💡 End-to-End Multi-Task Learning with Attention_논문 리뷰
📌 Introduction
training multiple tasks whilst learning a shared representation two challenges
1) Network Architecture (how to share)
- Network Architecture는 task-shared와 task-specific feature 모두를 표현해야 한다.
- to avoid overfitting (learn generalisable representation)
- to avoid underfitting (learn features tailored to each task)
2) Loss function (how to balance task)
- Loss function은 모든 task를 동등한 중요도로 배우되, 쉬운 task가 지배하는 것 없이 가능하게 해야한다.
- automatically or design a network
위 두 가지 중 하나만 해결한 연구들은 존재하지만, 두 가지 모두를 해결한 연구는 없었다. 이 연구에서는 위의 두 가지 이슈를 모두 해결하기 위해
(i) task-shared와 task-specific feature 모두를 자동으로 배울 수 있는 network design
(ii) loss weighting scheme 선택에 대한 내재적인 robustness를 배우는 일체화된 접근법을 제안한다.
📌 Architecture Design
MTAN은 두 가지 주요 컴포넌트로 구성된다.
- a single shared network : 특정 task에 기반하여 설계될 수 있다. (learns a compact global feature pool across all tasks)
- K task-specific attention networks : 각각의 task-specific 네트워크는 attention 모듈들로 이루어져 있다. (each attention module applies a soft attention mask)
- shared network에서 생성한 feature map
- 이 위에 attention mask(=feature selector_end to end automatically learned)를 적용
- 해당 task에 필요한 특정 정보를 추출
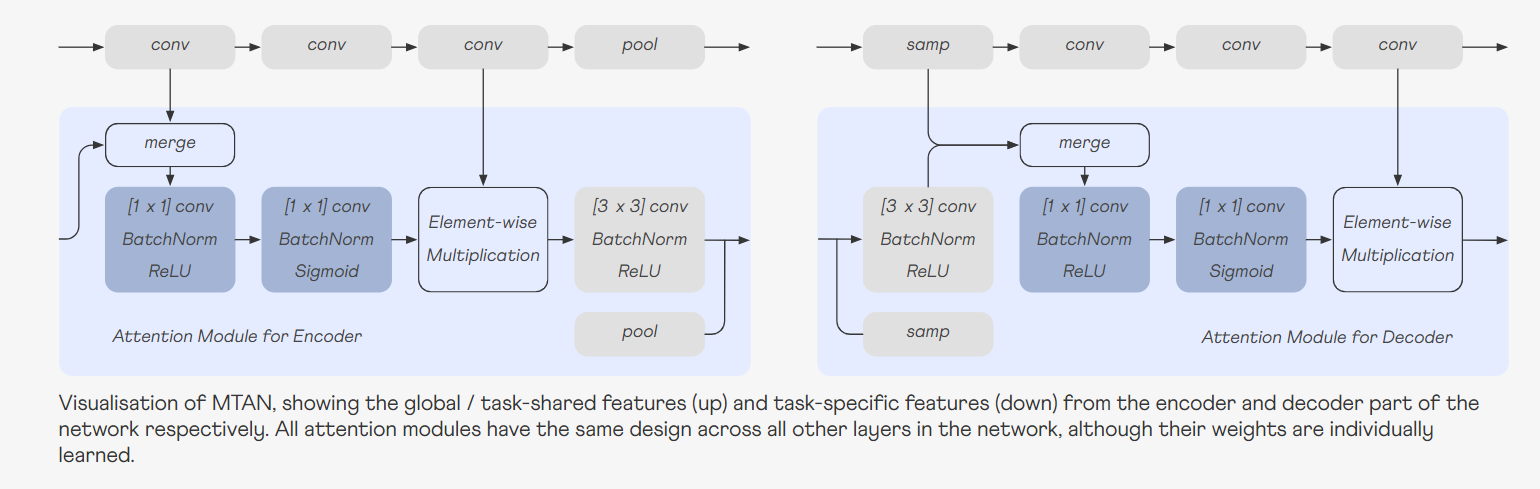
1) 각 task-specific attention module은 [1×1] 커널로 구성된 두 개의 convolutional layer만을 포함한다.
→ 각 태스크마다 매우 적은 양의 파라미터를 도입함으로써, 네트워크의 효율성을 높인다.
2) [3 × 3] convolutional layer는 공유 feature extractor를 나타내며, 다른 attention module로 전달하기 위해 사용된다.
3) pooling 또는 sampling layer가 해당 해상도에 맞추기 위해 따라온다.
- Performance Expectation
만약 어떤 attention mask가 1에 가깝다면 (즉, identity map이 되면), attended features는 global feature maps과 동일해진다.
즉, 해당 task들이 모든 features를 공유하게 된다.
: 이러한 설계 방식은 MTAN이 다중 task 학습에서 파라미터 효율성과 성능 사이의 균형을 잘 유지하며 각각의 task에 필요한 고유한 feature들과 공통적인 feature들 모두를 잘 추출할 수 있음을 의미
📌 Experiments
-
Baselines
5가지 다른 네트워크 아키텍처(2개의 단일 태스크 + 3개의 다중 태스크)를 기반으로 MTAN을 비교한다. 모두 SegNet이라는 동일한 backbone을 기반으로 한다.- Single-Task, One Task : 단일 태스크 학습을 위한 기본 SegNet
- Single-Task, STAN : 단일 태스크를 수행하는 동안 제안된 MTAN을 직접 적용하는 Single-Task Attention Network
- Multi-Task, Split (Wide, Deep) : 마지막 레이어에서 각 특정 task에 대한 최종 예측을 위해 분할하는 표준 다중 태스크 학습(hard-parameter sharing)
- Multi-task, Dense : 공유 네트워크와 task-specific 네트워크가 함께 있으며, 각 task-specific 네트워크는 shared 네트워크로부터 모든 feature를 받음
-
Dynamic Weight Average (DWA)
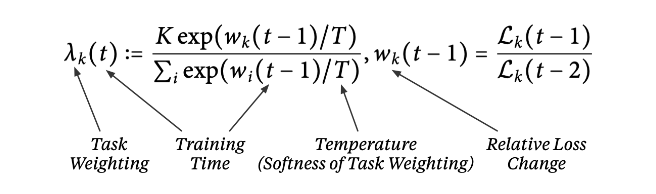
DWA는 GradNorm에서 영감을 받아 각 작업의 손실 변화율에 따라 작업 가중치를 평균화하는 방식으로 학습된다. -
Results on Image-to-Image Predictions
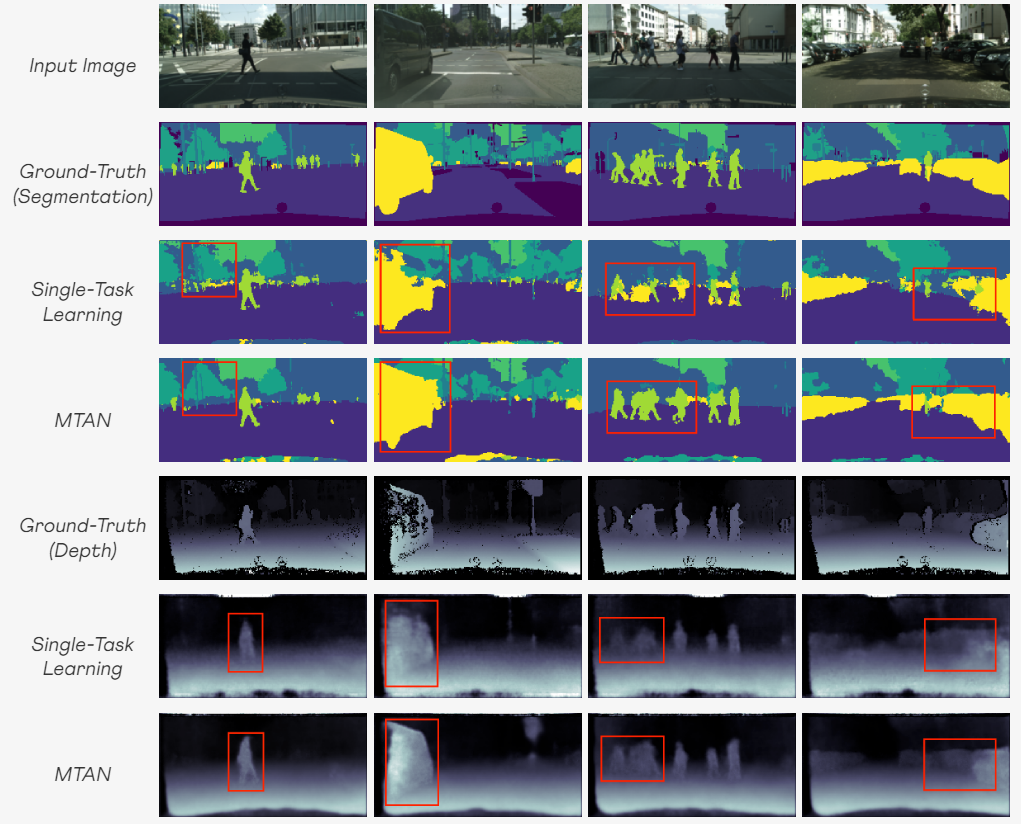
MTAN이 모든 baseline들을 능가한다. CityScapes 데이터셋에서 객체의 경계가 확실히 더 잘 드러나는 등 다중태스크 학습 접근법이 기본 싱글태스크 학습보다 우수하다는 것을 알 수 있다. -
Robustness to Task Weighting Schemes
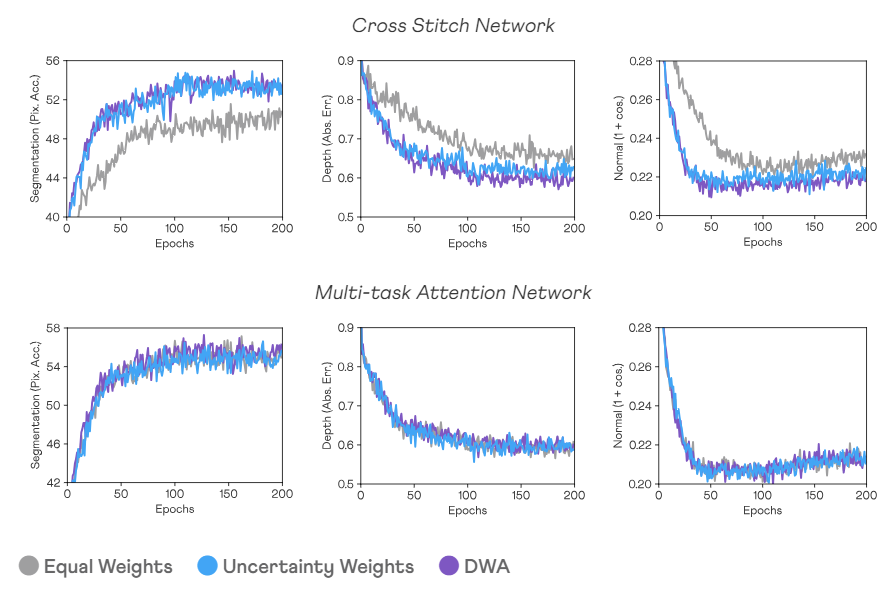
MTAN은 다양한 손실 함수 가중치 체계에 걸쳐 높은 성능과 robustness를 유지 -
Visualisation of Attended Features

CityScapes 데이터셋에 기반한 네트워크에서 학습된 첫 번째 레이어의 attention mask를 시각화하여 각 task에 유용한 부분에 집중하고 정보가 없는 부분을 마스킹하는 feature selector -
Results on Many-to-Many Predictions (Visual Decathlon Challenge)
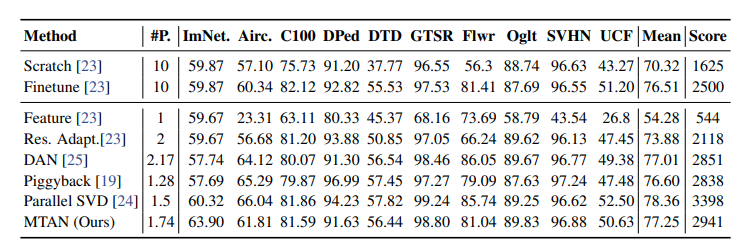
MTAN은 복잡한 정규화 전략 없이도 대부분의 baseline들을 능가한다.
📌 Conclusion
-
Multi-Task Attention Network(MTAN)라는 새로운 다중 태스크 학습 방법
global feature pool과 각 태스크에 대한 task-specific attention 모듈로 구성되어 있고, 이를 통해 task-shared와 task-specific feature 모두를 end-to-end 방식으로 자동으로 학습할 수 있다. -
NYUv2 및 CityScapes 데이터셋에서의 여러 dense-prediction 작업과 Visual Decathlon Challenge에서의 여러 이미지 분류 작업에 대한 실험 결과, MTAN 방법은 다른 방법들을 능가하거나 경쟁력있는 성능을 보였으며, 손실 함수에서 사용된 특정 task 가중치 체계에 대해서도 안정성을 보였다.
-
MTAN의 attention mask를 통한 가중치 공유 능력 덕분에, MTAN은 파라미터에 효율적이면서 좋은 성능을 보인다.
