💡 Guiding Large Language Models via Directional Stimulus Prompting_논문 리뷰
📌 Introduction
최근 대규모 언어 모델(Codex, InstructGPT, ChatGPT 등)의 부상으로 자연어 처리에서 새로운 패러다임이 나타나고 있다. 대부분의 대규모 언어 모델은 블랙박스 API를 통해 사용자에게만 제공되며, 특정 작업을 위한 레이블 데이터를 활용하기 위해 사용자 지정 텍스트 프롬프트를 사용하는 것이 표준적인 접근 방식이다. 이러한 프롬프트 방식의 한계를 극복하기 위해 본 논문은 DSP(Directional Stimulus Prompting)이라는 새로운 프레임워크를 제안한다.

📌 Directional stimulus prompting
LLM은 입력 공간 X, 데이터 분포 D(X), 및 출력 공간 Y가 있는 하류 작업에서 다양한 작업을 수행할 수 있다. 그러나 작업별 지시사항 또는 몇 가지 데모 사례만으로는 LLMs를 원하는 결과물로 이끌기 어려울 때가 있다.
DSP 접근 방식은 입력 쿼리에 힌트 및 단서로 작용하는 “directional stimulus”라는 작은 토큰을 도입하여 LLM을 세밀하게 안내한다.
Supervised fine-tuning
: “directional stimulus”를 생성하는 policy model을 훈련시키기 위해 pretrained LM에 대한 supervised fine-tuning 진행
Reinforcement learning
- Optimization objective :
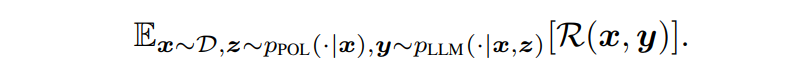
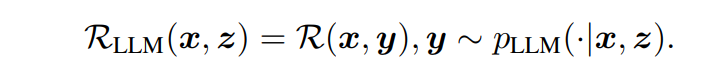
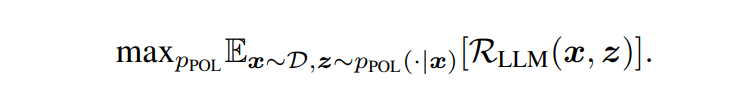
R을 최대화하여 LLM의 생성을 원하는 대상으로 이끈다. LLM의 파라미터가 접근 불가능하고 조절할 수 없기 때문에 policy model을 최적화하여 directional stimulus를 생성한다. LLM이 주어진 자극 z에 대한 조건부 성능을 어떻게 수행하는지 캡쳐하는 RLLM 측정치를 정의 - RL formulation :
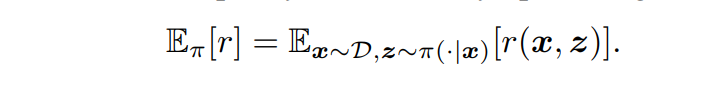
PPO(Proximal Policy Optimization)를 사용하여 policy model을 업데이트한다. policy model은 시퀀스의 토큰을 stimulus로 생성하는 것을 마르코프 결정 과정으로 볼 수 있으며 보상 함수, 상태 전이 확률 등을 사용한다. - Reward function :
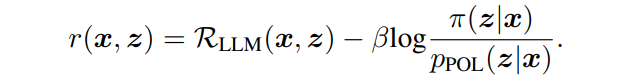
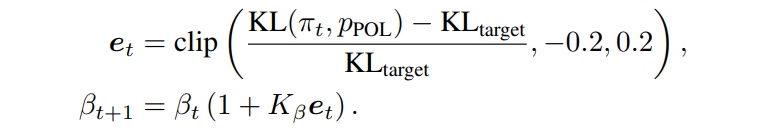
policy network π가 초기 policy model에서 너무 멀어지지 않도록 하기위해 KL-divergence penalty reward도 추가한다. - Implementation : PPO의 language generator로 구상된 NLPO 버전을 사용한다.
📌 Conclusion
DSP는 블랙박스 LLMs에 세밀하고 인스턴스별로 원하는 결과물로 안내하는 프레임워크로, 튜닝 가능한 policy model을 사용하여 directional stimulus을 생성한다. DSP는 블랙박스 LLMs에 더 나은 제어와 안내를 제공하며 레이블 데이터를 효과적으로 활용하고 생성된 directional stimulus은 LLMs의 행동에 대한 가치 있는 통찰력과 해석을 제공한다.
