📝 참고 사이트: 거꾸로 읽는 self-supervised-learning 파트 1
🔗 논문 링크: Neural Discrete Representation Learning

Abstract
Learning useful representations without supervision remains a key challenge in machine learning. In this paper, we propose a simple yet powerful generative model that learns such discrete representations. Our model, the Vector Quantised Variational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the encoder network outputs discrete, rather than continuous, codes; and the prior is learnt rather than static. In order to learn a discrete latent representation, we incorporate ideas from vector quantisation (VQ). Using the VQ method allows the model to circumvent issues of “posterior collapse” -— where the latents are ignored when they are paired with a powerful autoregressive decoder -— typically observed in the VAE framework. Pairing these representations with an autoregressive prior, the model can generate high quality images, videos, and speech as well as doing high quality speaker conversion and unsupervised learning of phonemes, providing further evidence of the utility of the learnt representations.
Introduction
1. Representation Learning for Generative Model with Discrete Features
-
최근 generative model은 여러 challenge한 task(few-shot learning, domain adaptation, reinforcement learning 등)에서 representation 학습에 의존하고 있습니다. 하지만, unsupervised 방식의 representation 학습은 여전히 dominant한 접근 방식이 아닙니다.
-
Pixel domain에서 unsupervised model을 학습하기 위해, maximum likelihood와 reconstruction error는 흔히 사용되는 방법입니다. 하지만, 그 유용성은 feature가 사용되는 특정한 application에 의존합니다.
-
본 논문의 목표는 maximum likelihood를 최적화하면서 데이터의 중요한 feature를 latent space에서 학습하는 것입니다.
-
Discrete representation은 많은 modality (언어 및 음성은 discrete, 이미지는 종종 언어 추론에 의해 discrete)에서 더욱 자연스럽습니다. 많은 이전의 연구들에서는 continuous features에 집중했지만, 본 논문은 discrete representation을 다룹니다.
2. Vector Quantised Variational AutoEncoder (VQ-VAE)
- 본 논문은 VAE에 discrete latent representation을 성공적으로 결합한 새로운 generative model를 소개합니다.
- VQ 방법을 적용하여 variance가 커지는 문제(discrete variable의 분산이 커서 학습이 느려짐)와 "posterior collapse"(Approximate posterior가 prior를 그대로 모방하여 latent variable를 무시한 상태에서 학습되는 문제)를 겪지 않습니다.
- 또한 VQ-VAE는 latent space를 효율적으로 사용하기 때문에, 종종 local한 정보(noise, 감지할 수 없는 세부사항)에 집중적으로 학습하지 않고 다양한 도메인에서 성공적으로 모델링할 수 있습니다.
- 마지막으로 Modality의 적합한 discrete latent space를 학습하여, discrete random variable를 통해 흥미로운 sample과 유용한 application을 생성합니다.
VQ-VAE
- VAE는 을 학습하는 encoder, , 그리고 를 학습하는 decoder로 이루어져 있으며, encoder의 output과 decoder의 input에서 reparametrization trick이 사용됩니다.
- : Discrete latent random variable (latent space)
- : input 의 posterior distribution(가 주어졌을 때 의 distribution)
- : Prior distribution
- : input 의 true distribution(가 주어졌을 때 의 distribution)
- VAE에 vector quantisation(VQ) 방식을 추가하여, 는 discrete latent variables로 학습되고 에서 추출된 embedding vector는 decoder를 통과합니다.
1. Discrete Latent Variables
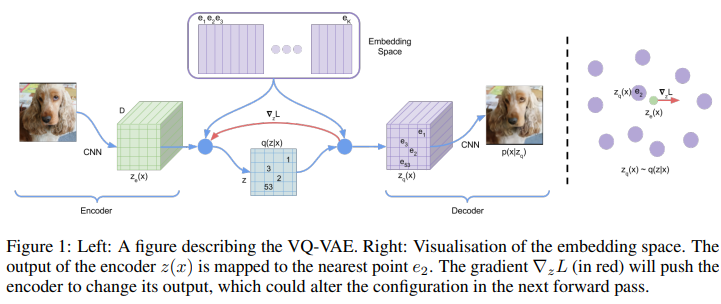
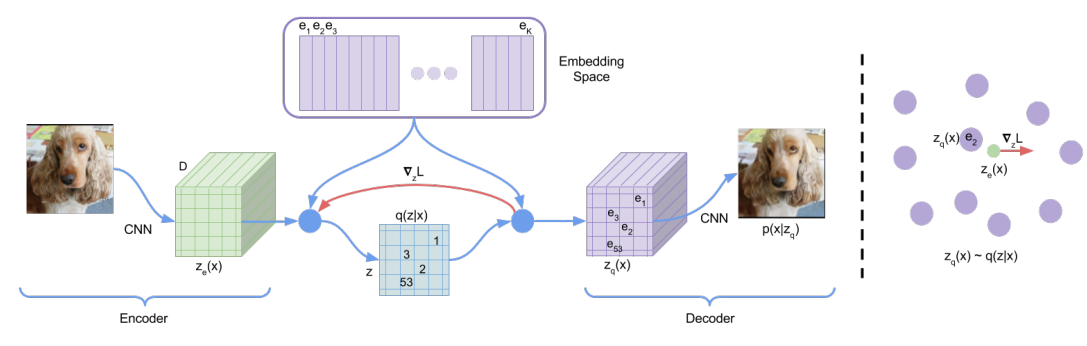
- 학습은 encoder, decoder, embedding space에서 이루어집니다.
- Latent embedding space (는 discrete size)를 설정합니다.
- 먼저, encoder에서 input x는 CNN를 거쳐 를 출력합니다.
- 식(1)을 통해 와 를 사용하여 최근접이웃 look-up 방식으로 dictionary 를 생성하고, 식(2) 방식으로 에 를 mapping하여 를 재구성합니다.

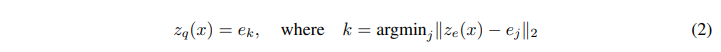
- 마지막으로 decoder에서 는 CNN을 거쳐 를 출력하게 됩니다.
- 저자들은 이 모델을 를 likelihood로 설정하고, ELBO 형태로 최적화하는 VAE라고 주장합니다. 를 uniform distribution으로 정의하여 term이 상수가 됩니다.
(VAE에서는 를 gaussian distribution으로 정의)
2. Learning
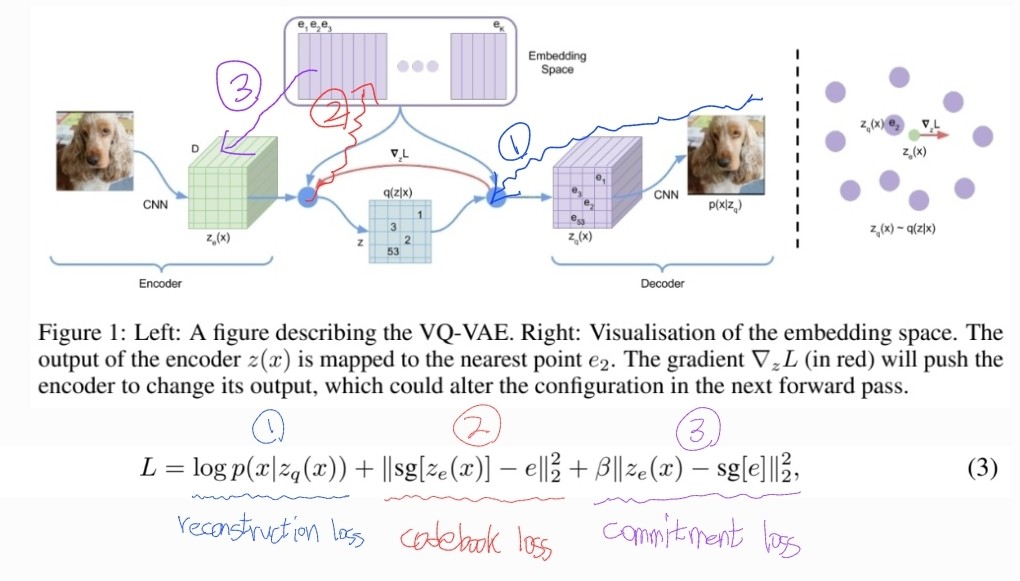
- 식(3)은 VA-VAE의 전체 손실 함수를 나타내며, 세가지 term으로 구성되어 있습니다. (sg: stop gradient)
① Reconstruction loss- 첫번째 term은 encoder와 decoder를 모두 최적화하는 reconstruction loss 입니다.
- 식(1, 2)에서 사용되는 argmin 연산은 비선형적이고 미분이 불가능하기 때문에, 'straight-through estimator'와 유사한 방법(decoder input 에서 encoder output 으로 gradient 복사)을 사용합니다.
- 즉, Forward에서는 가 decoder로 전달되고, backward 에서는 gradient가 encoder로 그대로 전달됩니다.
- Encoder output 과 decoder input 은 동일한 D 차원 공간을 공유하기 때문에, gradient에는 reconstruction loss를 최소화하기 위한 정보가 포함됩니다.
- 에서 로 gradient가 그대로 매핑되기 때문에, 는 reconstruction loss에서 gradient 정보를 받지 못합니다.
- 따라서, embedding vector를 학습하기 위해 가장 간단한 dictionary learning 알고리즘 vector quantization(VQ)를 사용합니다.
- 와 사이의 error를 통해, 를 로 이동하도록 학습됩니다.
- Embedding vector는 무한하기 때문에, codebook loss에서 는 encoder vector만큼 빠르게 학습되기 어려우며 임의로 커질 수 있습니다.
- Encoder vector가 embedding vector에 commit하여 encoder vector가 embedding vector와 유사해질 수 있도록하는 commitment loss를 추가합니다.
- hyperparameter의 변화에 따라 큰 성능 차이를 보이지 않으므로, 제안한 모델이 값에 대해 robust하다고 주장합니다. (모든 실험에서 = 0.25)
- 모델 의 log-likelihood는 로 계산됩니다. 여기서 decoder 는 MAP-inference로 부터 로 학습되었기 때문에, decoder가 완전히 수렴되면 에 대한 어떤 확률밀도도 구할 필요가 없습니다. 따라서, 가 되며, Jensen's inequality로 부터 가 될 수 있습니다.
3. Prior
- Discrete latents 에 대한 prior distribution은 categorical distribution이며, feature map의 다른 에 따라 autoregressive하게 만들수 있습니다.
- 본 논문에서는 image에서 PixelCNN, raw audio에서 WaveNet을 사용합니다.
Experiments
1. Comparison with continuous variables
- 성능 평가를 위해 VAE(coninuous variable) 및 VIMCO(independent gaussain, categorical priors)와 비교합니다. (VAE: , VQ-VAE: , VIMCO: )
- VQ-VAE은 discrete latent space를 사용함에도 continuous latent space를 사용했을 때와 비슷한 성능을 보이고 있습니다.
2. Images
-
Figure 2에서 오른쪽 image는 왼쪽 image를 latent space 로 변환한 뒤, VQ-VAE의 decoder로 다시 복원한 image이다. Resolution 및 detail은 다소 감소했으나, 차원을 매우 감소시켰음에도 중요한 정보를 잃지 않고 전체적인 부분을 잡아낸 것을 알 수 있다.

-
PixelCNN으로 VQ-VAE로부터 생성된 여러 이미지는 figure 3과 같다.

-
DeepMind Lab 환경에서 얻은 데이터로 학습한 결과는 figrue 4와 같다.

-
Figure 5는 latent variable을 3개만 사용한 reconstruction 결과입니다. Textures, room layout 및 nearby walls 등 원본 장면이 많이 남아 있지만, 모델은 pixel 값 자체를 저장하지 않고 PixelCNN에 의해 생성된 것을 확인할 수 있습니다. 즉, 일반적으로 VAE 모델에서 발생하는 posterior collapse 문제를 겪지 않으며, latent space가 의미있게 사용됩니다.

3. Audio
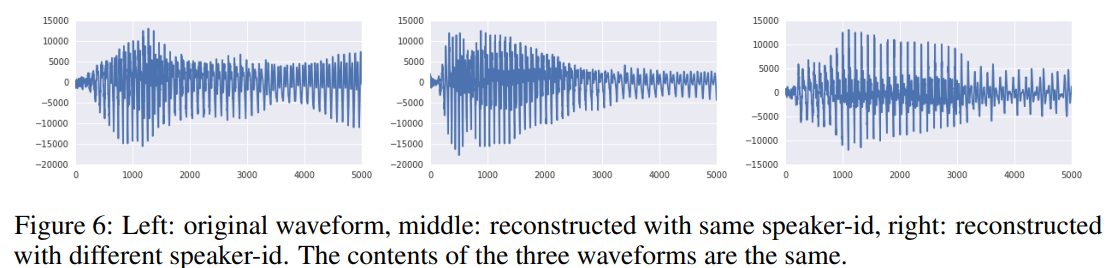
- 첫번째 실험으로, long-term 관련 정보만 보존하는 latent space를 추출하는 실험을 진행했습니다. Figure 6과 같이 reconstruction은 동일한 text contents를 보이지만 waveform이 상당히 다르고 음성의 운율이 달라집니다. 이것은 VQ-VAE가 언어 관련 supervised 학습이 없음에도 low-level features보다 음성의 content만을 encoding하는 high-level abstract space를 학습한다는 것을 의미합니다.
- 두번째 실험으로, 학습된 latent representation으로 prior를 학습시켜서 데이터의 long-term dependencies를 모델링했습니다. 기존의 가장 성능이 좋은 WaveNet의 sample에서 babbling처럼 들리지만, VQ-VAE의 sample에는 명확한 단어와 part-sentence가 포함되어 있습니다.
- 세번째 실험으로, 한 speaker로부터 latent를 추출한 후, decoder를 통해 다른 speaker로 reconstruction하는 speaker conversion을 시도했습니다. 이 실험은 encoding된 representation이 speaker별 정보를 제외했음을 보여줍니다.
- 네번째 실험으로, 각 discrete latent variable를 ground-truth phomeme-sequence와 일대일 비교를 진행했습니다. 모든 latent variable를 41개의 phoneme와 매핑시켜 classification을 진행한 결과, 분류 정확도 49.3%를 달성했습니다. (random accuracy 7.2%) Unsupervised 방식으로 얻은 latent variable가 phoneme 정보를 학습했다고 볼 수 있습니다.
4. Video
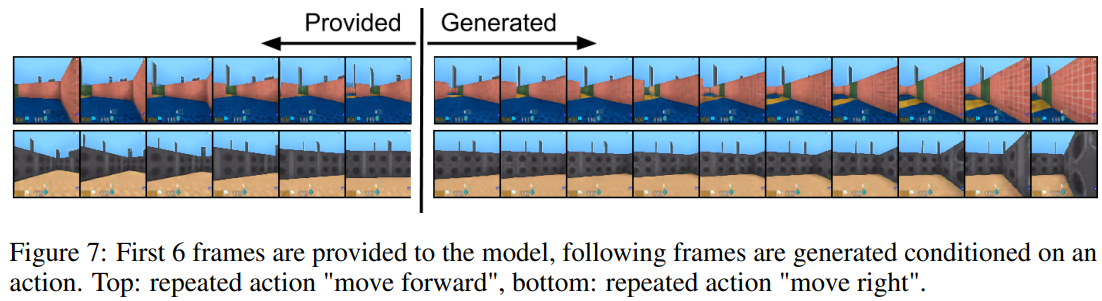
- DeepMind Lab 환경을 사용하여 주어진 작업 순서에 따라 생성 모델을 학습했습니다.
- Figure 7는 초반 6개 frame과 VQ-VAE에서 샘플링된 10개의 frame을 보여줍니다.
- VQ-VQE는 pixel sapce에 의존하지 않고 순전히 latent space에서 long sequence를 생성할 수 있음을 보여줍니다.
Conlusion
- 본 논문은 VAE와 VQ를 결합하여 discrete latent representation을 얻는 VQ-VAE 모델을 제안합니다.
- VQ-VAE는 압축된 discrete latent space를 통해 이미지, 비디오, 오디오에서 long term dependencies를 모델링 할 수 있음을 보여줍니다.
- 모든 실험은 unsupervasied 방식으로 학습하여 데이터의 중요한 특징을 잘 capture한다는 것을 보여줍니다.
- 또한, VQ-VAE는 CIFAR 10 데이터에서 continuous latent space와 유사한 성능을 달성합니다.
- 저자는 VQ-VAE가 long term sequence를 unsupervised 방식으로 성공적으로 모델링하는 최소의 discrete latent representation 모델이라고 주장합니다.
🙆🏻♂️ 논문을 읽고 나서..
- Discrete latent space 학습을 위해 stop gradient와 VQ 방법을 사용해서 여러 문제를 해결하는 방법이 신기했다.
- End-to-end 방식이 아닌 것이 아쉬웠으며, autoregressive 모델만을 사용해야 하는것인지 다른 모델을 사용했을 때의 성능은 어떤지 궁금하다. 🤷🏻♂️
- 개인적으로 VAE의 개념과 수식을 완벽히 이해하기 위한 추가 공부 및 포스팅이 필요할 것 같다. 🙋🏻♂️
