
Lin, C. H., Lee, H. Y., Cheng, Y. C., Tulyakov, S., & Yang, M. H. (2021, September). InfinityGAN: Towards Infinite-Pixel Image Synthesis. In International Conference on Learning Representations.
서론
무한대 해상도의 영상을 합성할 수 있는 모델을 설계할 수 있을까? 저자는 InfinityGAN을 통해 위 물음에 답하고자 했다.
사실 InfinityGAN은 무한대 해상도의 영상을 합성할 수 있는 최초의 모델은 아니다. 무한대 해상도의 영상을 합성할 수 있는 모델들은 이미 제안된 적이 있다[1, 2]. 하지만 모델들의 기능은 텍스쳐와 같이 반복적인 패턴을 보이는 영상의 합성에 국한되며, 비반복적 패턴을 보이는 실세계 영상(real-world image)의 합성은 불가능하다.
InfinityGAN은 실세계 영상에 초점을 맞추고, 비반복적인 패턴들을 합성할 수 있는 모델을 제안한다. 저자는 사람은 어떤 장면(scene)의 일부만 보고도 전체를 추측하는 것이 가능하다는 것에서 모티브를 얻었다고 한다. 전체에 대한 영상 패치(image patch)들만으로 학습하여 제한되지 않은 임의의 해상도의 영상을 합성할 수 있는 generator를 설계하였다고 주장한다.
동시대 연구로 ALIS[3]가 있는데, ALIS는 수평 축에 대해서만 임의의 해상도 영상 합성이 가능함을 실험적으로 보였지만, InfinityGAN은 수직 수평 양축으로 동시에 임의의 해상도 영상 합성이 가능함을 보였다는 차별점이 있다. ALIS 논문은 InfinityGAN과 함께 읽어보길 추천한다.
InfinityGAN
Overview
임의의 영상이 있을 때, 영상은 전역적인(global) 특징과 지역적인(local) 특징으로 구분 지어 묘사(describe)될 수 있다. 아래 폭포 사진을 보자. 폭포, 산, 강, 하늘 등의 패턴들은 넓은 영역에 걸쳐 나타나며 전역적으로 일관된(coherent) 형태를 지닌다. 산의 능선이 연속적으로 나타나지 않고 부자연스럽게 끊어져 있다고 한다면 영상이 왜곡되어 있다고 느낄 것이다. 반면에 들판의 풀과 같은 패턴들은 상대적으로 지역적인 특징을 가지며 유사한 패턴이 반복적으로 나타난다.

저자는 위에 기술한 특징들을 가정하고 모델을 설계하였다. InfinityGAN은 먼저 전역적으로 나타나는 패턴들을 형성하고, 이를 바탕으로 지역 단위로 질감이나 디테일 등의 특징들을 추가하는 방식으로 영상을 합성한다.
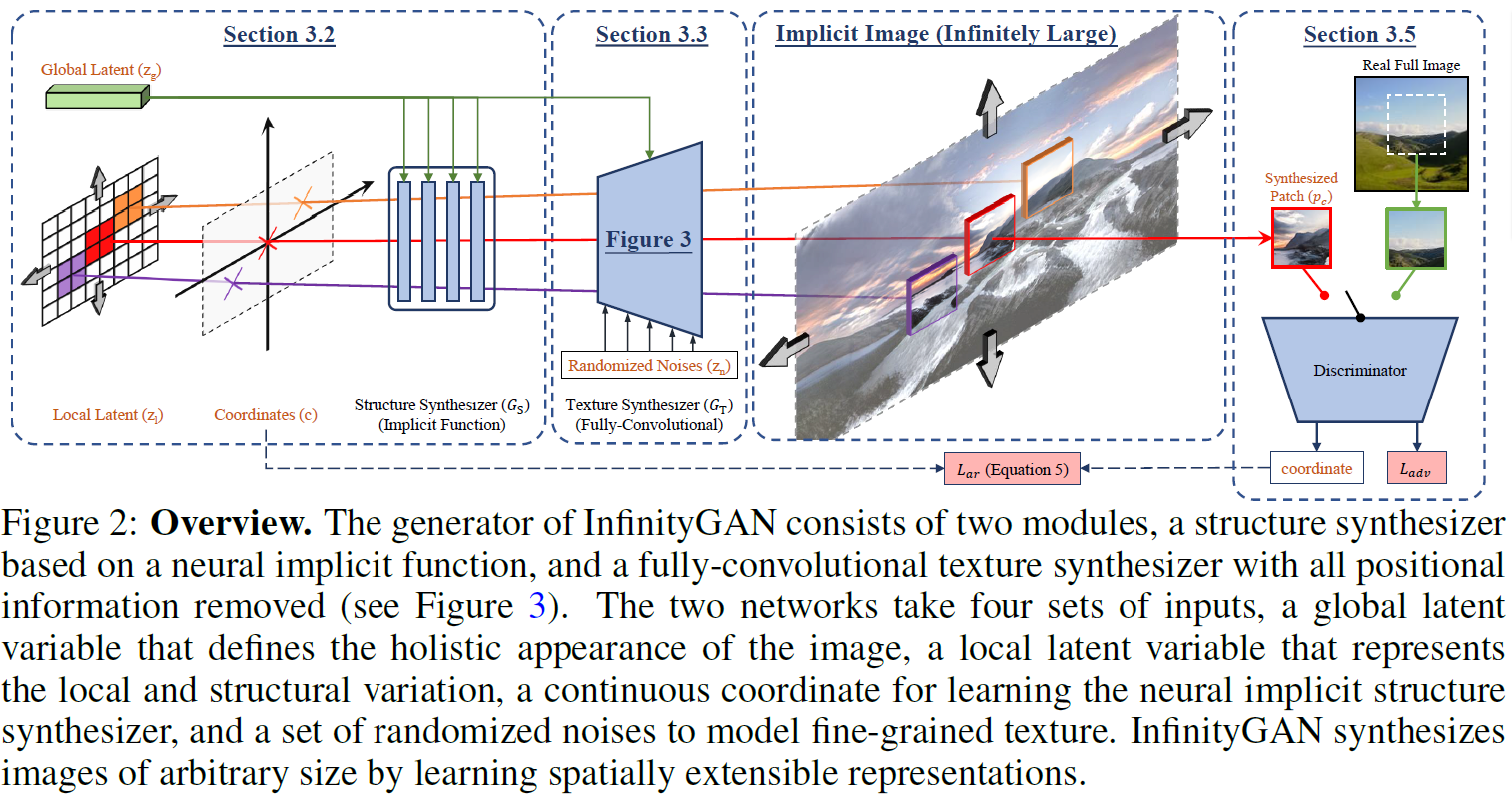
InfinityGAN의 generator 는 structure synthesizer 와 texture synthesizer 로 구성된다. 는 neural implicit function으로 좌표와 함께 하위 지역(sub-region)을 샘플링하고 지역적이고 구조적인 특징들을 생성한다. 는 fully convolutional StyleGAN v2[4]로 패치 단위로 질감을 입히고 최종 영상을 렌더링한다. 간략히 설명하자면 는 전체 구조를 형성하고 는 형성한 구조에 질감과 세부 특징들을 입힌다.
A. Structure Synthesizer
Structure synthesizer 는 세 가지 latent variable 를 입력으로 받아 structural latent variable 을 생성한다.
여기서 (, )는 수직 수평 좌표로 T는 사인 함수의 주기로 정의된다.
는 전체 영상의 형태를 표현(represent)하는 global latent variable로, 표준 정규 분포로부터 샘플링되어 feature modulation[4] 기법을 통해 각 레이어에 주입된다. 은 영상 안의 패턴(image content)들의 지역적인 특징을 표현하는 local latent variable이다. Fig.2의 Local Latent를 보면 격자 형태로 나누어져 있는데, Latent 각각이 최종 출력 영상에서 지역적인 패치에 대응된다. 은 수직 수평 공간 차원(spatial dimension)에 대해 독립적으로 샘플링된다.
마지막으로 는 좌표 그리드(coordinate grid)로 전체 영역 중 합성 이미지 패치가 샘플링되는 위치를 표현한다. 논문에서는 (1) 수평 축으로 자기 유사성을 지니고 (2) 수평 축으로 빠르게 포화(rapid saturation)되는 landscape 영상의 특성을 prior로 가정하였다. 수평 축으로는 기존 사인 함수와 코사인 함수로 구성된 positional encoding[5]을 사용하였고 수직 축으로는 하이퍼볼릭 탄젠트를 사용하여 빠르게 포화되는 특성을 표현하였다.
추가로 mode-collapse를 완화하기 위해 mode-seeking diversity loss[6, 7]를 적용하고 학습 안정성을 위해 feature unfolding[8] 기법을 적용하였다.
B. Texture Synthesizer
Texture synthesizer 는 global synthesizer가 생성한 local structure 을 입력으로 다양한 local texture를 생성하는 것을 목표로 한다. 모델은 전역적인 형태를 표현하는 global latent인 , 지역적인 구조를 표현하는 local structural latent인 , 디테일의 다양성을 위한 노이즈 벡터 세 가지를 입력으로 특정 위치의 패치 영상 를 합성한다.
는 StyleGAN v2를 기반으로 구현되었다. Fixed constant noise는 로 대체되었고, 은 의 각 레이어에 주입된다. 는 앞서 와 마찬가지로 feature modulation을 통해 모델에 주입된다.
패치 단위로 영상을 합성하여 전체 영상을 합성할 때, 저자는 다음 세 가지 이유를 들어 의 모든 제로 패딩을 제거하는 것이 필수적이다고 주장한다.
- 고정된 크기의 영상으로 학습한 generator는 패딩 패턴을 암기하며 다른 크기의 영상을 합성할 때 보지 못한 패딩 패턴에 취약하다.
- 제로 패딩은 영상의 테두리 부분에 한정하여 위치 정보(positional information)를 제공한다[9].
- 패딩의 존재는 아래 그림과 같이 패치들이 결합할 때 절단면을 발생시킨다.
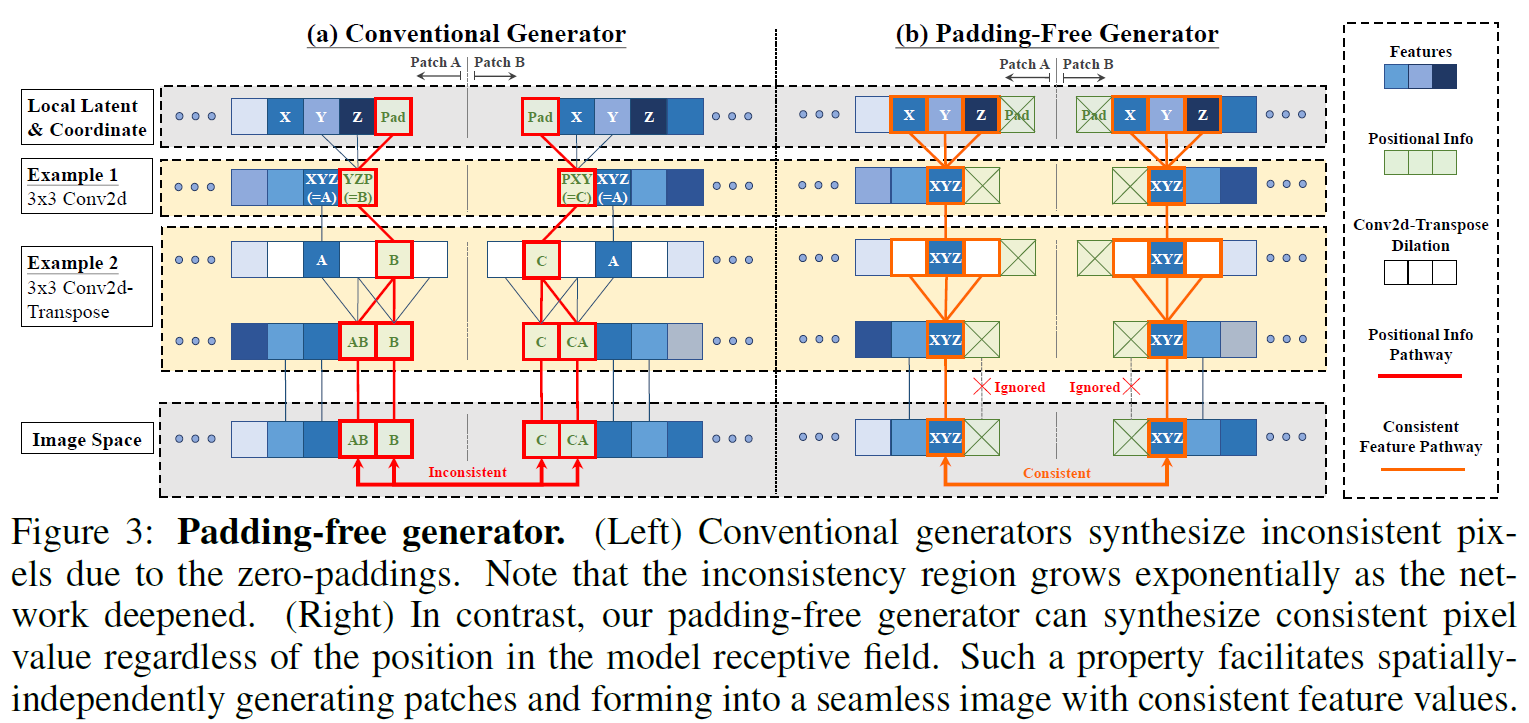
(a)는 패딩을 사용하는 전통적인 CNN 기반 generator 구조이다. 두 패치가 결합할 때 패딩으로 인해 결합 면에서 값의 불일치(inconsistency)가 발생한다. 반대로 (b)는 저자가 제안하는 패딩을 사용하지 않는 padding-free generator 구조이다. 저자는 convolution과 transposed convolution을 교차로 쌓는 방식으로 padding을 사용하지 않는 generator 구조를 고안하였다. Padding-free generator를 사용할 경우, 결합 면에서 값이 일치되며(consistency) 매끄럽게(seamless) 패치를 연결할 수 있다. 모델 구조에 대한 자세한 설명은 논문의 appendix를 참고하길 바란다.
C. Model Training
Generator와 discriminator는 각각 다음 손실 함수를 통해 학습한다.
Adversarial Loss 는 non-saturating logistic loss를 사용하였다. 나머지 항들은 regularization term으로 는 regularization[11], 는 mode-seeking diversity loss[6], 는 path length regularization[4]을 의미한다. 은 수직 방향으로 분포를 잘 학습하기 위해 도입한 regularization term이며, G와 D는 패치의 수직 위치를 예측하도록 학습된다. 은 예측한 위치와 실제 위치의 loss로 정의된다. 각 는 각 term에 대한 가중치이다. 논문에서는 , , , 를 사용하였다고 한다.
실험 결과
Generation at extended size
저자는 모델의 성능을 검증하고자 학습 때 사용한 영상보다 큰 영상을 합성하여 결과를 비교하였다. 아래 표에서 보듯이 베이스라인 모델은 SinGAN[12], COCO-GAN[13], StyleGAN v2[4]로 설정하였다. 작은 크기의 영상으로 학습하여 무한대로 확장되는 초고해상도 영상을 합성할 수 있는 기존 모델이 없으므로 완벽하게 공평한 비교는 불가능했다고 한다. 이에 지면을 활용하여 공평한 비교를 위해 노력했음을 밝혔다. 참고로 동시대 연구인 ALIS[3]와의 차별점은 appendix에서 다루었다.

그림을 보면, 베이스라인 모델들은 자연스러운 영상을 합성하지 못하나 InfinityGAN은 자연스러운 영상을 합성함을 볼 수 있다.
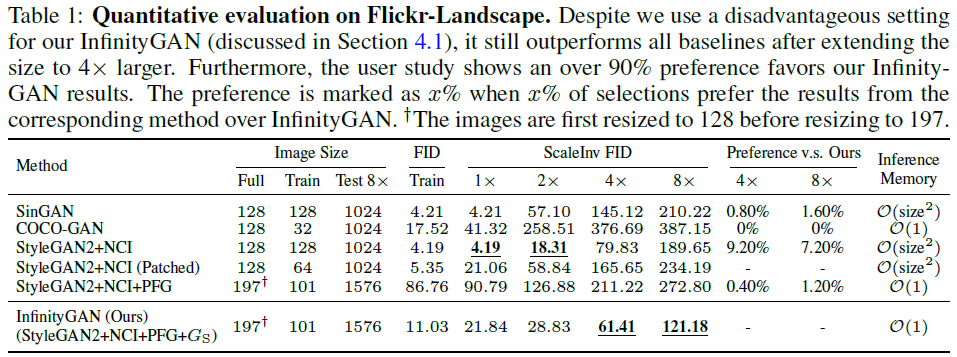
표를 보면, InfinityGAN이 학습 영상의 크기의 4배 이상으로 확장된 영상을 합성할 때 ScaleInv FID에 대해 더 좋은 결과를 얻었다. 여기서 ScaleInv는 해당 실험의 평가를 위해 고안된 메트릭으로, 합성한 영상을 학습 영상 크기 수준으로 줄인 후 계산하는 FID이다. 정성적으로나 정량적으로나 InfinityGAN은 베이스라인 모델에 비해 좋은 결과를 보였다.
Applications
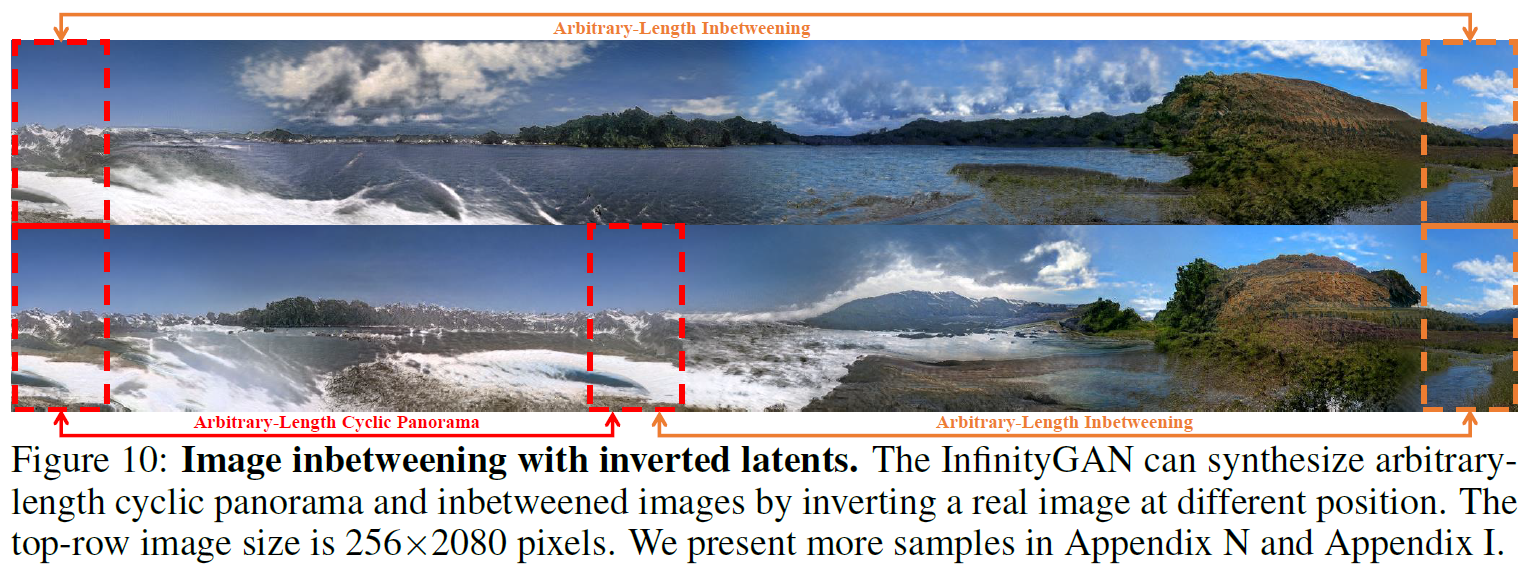
InfinityGAN의 우수성을 주장하기 위해 spatial style fusion, outpainting via GAN Inversion, image inbetweening with inverted latent variables 등의 application에 관한 실험 결과도 제시하였다. 분량상 이 부분에 대한 설명은 생략하기로 한다.

결론
저자는 학습 영상의 크기에 국한되지 않고 더 큰 영상을 합성할 수 있는 모델을 제안하였다. 고정적이고 비대칭적인 위치 정보(positional information)를 주는 패딩을 제거함으로써 패치 단위로 합성하여 큰 영상을 합성하는 방법은 새롭고 흥미로운 아이디어라고 본다.
아쉬운 점은 상대적으로 복잡한 패턴의 영상도 합성할 수 있는지 보여주지 않은 것이다. 실험에 사용된 데이터는 비교적 패턴이 단순한 풍경 영상에 국한되었다. 또한 저자도 밝혔듯이 제안하는 구조로는 넓은 영역에 걸쳐 나타나는 전역적 패턴을 합성하기 어렵다는 한계가 존재한다.
References
[1] Alexei A Efros and Thomas K Leung. Texture synthesis by non-parametric sampling. In IEEE International Conference on Computer Vision, 1999.
[2] Wenqi Xian, Patsorn Sangkloy, Varun Agrawal, Amit Raj, Jingwan Lu, Chen Fang, Fisher Yu, and James Hays. Texturegan: Controlling deep image synthesis with texture patches. In IEEE Conference on Computer Vision and Pattern Recognition, 2018.
[3] Ivan Skorokhodov, Grigorii Sotnikov, and Mohamed Elhoseiny. Aligning latent and image spaces to connect the unconnectable. In IEEE International Conference on Computer Vision, 2021.
[4] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., & Aila, T. (2020). Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8110-8119).
[5] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[6] Qi Mao, Hsin-Ying Lee, Hung-Yu Tseng, Siwei Ma, and Ming-Hsuan Yang. Mode seeking generative adversarial networks for diverse image synthesis. In IEEE Conference on Computer Vision and Pattern Recognition, 2019.
[7] Hsin-Ying Lee, Hung-Yu Tseng, Qi Mao, Jia-Bin Huang, Yu-Ding Lu, Maneesh Kumar Singh, and Ming-Hsuan Yang. Drit++: Diverse image-to-image translation viadisentangled representations. International Journal of Computer Vision, pp. 1–16, 2020.
[8] Yinbo Chen, Sifei Liu, and Xiaolong Wang. Learning continuous image representation with local implicit image function. In IEEE Conference on Computer Vision and Pattern Recognition, 2021.
[9] Islam, M. A., Jia, S., & Bruce, N. D. (2020). How much position information do convolutional neural networks encode?. arXiv preprint arXiv:2001.08248.
[10] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Neural Information Processing Systems, 2014.
[11] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? In International Conference on Machine Learning, 2018.
[12] Tamar Rott Shaham, Tali Dekel, and Tomer Michaeli. Singan: Learning a generative model from a single natural image. In IEEE International Conference on Computer Vision, 2019.
[13] Chieh Hubert Lin, Chia-Che Chang, Yu-Sheng Chen, Da-Cheng Juan, Wei Wei, and Hwann-Tzong Chen. COCO-GAN: Generation by parts via conditional coordinating. In IEEE International Conference on Computer Vision, 2019.
