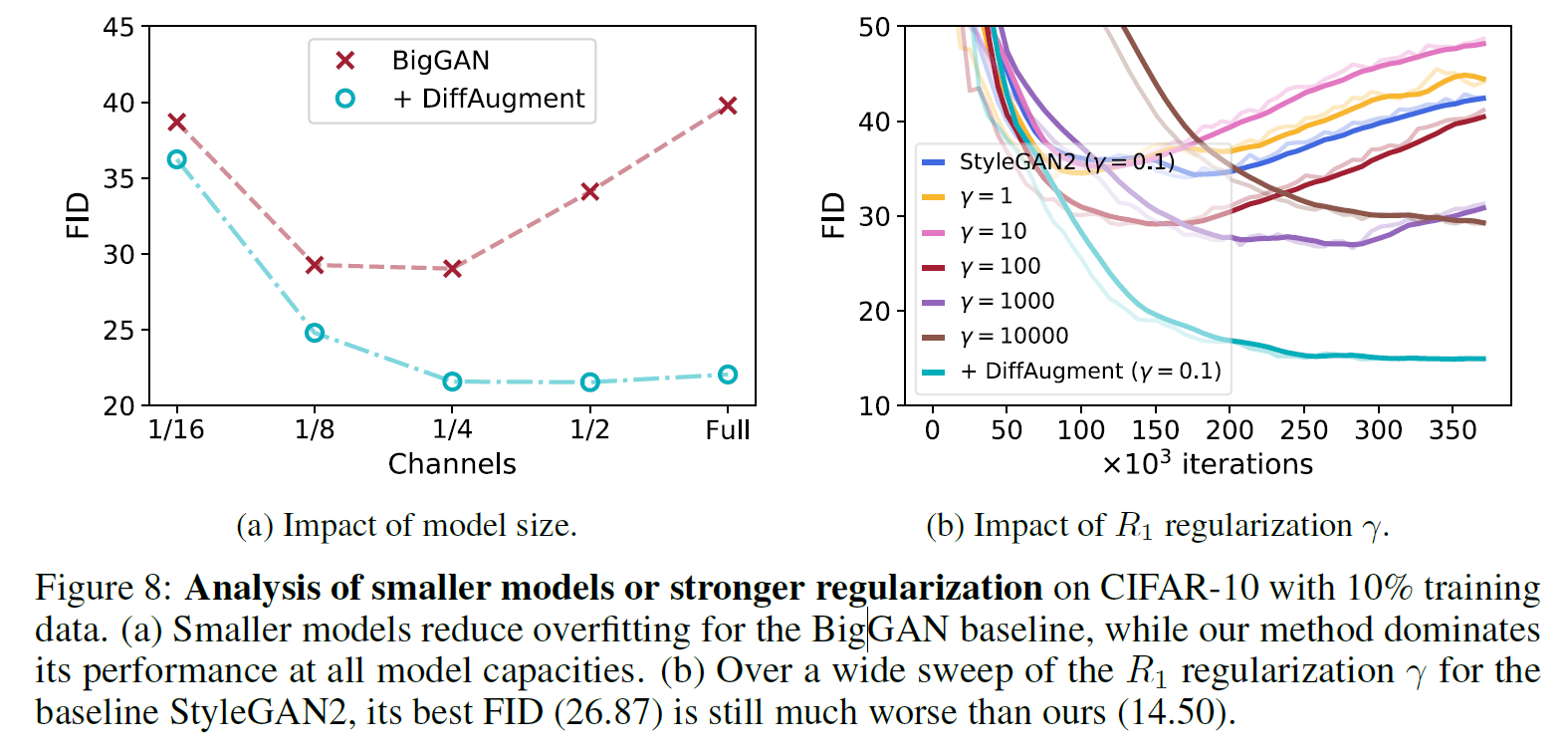
Model Size and Strong Regularization Matters?
- 데이터가 적은 경우 모델의 capacity가 클수록 DiffAugment의 효과가 컸다. (Fig. 8a)
- 데이터가 적은 경우 regularization을 강하게 적용해도 DiffAugment 만큼의 성능 개선이 없었다. (Fig. 8b)
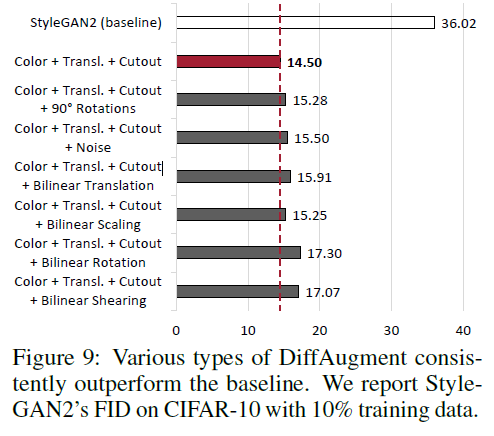
Choice of DiffAugment Matters?
최적의 data augmentation 조합을 찾기 위한 ablation study를 진행했다. Color + Translation + Cutout 조합이 가장 좋은 성능을 얻었다. 다른 data augmentation 기법을 추가했을 때 성능이 더 낮아졌다.
5. Conclusion
본 논문에서는 Real과 fake 샘플 모두를 증강(augment)하는 것이 discriminator의 overfitting 문제를 효과적으로 방지할 수 있으며, 데이터 증대(augmentation)는 generator와 discriminator의 학습 모두를 가능하게 하기 위해 미분 가능해야 함을 밝혔다. 이를 기반으로 데이터가 적을 때 GAN을 효과적으로 학습하기 위한 DiffAugment 방법을 제안하였고 실험을 통해 방법의 타당성을 입증하였다.
