💡 Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images_논문 리뷰
📌 Method
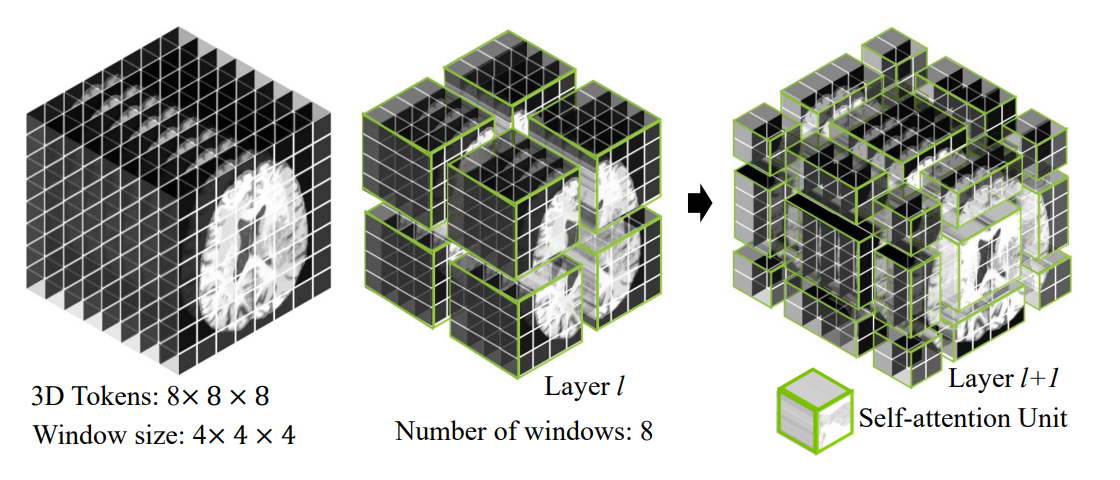
- Swin Transformer Block
- input : H × W × D × S 크기
- patch partition layer : 3D 토큰 생성 → C 차원의 임베딩 공간에 투영
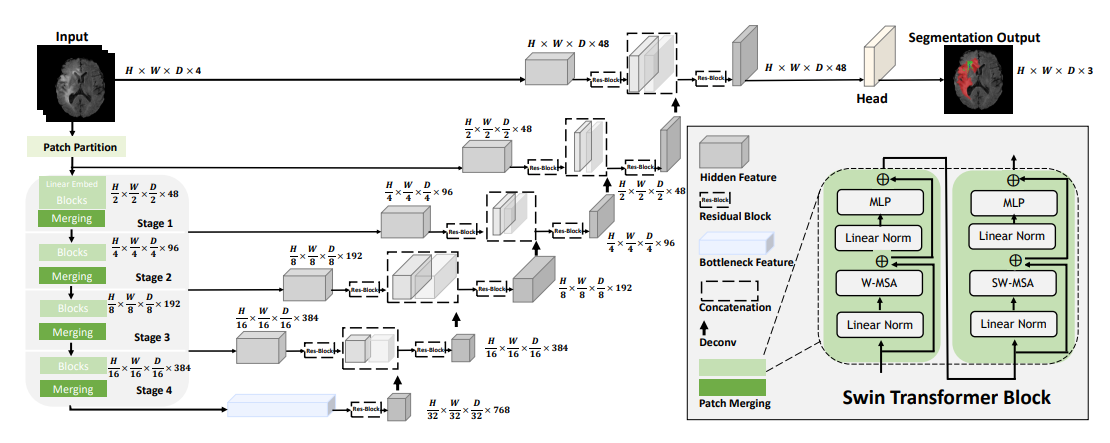
- Encoder
- 2×2×2의 patch size, 2×2×2×4 = 32의 feature dimension, embedding space C의 크기 48
- 8층의 레이어 : 각 2개의 transformer block을 갖는 4 단계
patch merging layer를 통해 feature representation 해상도를 각 단계마다 2배 낮춤, 4C 차원의 feature embedding 생성
linear layer를 통해 feature 크기가 2C로 줄어듬
- Decoder
- Swin transformer에서 인코딩된 feature representation을 skip connection을 통해 CNN 디코더로 전달
- 각 단계의 output인 feature representation을 재구성하여 3×3×3
convolutional layers 2개로 구성된 residual block으로 전달
feature representation 해상도는 2배 높아짐
- output
- ET, WT, TC 3개의 출력 채널로 분할 출력
- 1×1×1 convolutional layer와 sigmoid 함수로 계산
