💡 Guiding Pretraining in Reinforcement Learning with Large Language Models_논문 리뷰
📌 Introduction
강화학습 알고리즘은 보상함수가 밀집된 경우 잘 작동하지 않는다. 이를 보완하기 위해 novelty, surprise, uncertainty, prediction errors 들을 기반으로 부가적인 목표를 추가할 수 있다. 하지만 소음이 많은 tv나 나무의 잎 움직임 처럼 novelty는 많이 제공할 수 있지만 의미있지 않은 경우도 있다.
이를 최근에는 language와 같은 더 high-level의 표현을 사용해 novelty를 계산하고 novelty 최적화뿐만 아니라 학습된 행동이 유용하도록 해야한다. 본 논문에서는 language-based와 pretrained LLM을 유용한 행동에 대한 정보원으로써 사용하는 방법을 설명한다.
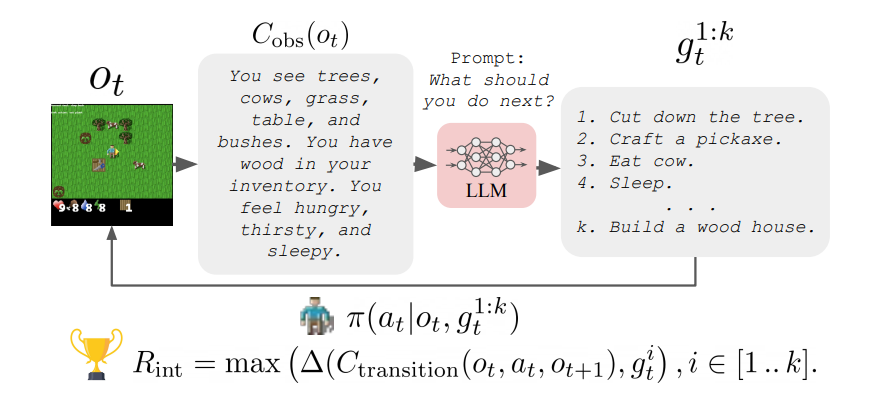
📌 Goal Generation with LLMs
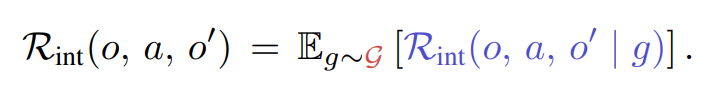
탐색 중에 타겟으로 하는 목표는 1) Diverse, 2) Common-sense sensitive, 3) Context sensitive 세 가지 특성을 만족해야 한다.
본 논문에선 LLM의 지식이 위 특징들을 만족한다는 가설을 제시한다.
- pretrained LLM
- Autoregressive models : 목표 생성
- Masked models : 목표를 벡터 형태로 표현
목표 생성
: LLM에게 agent의 가능한 행동 목록, 현재 관찰에 대한 텍스트 설명을 제공하여 목표를 얻음
목표 추출
Open-ended generation : LLM이 제안된 목표의 텍스트 설명을 생성하는 방식, 미래에 무엇을 해야하는지
Closed-form : LLM에게 가능한 목표를 QA로 제공하여 agent가 해야하는지 아닌지 답변을 제공
📌 Conclusion
ELLM(Exploring with Large Language Models)은 사전에 훈련된 LLM을 활용하여 탐색 방향을 상식적이고 유용한 목표로 바이어스하는 내재 동기 방법이다. 이 방법의 핵심 아이디어는 일반적인 독창성 탐색 방법과는 다르게 탐색을 상식적인 목표에 집중시키는 것이다.
