💡 What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA_논문 리뷰
📌 Introduction
연산, Model size, data size가 커질 수록 LM의 성능이 좋아진다는 연구의 논문이 발표된 이후, LM size를 키우는 연구들이 많이 나오게 되었다. 그 중 하나가 GPT-3이다. GPT-3는 In-Context Learning으로 Fine-Tuning없이 다양한 task를 수행할 수 있다.
하지만 이러한 능력이
1) 다른 언어에서도 똑같이 적용이 될지,
2) Hyper-scale LM으로 무엇을 할 수 있을지
위 두 가지 의문에 대한 논문이 바로 What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA 이다.
GPT-3에는 아래의 issue들이 있다.
1. the language composition of the training corpus is heavily skewed towards English with 92.7%
2. while it is pragmatic and useful to know the capabilites of various sized models, we only have access of models of 13B and 175B but none in between.
3. advanced prompt-based learning methods have not yet been experimented for an in-context large-scale LM learner.
이 논문은 위 issue들을 다루고 있다.
📌 Model Structure
GPT-3의 구조에서 크게 변화된 부분은 없다
- Transformer decoder 82B parameter size
📌 Tokenization
- Morph-aware byte-level BPE
byte-level encoding + BPE + 형태소 분석기 → 문장을 공백과 형태소 기준으로 미리 나눈 후에, BPE를 사용
Tokenization은 어떻게 텍스트를 학습 가능한 토큰으로 나누는지의 문제이다.
HyperCLOVA는 뜻을 갖는 가장 작은 단위인 형태소(morpheme)를 기반으로 토큰을 나누어 좋은 성능을 낼 수 있게 하였다.
📌 Data Description
GPT-3에서 Korean data가 차지하는 비율은 불과 약 0.02%로 매우 적다.
→ Large Korean corpus를 construct 하는 것이 중요하다.
→ 562B 한국어 데이터

블로그, 카페, 뉴스 등에서 총 562B의 한국어 데이터로 훈련되었다.
📌 Model and Learning
-
Model : based on megatron - LM
-
Trained on : NVIDIA superpod
-
Optimizer : AdamW with cosine learning rate scheduling and weight decay
-
Mini-batch size : 1024
-
Model size : set near exponential interpolation from 13B to 175B OpenAI GPT-3
GPT-3의 경우 중규모의 모델 실험이 X, 중규모 모델에선 어떤 성능이 나오는지 보고자 함. -
Prompt Optimization : Prompt-Based Tuning + P-tuning
*P-tuning (전체 파라미터 입력단에 추가 파라미터를 두어 성능을 높이는 것)
"p-tuning enables HyperCLOVA to perform comparatives with no parameter update of the main model."
📌 Experimental Result
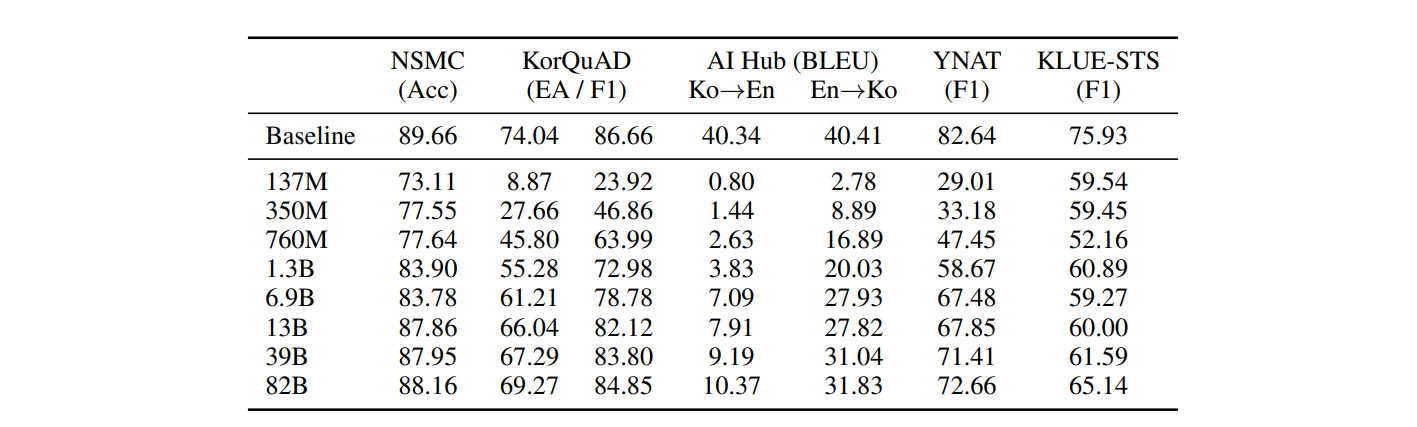
다양한 task에 대해 Fine-tuned된 Baseline에 근접하는 성능을 보이고 있다.
다만, Ko→En task의 성능이 저조하게 나왔는데 이는 학습시킨 데이터에 English corpus가 부족했기 때문일 것 같다.
📌 Discussion on Industrial Impacts
-
HyperCLOVA Studio
: the place for building and communicating the shared artifact generated by HyperCLOVA- provide a GUI interface
- support API end point
-
Case Studies on HyperCLOVA Studio
- Character bot
- Zero-shot transfer data augmentation
- Title of promoting event

-
No/Low Code AI Paradigm
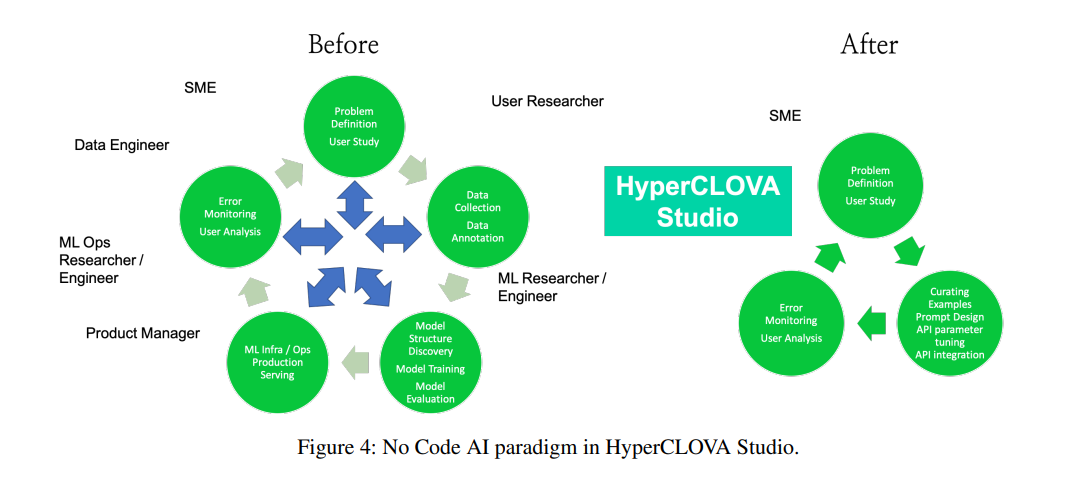
📌 Conclusion
-
Introduced HyperCLOVA, a large-scale Korean in-context learning based LM with nearly 100B parameters, by constructing a large Korean-centric corpus of 360B tokens
-
Discovered the effect of language-specific tokenization on large-scale in-context LMs for training corpus of non-English languages
-
Explored zero-shot and few-shot capabilities of mid-size HyperCLOVA with 39B and 92B parameters and find that prompt-based tuning can enhance the performance outperforming state-of-the-art on downstream tasks
-
Argued the possibility of realizing No Code AI by designing and applying HyperCLOVA Studio to three in-house applications
