[논문 리뷰] DeepCluster: Deep Clustering for Unsupervised Learning of Visual Features
Self-Supervised Learning
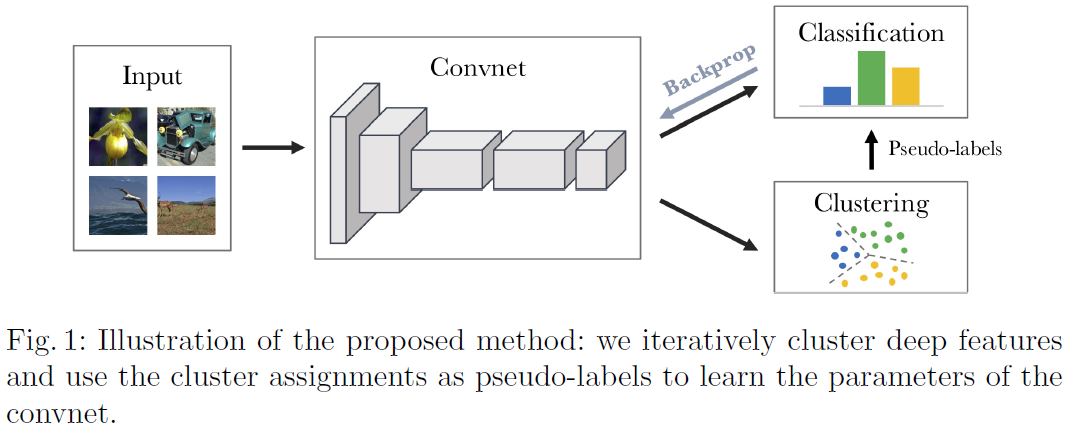
📝 참고 사이트: 거꾸로 읽는 self-supervised-learning 파트 1
🔗 논문 링크: Deep Clustering for Unsupervised Learning of Visual Features

Abstract
Clustering is a class of unsupervised learning methods that has been extensively applied and studied in computer vision. Little work has been done to adapt it to the end-to-end training of visual features on large scale datasets. In this work, we present DeepCluster, a clustering method that jointly learns the parameters of a neural network and the cluster assignments of the resulting features. DeepCluster iteratively groups the features with a standard clustering algorithm, k- means, and uses the subsequent assignments as supervision to update the weights of the network. We apply DeepCluster to the unsupervised training of convolutional neural networks on large datasets like ImageNet and YFCC100M. The resulting model outperforms the current state of the art by a signi cant margin on all the standard benchmarks.
Introduction
1. Pre-trained Convnet
- Pre-trained Convnet은 general-purpose features를 학습하여 데이터수가 제한된 환경에서 일반화 성능을 향상시킨다.
- ImageNet은 large fully-supervised dataset으로, pretrained convnet의 발전을 이끌었다.
- 그럼에도 ImageNet은 오직 object classification을 위한 백만 개의 이미지가 포함되어 있으며, 이는 오늘날의 real wolrd에 비해 상대적으로 작다.
- 수십 억개의 더 크고 다양한 데이터셋을 구축해야 하지만, 이를 labeling 하는 것은 많은 비용이 들며 visual representation의 bias가 발생한다.
- 이를 해결하기 위해 unsupervised learning 방법이 필요하다.
2. Unsupervised Learning
- Clustering, dimensionality reduction, density estimation 등 unsupervised learning은 특정 도메인(위성, 의료 등) vision에서 자주 사용된다.
- End-to-end 방식의 unsupervised learning 연구는 거의 없으며, 큰 규모의 연구는 없다.
- Clustering은 주로 고정된 feature 위에 linear model을 추가하는 방식으로 설계되는데, clustering과 feature를 동시에 학습하게 되면, feature가 0이 되고 cluster가 single entity로 축소되는 trivial solution을 야기할 수 있다. (즉, 1개의 cluster로 학습됨)
3. Proposed Model
- 큰 규모의 end-to-end를 통해 범용적인 visul feature를 얻는것이 가능한 새로운 clustering 방법을 제안한다.
- Cluster assignment를 예측하여, 이미지 clustering과 convnet의 가중치 업데이트를 교대로 진행된다.
- Clustering 알고리즘으로는 K-means를 사용한다. (supplementary에 PIC 방법 비교 되어 있음)
- Pre-training이 필수적인 self-supervised 방법과 달리 제안하는 clustering방법은 domain knowledge가 거의 필요하지 않고, 특정한 signal이 요구되지 않는다.
Contribution
- K-means를 사용한 end-to-end unsupervised learning 방식의 clustering
- Unsupervised learning을 사용한 많은 standard transfer task에서 state-of-the-art를 달성
- Unsupervised feature learning의 현재 평가 프로토콜 discussion
Related Work
Unsupervised Learning of Features
- Unsupervised clustering의 기존의 연구(Coates and Ng [32])는 multi-stage로 이루어진다.
- Convnet feature와 image cluster를 공동으로 학습하는 기존 연구([21,22,33,34])는 현대 convnet architecture에서 연구되는 큰 규모에서 검증되지 않았다.
Self-Supervised Learning
- Unsupervised learning의 한 방법으로, "pseudo-labels"로 label를 대체하여 representation learning을 수행한다.(ex. masking, patch level, pixel level)
- Spatial과 temporal 일관성, 이미지 색상, 교차 채널 예측, 소리 또는 instance counting 등 다양한 self-supervised learning이 존재하는데, 이는 도메인에 종속적이다.
Generative Models
- Unsupervised learning의 한 방법으로, autoencoder, GAN, reconstruction loss 등 을 사용한다.
Method
1. Preliminaries
- Convnet mapping function:
- Classifier:
- 다음 를 거쳐 학습이 진행되며, 와 는 동시에 학습된다.
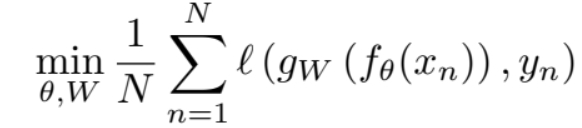
2. Unsupervised Learning by Clustering
-
학습 없이 Gaussian distribution에서 가 sample되면, 는 좋은 feature를 생성하지 못하지만, random 결과보다 높은 수준을 보여준다.
=> 학습되지 않은 AlexNet의 ImageNet에서정확도는 12%지만, class 1000개의 확률은 0.1%이다. -
이러한 약한 신호(초기 feature)를 이용하여 convnet의 output(feature label)을 clustering하고, 이를 pseudo-labels ()로 사용하여 최적화한다.
-
K-means clustering을 사용했으며, 아래 수식이 최적화되는 을 pseudo-label로 사용한다.
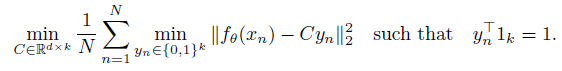
-
DeepClustr는 feature 학습과 clustering이 교대로 이루어지는데, 이는 trivial solution(1개의 cluster로 학습)이 될 수 있다.
3. Avoiding Trivial Solutions
- Trivial solution은 unsupervised learning에만 국한된 것이 아닌, classifier와 label을 공동으로 학습할 때 발생한다.
Empty clusters
- Discriminative model은 class간의 결정 경계를 학습하는데, 최적의 결정 경계는 모든 데이터를 하나의 cluster에 할당하는 것이다.
- K-means 최적화 과정에서 빈 cluster를 다른 cluster로 재할당하여 해결한다.
=> 빈 cluster의 centroid를 비어있지 않은 cluster의 centroid로 할당하고, data를 두개의 cluster에 재할당한다.
- K-means 최적화 과정에서 빈 cluster를 다른 cluster로 재할당하여 해결한다.
Trivial parametrization
- 데이터 불균형에서도 발생하는 문제로, major class에 중점적으로 parameter가 학습된다.
- Loss function에 cluster 크기에 대한 가중치를 주어 해결한다. (할당된 cluster 크기의 역수)
Implementation detils
- AlexNet와 VGG-16을 사용하여 결과를 비교하고, unsupervised 방법은 종종 색상 정보에 영향을 받지 않기 때문에 Sobel 필터를 사용하여 이미지의 색상을 제거한다.
- 대규모 데이터셋인 ImageNet을 사용한다.
- PCA 알고리즘으로 256 차원으로 축소하고 정규화한 뒤에 K-means clustering을 수행한다.
Experiments
1. Preliminary Study
- Normalized Mutual Information (NMI)를 사용한다.
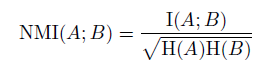
=> Cluster가 실제 label에 얼마나 종속적인지 평가한다.
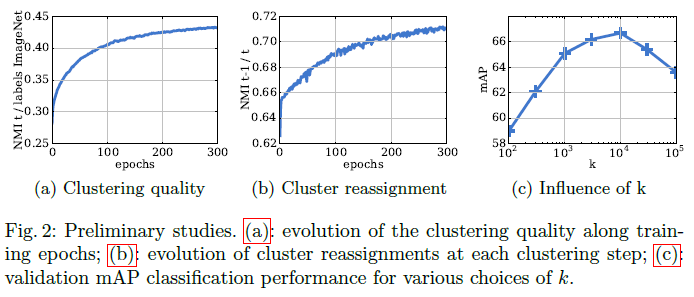
Relation between clusters and labels
- Figure 2(a)는 학습중 할당된 cluster와 ImageNet label 간의 NMI 값을 보여준다.
- 학습이 진행됨에 따라 cluster와 label간의 dependence가 증가함을 알 수 있다.
Number of reassignmnets between epochs
- Figure 2(b)는 각 epoch 마다, 이미지를 새로운 cluster에 재할당하게 되는데, 안정성을 확인하기 위한 결과이다.
- 훈련이 진행됨에 따라 재할당이 점점 줄어들고 cluster가 안정화되는 것을 알 수 있다.
Choosing the number of clusters
- Figure 2(c)는 K-means의 하이퍼파라미터인 cluster의 수 k에 따라 모델의 성능을 보여준다.
- K가 10000일 때 최상의 성능을 얻었으며, ImageNet의 class개수인 1000이상의 분할이 유용할 수 있다는 것을 알 수 있다.
2. Visualizations
First layer filters

- Figure 3은 raw RGB image와 Sobel filtering image에 대해 DeepCluster로 훈련된 AlexNet의 첫 번째 layer의 필터를 보여준다.
- RGB image의 대부분의 필터는 일반적으로 객체 분류에 적은 영향을 미치는 색상 정보만 캡처하지만, Sobel filtering image는 edge detector와 같은 역할을 합니다.
Probing deeper layers

- Figure 4는 activation을 최대화하는 input image를 학습하여 target filter의 qulity를 평가한다.
- 예상대로, 네트워크의 더 깊은 레이어는 더 큰 textural 구조를 캡처하는 것처럼 보인다.
- 그러나, 마지막 convolutional layer의 일부 필터는 이전 레이어에서 이미 캡처된 textural를 단순히 반복한 거처럼 보인다.

- Figure 5는 의미상 일관성이 있는 것으로 보이는 일부 필터의 activated image를 보여준다.
- 첫번째 행은 class와 상관관계가 높은 정보가 포함되어 있고, 두번째 행은 그림이나 추상적인 모양의 스타일에 동작하는 필터로 보인다.
3. Linear classification on activations
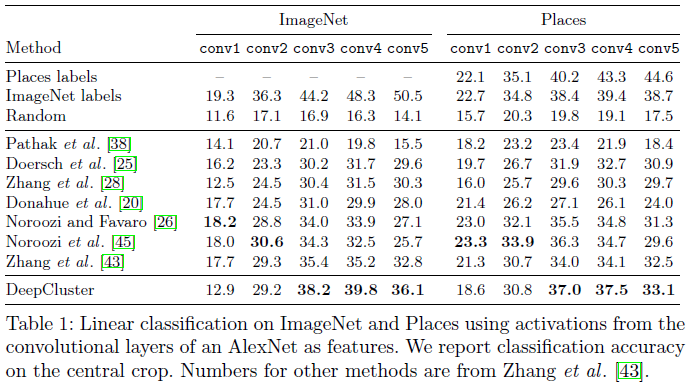
- Table 1은 각 convolutional layer를 고정시키고 선형 분류기를 학습하여 얻은 결과이다.
- DeepCluster가 기존의 unsupervised learning 방법보다 conv3~5에서 약 5% 더 나은 성능을 보인다.
- Sobel filtering이 색상 정보를 제거했기 때문에 conv1에서 낮은 성능을 보인다.
- Conv3이 conv5보다 더 나은 성능을 보였는데 이는 Figure 4의 결과와 일치한다.
- Places에는 column에는 ImageNet으로 학습된 모델을 Places 데이터로 test한 결과를 보여준다.
- DeepCluster는 conv4에서 가장 높은 성능을 보였으며, ImageNet supervised learning과 마찬가지로 conv5(label과 가장 가까운 layer)의 성능이 낮은것을 알 수 잇는데, 이는 도메인 다를 때 label이 덜 중요하다는 것을 의미한다.
4. Pascal VOC 2007
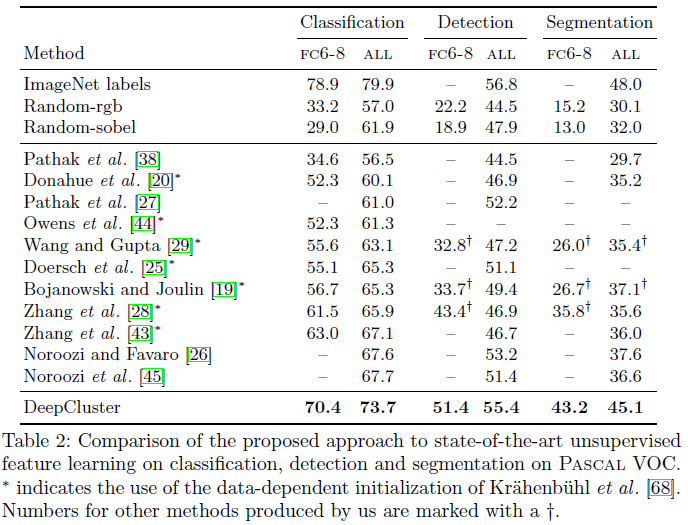
- Table 2에는 Pascal VOC에서 3가지 task(image classificaion, object detection, semantic segmentation)에 대한 결과를 보여준다.
- DeepCluster는 기존의 unsupervised 방식을 능가한다.
- 특히, FC6-8만을 학습하는 것은 실제 응용을 위해 중요한데, 기존의 방식보다 최대 9%(분류시) 더 나은 성능을 보인다.
Discussion
1. ImageNet versus YFCC100M

- ImageNet은 balanced 데이터셋으로, DeepCluster는 balanced 데이터셋을 선호함으로 다른 unsupervised 연구와 공정한 비교가 되지 않을 수 있다.
- Table 3은 YFCC100M 데이터에서 무작위 sampling하여 imbalance 데이터셋을 만들고, 비교 분석한 결과이다.
- DeepCluster는 불균형 데이터셋에서 성능이 저하되었음에도 불구하고, 3가지 task에서 모두 더 나은 성능을 보인다.
=> Class distribution의 변화에 강건하다.
2. AlexNet versus VGG
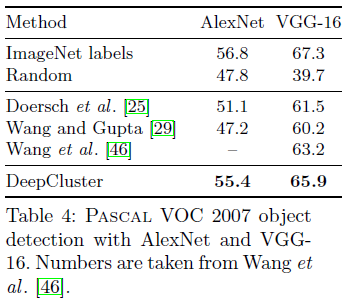
- Table 4는 VGG는 AlexNet보다 더 깊은 convnet으로, 다른 architecture를 사용하더라도 성능이 동일한지 확인하기 위한 결과이다.
- Architecture와 관계없이 더 깊어질 수록 성능이 크게 향상 된다.
3. Evaluation on Instance Retrieval
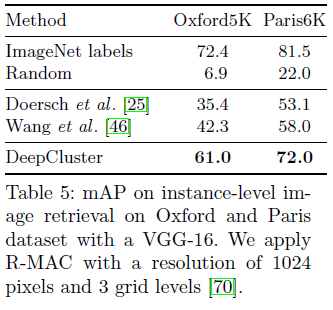
- Table 4는 제안된 모델이 class level이 아닌 instance level에서 기존의 연구보다 높은 성능을 보여준다.
Conclusion
- Convnet의 unsupervised learning 기반 clustering 방법 DeepCluster를 제안한다.
- K-means를 통해 convnet의 feature를 clustering 하고 이를 pseudo-label로 사용하여 가중치 학습을 반복한다.
- ImageNet과 같은 대규모 데이터셋에서 검증되었다.
- 제안된 모델의 접근 방식은 input에 제약조건을 거의 두지 않으며, 도메인 특정 지식이 필요하지 않다.
🙆🏻♂️ 논문을 읽고 나서..
- 학습되지 않은 모델이라도 class 확률보다 나은 성능을 보인것을 이용하여, k-means clustering 결과를 pseudo-label로 사용한것이 인상깊었다.
- DEC 와 DAC는 비교적 적은 데이터셋으로 간단한 convnet으로 검증되었지만, DeepCluster는 대규모 데이터셋인 ImageNet으로 더 깊은 arcitecture로 학습하여 다양한 task에서 검증되었다.
- Trivial solution을 해결하기 위한 방법 두가지의 효과가 궁금하다. 🤷🏻♂️
- DAC 에서의 의문점과 유사하게, cluster label를 one-hot vector 문제가 아닌 regression 문제(확률 값으로)로 변형시켜서 보다 유연한 모델을 만들 수 있을까? 🙋🏻♂️
