💡 ADAM : A METHOD FOR STOCHASTIC OPTIMIZATION_논문 리뷰
- Adam :
momentum
RMS Prop
Bias Correction
📌 Background
- First order optimization
gradient 수정이 제한적, 계산이 효율적 - Second order optimization
효율적일 때도 있지만 대부분 시간 복잡도가 굉장히 큼
-
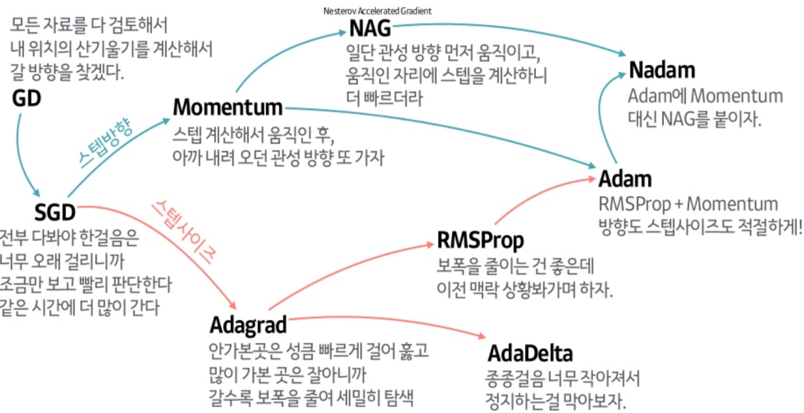
SGD :
data를 random sampling하여 gradient descent 수행
random sample 때문에 수렴 속도가 느림 (진동하면서 수렴) -
Momentum :
'운동량'을 뜻하는 단어 의미처럼 물체가 가속되어 공이 구르는 듯한 움직임
위 영향으로 인해 gloabl optimum으로 수렴하지 못할 가능성이 있음
learning rate가 고정되어 있음 -
Adagrad :
parameter 별로 learning rate를 다르게 적용
가중치 업데이트 횟수에 따라 learning rate 다르게 (업데이트가 자주 일어난 경우 small update, 반대는 large update)
가중치가 많이 업데이트 될수록 값이 누적되어 learning rate가 0에 수렴 -
RMSProp :
Adagrad와 달리 새로운 gradient를 더 많이 반영
learning rate가 0으로 수렴하지 않음
📌 Method

1. 모델의 가중치를 무작위 초기화
2. train data로부터 mini batch 무작위 적용
3. 위 batch로 loss 도출
4. 위 loss로 gradient 계산
5. 가중치 업데이트
Adam = Momentum + RMSProp + Bias Correction
- 모멘텀 하이퍼파라미터
: momentum의 지수이동평균
: RMSProp의 지수이동평균
m^, g^ : 학습 초기 시 , 가 0이 되는 것을 방지하기 위한 보정 값
ε : 숫자 안정성을 위한 작은 값
