🔎 논문 리뷰
1.[논문 리뷰] What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA

연산, Model size, data size가 커질 수록 LM의 성능이 좋아진다는 연구의 논문이 발표된 이후, LM size를 키우는 연구들이 많이 나오게 되었다. 그 중 하나가 GPT-3이다. GPT-3는 In-Context Learning으로 Fine-Tuning
2.[논문 리뷰] End-to-End Multi-Task Learning with Attention
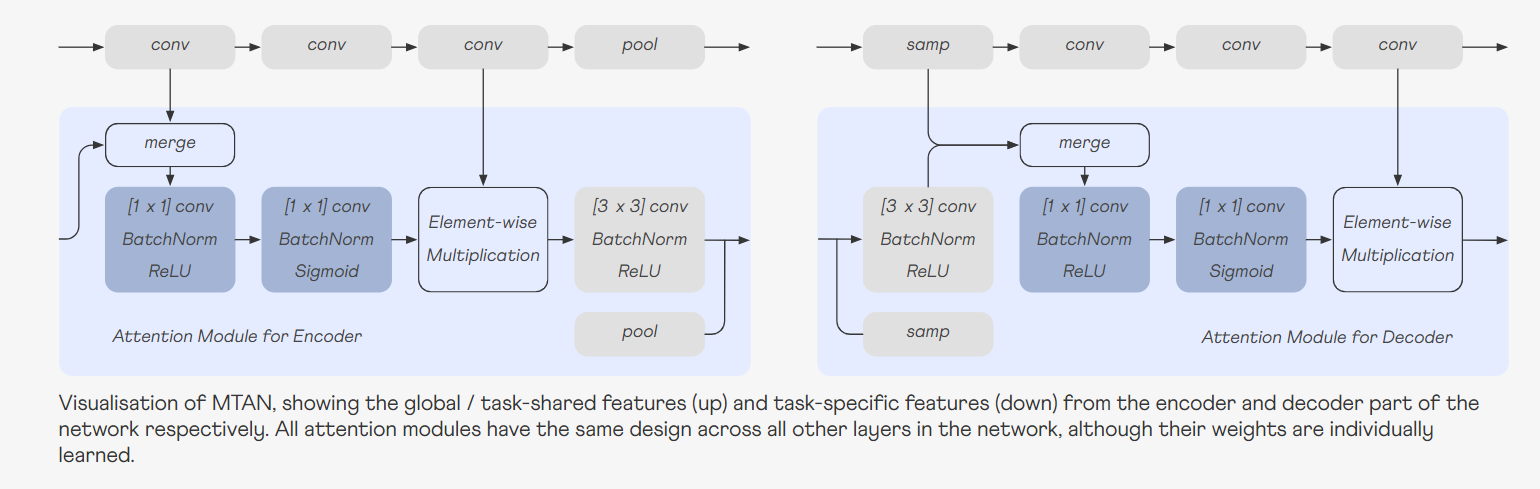
training multiple tasks whilst learning a shared representation two challenges1) Network Architecture (how to share)Network Architecture는 task-shared와
3.[논문 리뷰] iCaRL: Incremental Classifier and Representation Learning
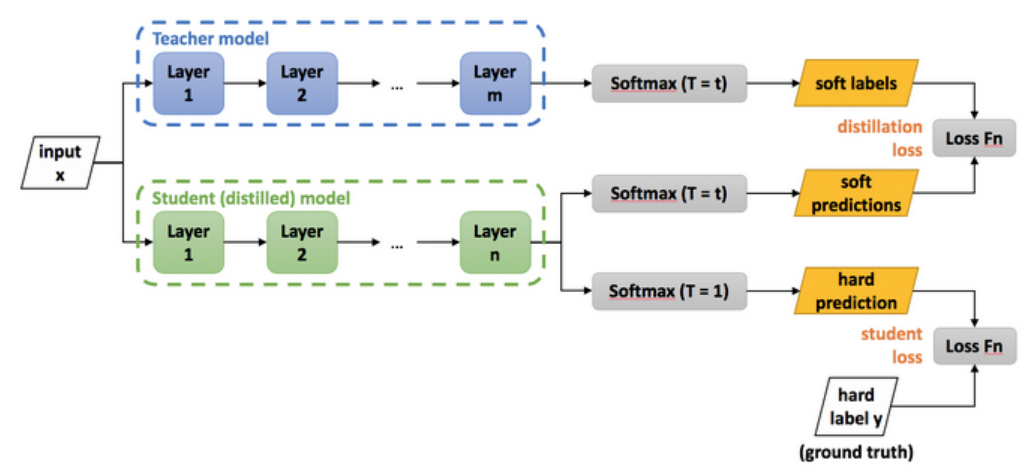
논문을 읽다가 distillation 개념에 대해 짚고 넘어가야할 것 같아서 찾아보았다.Knowledge Distillation(지식 증류)란 쉽게 말해 학습된 모델로부터 지식을 추출하는 것이다. Knowledge Distillation은 우리가 정확도를 최고로 올리기
4.[논문 리뷰] PaLM-E: An Embodied Multimodal Language Model

💡 PaLM-E: An Embodied Multimodal Language Model_논문 리뷰 📌 Abstract 📌 Incremental Learning의 필요성
5.[논문 리뷰] Tacotron 2 : NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS
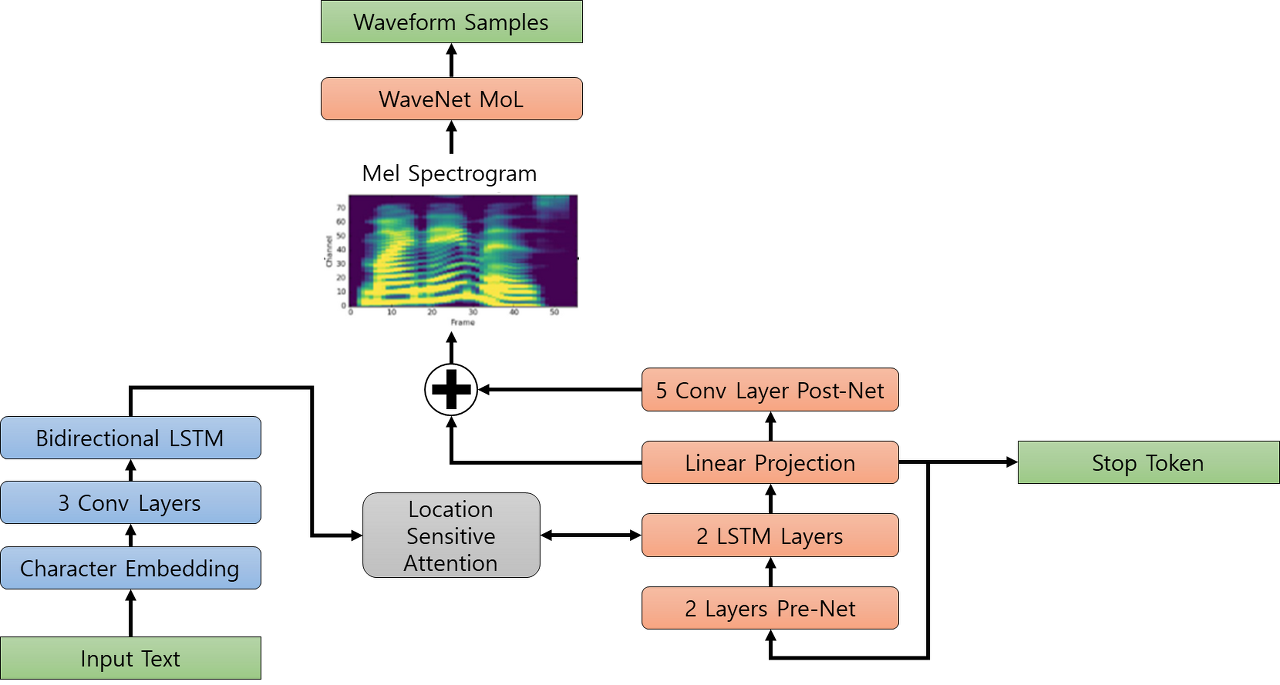
💡 Tacotron 2 : NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS_논문 리뷰 🤸 cf) Tacotron2 란? 2018년 Google에서 발표한 Tacotron2는
6.[논문 리뷰] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
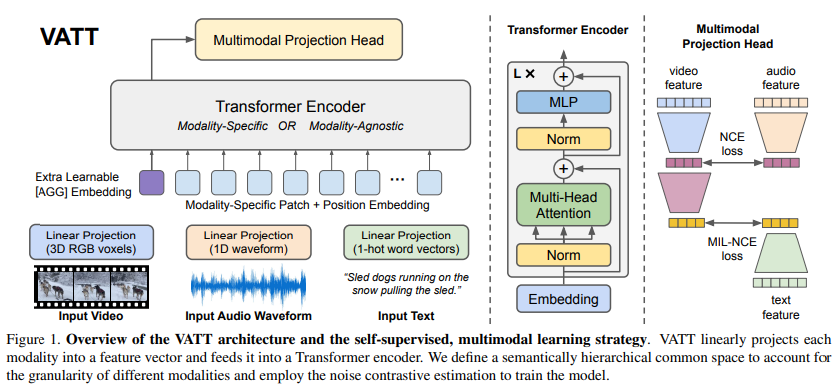
VATT 논문은 라벨이 부여되지 않은 비효율적인 visual 데이터에 대한 자기지도 학습 방법을 제안한다. 이를 위해 다양한 modalities에서의 self-supervised multimodal pretraining 모델을 연구하며, 비디오, 오디오, 텍스트를 입력
7.[논문 리뷰] Comparative Study of CNN and RNN for Natural Language Processing
💡 Comparative Study of CNN and RNN for Natural Language Processing_논문 리뷰 📌 Introduction 핵심적인 DNN 아키텍처로는 합성곱 신경망(CNN)과 순환 신경망(RNN) 두 가지 유형이 있다. NLP
8.[논문 리뷰] Guiding Pretraining in Reinforcement Learning with Large Language Models
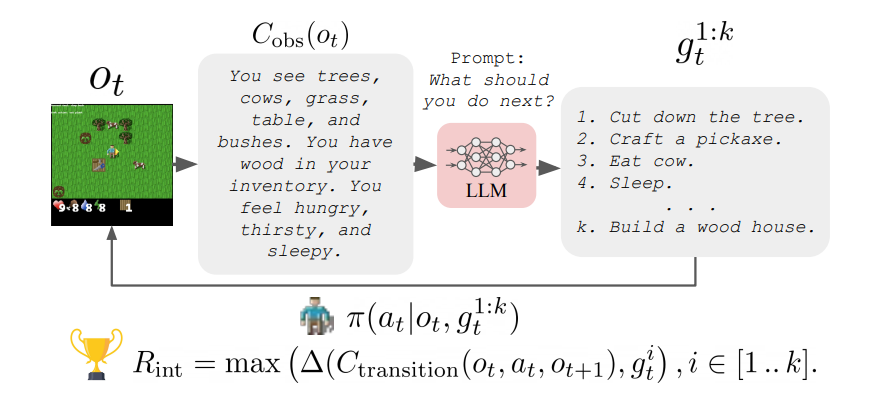
💡 Guiding Pretraining in Reinforcement Learning with Large Language Models_논문 리뷰 📌 Introduction 강화학습 알고리즘은 보상함수가 밀집된 경우 잘 작동하지 않는다. 이를 보완하기 위해 nov
9.[논문 리뷰] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
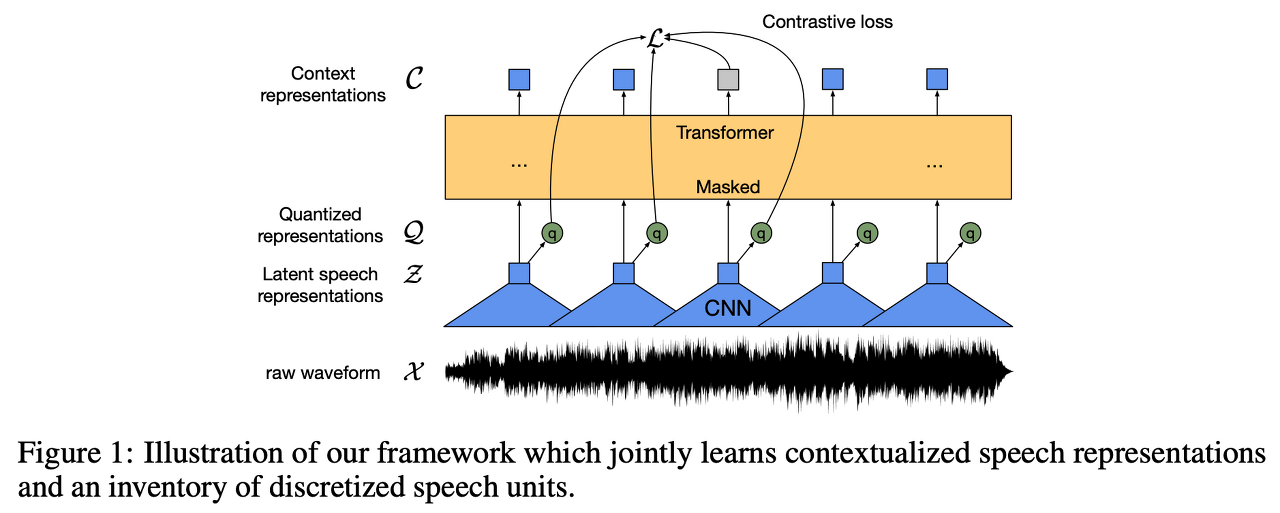
음성인식 수행 과정1\. Domain Knowledge를 활용하여 Handcraft Feature 생성2\. Handcraft Feature를 이용하여 Acoustic Model 개발Self-supervised Learning음성 데이터만으로 (텍스트X) 음성의 특징을
10.[논문 리뷰] Guiding Large Language Models via Directional Stimulus Prompting
💡 Guiding Large Language Models via Directional Stimulus Prompting_논문 리뷰 📌 Introduction 최근 대규모 언어 모델(Codex, InstructGPT, ChatGPT 등)의 부상으로 자연어 처리에서
11.[논문 리뷰] ADAM : A METHOD FOR STOCHASTIC OPTIMIZATION
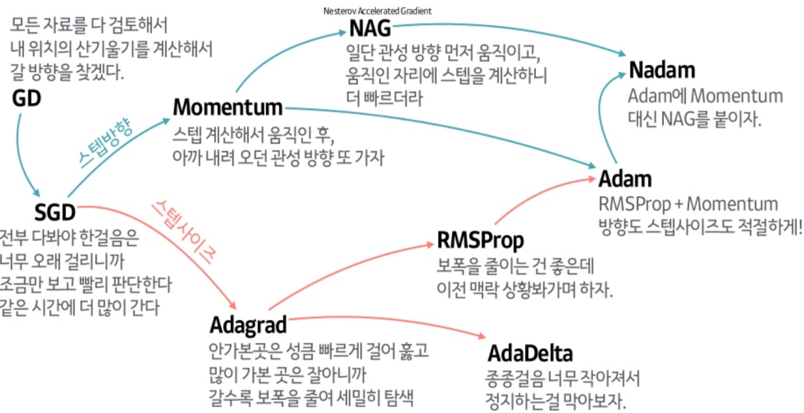
Adam : momentum RMS Prop Bias CorrectionFirst order optimizationgradient 수정이 제한적, 계산이 효율적Second order optimization효율적일 때도 있지만 대부분 시간 복잡도가 굉장히 큼SGD
12.[논문 리뷰] Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
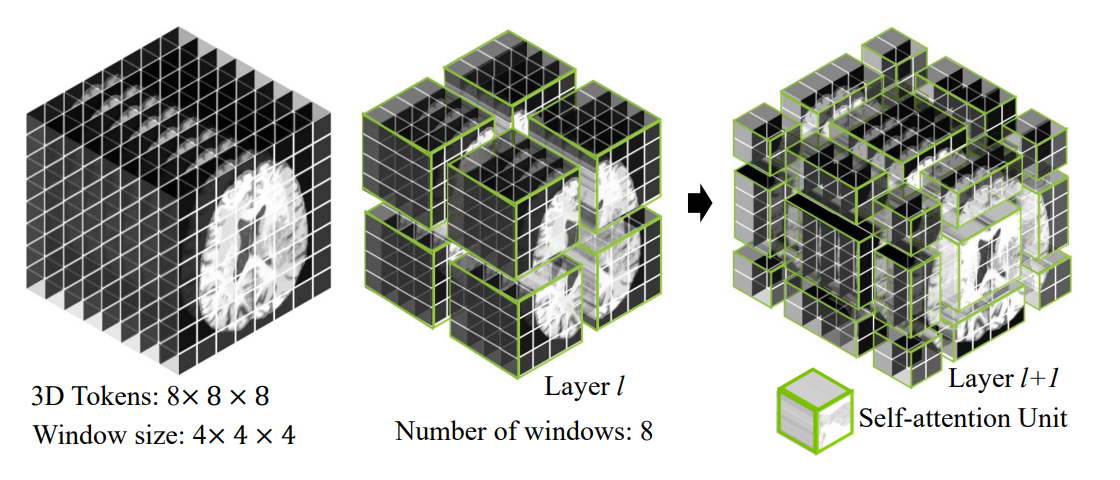
Swin Transformer Blockinput : H × W × D × S 크기patch partition layer : 3D 토큰 생성 → C 차원의 임베딩 공간에 투영Encoder2×2×2의 patch size, 2×2×2×4 = 32의 feature dime