[Review] Towards faster and stabilized GAN training for high-fidelity few-shot image synthesis
Paper Review

Bingchen Liu, et al., "Towards faster and stabilized GAN training for high-fidelity few-shot image synthesis", ICLR, 2021
1. Introduction
문제 제기
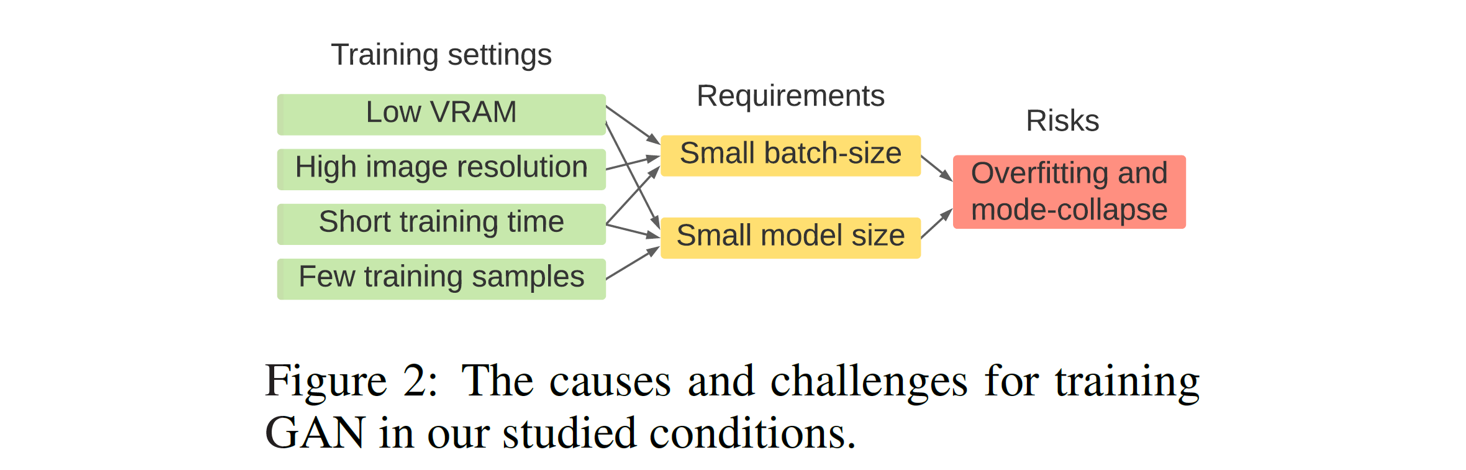
- 영상 합성 분야에서 Generative Adversarial Networks(GAN)는 큰 가능성을 보여주고 있지만, 고해상도 영상을 합성에는 큰 연산 비용과 많은 양의 학습 데이터가 요구되어 real-world 문제들에 적용하기 어렵다.
- 적은 양의 학습 데이터로 학습하기 위해 pre-training 후 fine-tuning 하는 기법이 제안되었으나, 1) 적합한 pre-training dataset을 찾기 어려울 수 있고, 2) pre-training으로 인한 bias 문제가 발생할 수 있어 연구가 더 필요하다.
문제 정의
- 적은 양의 학습 비용과 학습 데이터로 고해상도 영상을 합성할 수 있는 unconditional GAN을 고안
2. Related works
-
Speed up the GAN training
학습 시간을 줄이기 위한 방법들이 고안되었으나 합성 영상의 퀄리티가 저하되는 문제가 발생한다. -
Train GAN on high resolution
고해상도 영상을 합성하기 위한 여러 기법이 고안되었으나 큰 학습 비용과 많은 양의 학습 데이터를 요구하는 문제가 존재한다. -
Stabilize the GAN training
GAN의 학습 안정성을 높이기 위한 여러 연구가 진행되었으나 아직 낮은 해상도 수준(최대 128x128)밖에 이루어지지 않았다.
3. Method
저자는 효율적인 모델을 제안하기 위해, 기존 SOTA 모델과 비교해 작은 크기의 모델을 기본 구조로 선택하였다. 또한 Skip-layer channel-wise excitation module과 self-supervised discriminator 구조를 제안 및 적용하여 적은 연산 비용과 학습 데이터로 모델 학습이 가능하게 하였다.
3.1. Skip-layer channel-wise excitation
CNN 기반 GAN 모델은 높은 해상도의 영상을 합성하기 위해 깊은 generator 구조를 필요로 한다. 이 경우, layer의 수가 증가할수록 generator의 gradient flow가 약화되며 GAN의 학습 시간을 증가시킨다. 이를 완화하기 위해 논문에서는 skip-connection을 통해 layer 간의 gradient signal을 강화함으로써 모델을 깊게 쌓는 데 효과적으로 알려진 Residual Block(ResBlock) [1] 구조를 재구성 및 적용하여 학습 비용을 감소시켰다.
다음 figure는 generator의 구조를 보여준다.
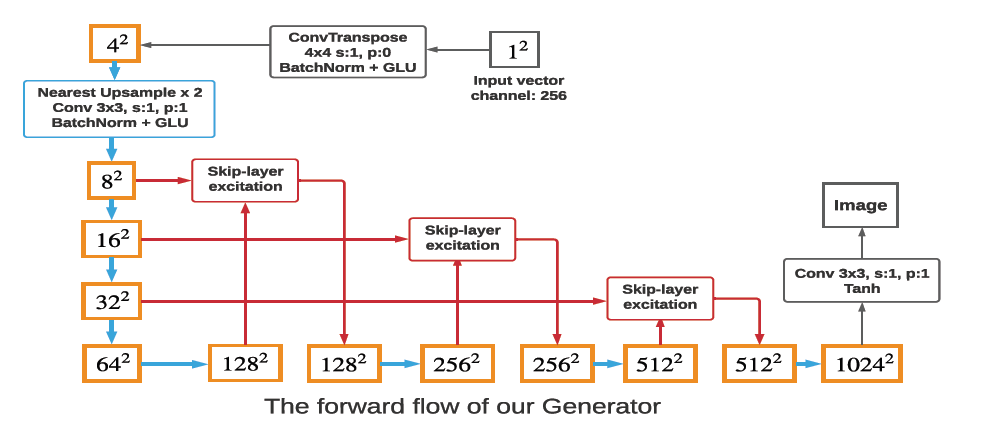
Skip-layer excitation(SLE) module의 구체적인 구조는 다음과 같다. Squeeze and excitation(SE) [2] module의 구조와 유사하며, 해당 모듈에서 영감을 얻은 것 같다.
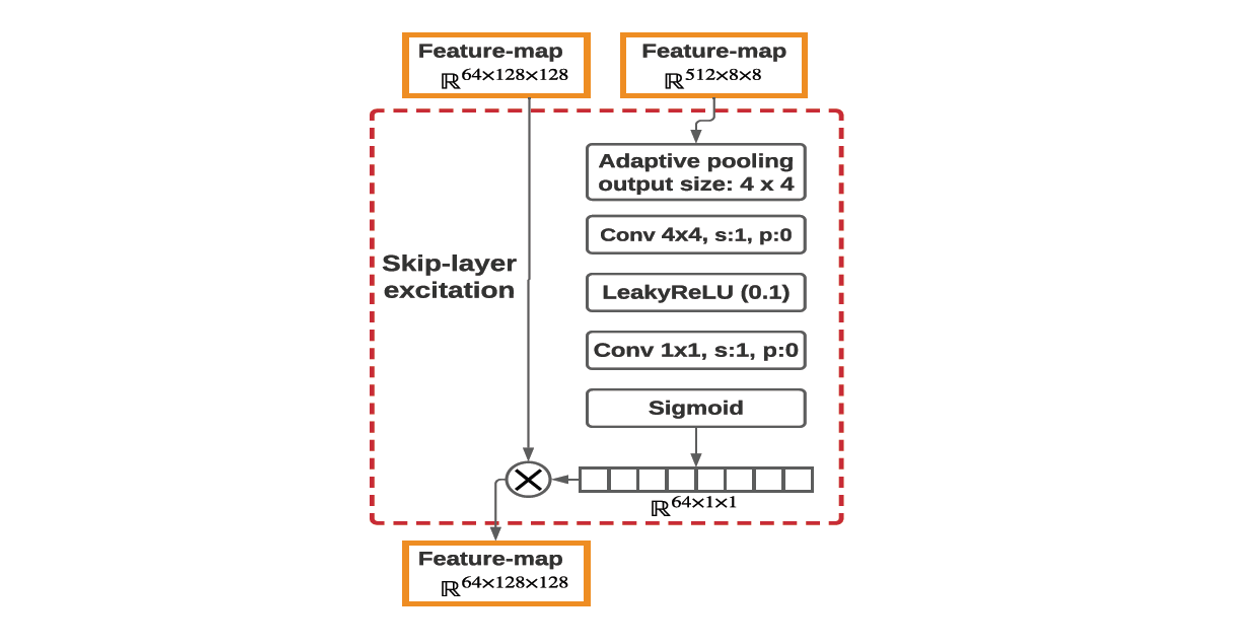
먼저 모듈은 shallow한 layer에서 추출한 낮은 해상도의 feature map을 입력으로 받아 학습 가능한 모듈을 통해 feature map을 가공한다(오른쪽 flow). 다음으로 가공한 feature map과 deep한 layer에서 추출한 높은 해상도의 feature map를 channel 축을 기준으로 곱한다(왼쪽 flow). 이를 간단하게 정리하면 SLE 모듈은 높은 해상도의 feature-map의 정보 중에서 의미 있는 정보들을 낮은 해상도의 feature-map을 통하여 스케일링한다.
위 과정을 도식화하면 다음과 같다.
: input, : output, : newtork, : trainable weight
저자는 Skip-layer channel-wise exciation(SLE) module은 기존 ResBlock에 비해 두 가지 개선점이 있다고 주장하였다.
1. SLE module은 skip-connection 구조에서 다른 feature map의 activation 값을 channel-wise multiplication으로 mix하여 기존 ResBlock의 element-wise addition과 비교해 적은 연산량으로 학습이 가능하다.
2. SLE module은 channel-wise multiplication을 통해 feature map을 mix하여 feature map의 spatial dimension이 달라도 적용 가능하다. SLE module은 멀리 떨어진 feature map 간에 skip-connection을 만들어 효율적으로 shortcut gradient flow를 발생시킨다.
기타 세부적인 구조에 대한 설명은 생략하기로 한다. 논문 참조 바람.
3.2. Self-supervised Discriminator
GAN 학습에서 학습 데이터의 부족은 discriminator의 overfitting을 유발한다. Regularization은 이를 완화하기 위한 대표적인 방법의 하나다. 논문에서는 discriminator의 self-supervised learning을 통한 새로운 regularization 기법을 제안하였다.
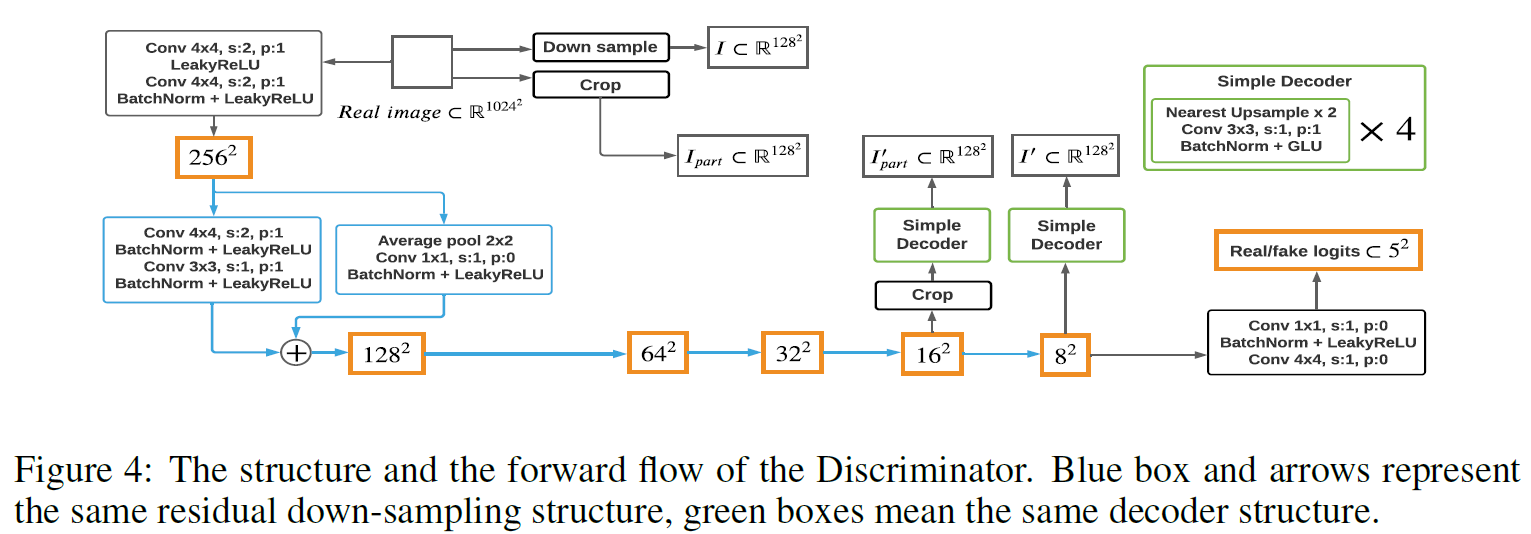
제안하는 아이디어는 간단하다. Discriminator를 decoder로 간주하고 레이어 중간에 auxiliary decoder를 추가하여 representation을 추출한다(Auto-encoder 구조를 따른다). 이때, representation과 real image 간의 reconstruction loss를 줄이는 방식으로 discriminator(decoder)와 auxiliary decoder를 학습한다. 논문에서는 일부를 crop한 영상과 downsample한 영상 두 가지에 대해서 reconstruction loss를 계산하였다.
위 방식으로 regularization을 적용했을 때, 저자는 discriminator가 입력으로부터 더 풍부한 representation을 추출할 수 있다고 주장한다. Auto-encoder를 통해 좋은 representation을 학습하는 것은 이미 잘 알려진 방법이기도 하고, SinGAN [3]에서도 reconstruction loss를 이용하여 단일 영상으로 모델 학습을 가능하였기 때문에, 제안하는 방법은 make sense 하게 들린다.
4. Experiment
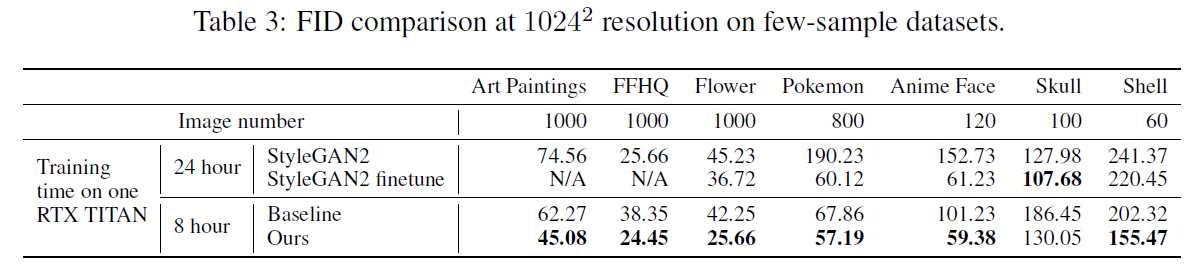
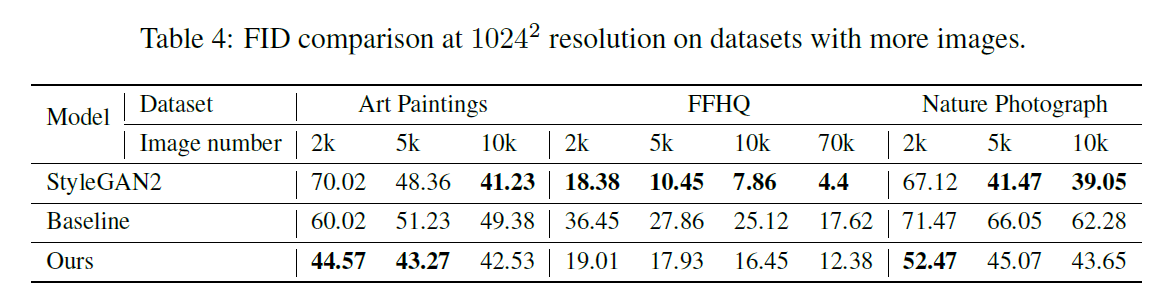
모델을 검증하기 위해 few-sample 데이터셋을 선정하여 베이스라인인 StyleGAN V2 [4]와 FastGAN 모델을 비교하였다. FastGAN은 StyleGAN V2과 비교해 일련의 few-sample 데이터셋들에 대해 3배 빠르게 학습되었다. 또한 few-sample 데이터셋들에 대해 대체로 FastGAN이 낮은 FID는 기록함을 확인할 수 있다. 다만 데이터가 늘어나면 늘어날수록 StyleGAN V2보다 결과가 좋지 않음을 확인할 수 있었다.
아래와 같이 질적인 평가에서도 StyleGAN V2와 비교해 더 좋은 결과를 보였다.

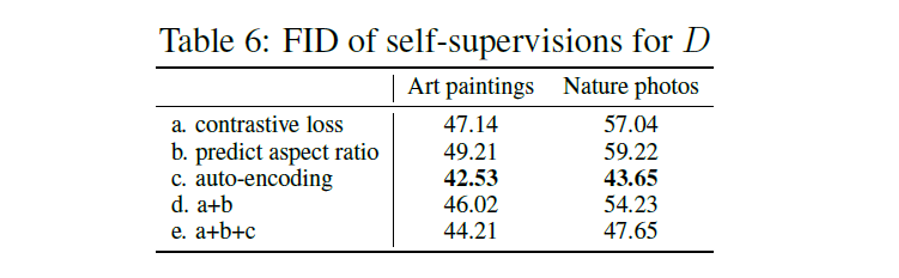
제안하는 regularization 기법을 평가하기 위해 ablation study를 수행하였다. 두 가지 다른 regularization 기법과 비교하였고 제안하는 방법(c. auto-encoding)만을 적용했을 때 FID가 가장 낮게 나온 것을 볼 수 있다.
5. Conclusion
본 논문에서는 적은 데이터로 GAN 모델을 학습하기 위한 모델 구조와 regularization 기법을 제안하였다. 제안하는 모델은 few-sample 데이터셋에 대해서 베이스라인보다 좋은 결과를 보였다.
논문에 대하여 한 줄 평을 남기자면, 주장하는 내용들이 대체로 납득할 만하나
SLE 모듈을 사용해야 하는 이유에 대해서 충분히 납득시켰는 지는 의문이 든다.
References
[1] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[2] Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[3] Shaham, Tamar Rott, Tali Dekel, and Tomer Michaeli. "Singan: Learning a generative model from a single natural image." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[4] Karras, Tero, et al. "Analyzing and improving the image quality of stylegan." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
