1️⃣Regression (회귀)
1. Regression (회귀)
- 개념: 지도 학습 기법 중 하나로, 수치형 결과값을 예측하고 분석하는 데 사용됨
- 원리: 둘 이상의 변수(독립변수 X, 종속변수 Y) 간의 관계를 모델링하여, X의 값을 알면 Y를 추론할 수 있도록 하는 것
- 예시: X = 공부 시간, Y = 시험 점수 → "공부 시간을 알면 시험 점수를 예측할 수 있다"
2. Linear Model (선형 모델)
- 특징
- 학습과 예측 모두 매우 빠름
- 구조가 단순하기 때문에 해석하기도 쉬움
- Linear Regression → 수치 예측에 사용
- Logistic Regression → 분류에 사용
2️⃣Linear Regression Model (선형 회귀 모델)
1.
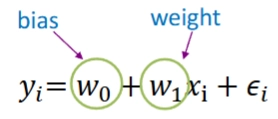
y=종속 변수, x=독립 변수
w0=절편, w1=가중치, ϵ=오차
2. Loss Function (손실 함수) OLS solution (=MSE)
- 개념: 예측이 실제와 얼마나 다른지를 수치로 측정하는 함수로, 실제 값과 예측 값의 차이를 제곱해서 모두 더한 값(=Sum of Squared Errors, SSE)을 구하는 용도
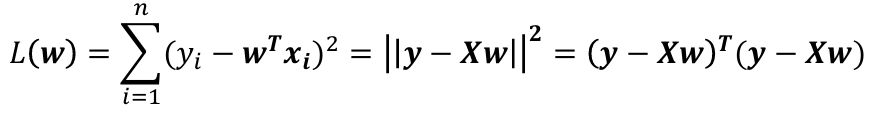 위 식에서, 우리는 w를 찾는 것을 목표로 하는데, 두 가지 방법이 존재함
위 식에서, 우리는 w를 찾는 것을 목표로 하는데, 두 가지 방법이 존재함
1. w가 1차식일 경우, 미분해서 0이 되는 지점을 찾으면 됨!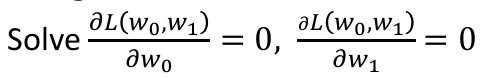 (편미분을 진행한 뒤, 연립이차방정식으로 둬서 푼다.)
(편미분을 진행한 뒤, 연립이차방정식으로 둬서 푼다.)
2. w가 2차식 이상일 경우, 경사하강법을 사용함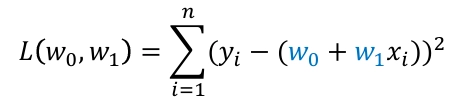
3️⃣Gradient Descent (경사하강법)
1. Gradient Descent (경사하강법)
- 개념: 함수의 기울기를 이용하여 손실 함수를 줄이는 방향으로 파라미터를 점차 업데이트하는 방법
- 원리: 손실 함수를 최소화하고 싶을 때, 현재 파라미터 w에서 기울기를 계산하고, 그 반대 방향으로 이동
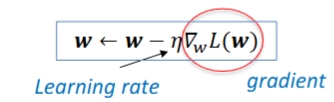 η=학습률(learning rate)
η=학습률(learning rate)
- 절차:
- 파라미터 w를 임의로 정한다.
- 기울기의 반대 방향으로 w를 업데이트한다.
- 손실이 더 이상 크게 줄지 않을 때 멈춘다.
2. Early stopping
- 개념: 단순히 훈련데이터의 손실만 보는 게 아니라, 검증데이터의 손실도 같이 확인하면서 학습을 조기에 멈추는 방법
- 원리: 검증데이터의 손실이 줄어들다가 더 이상 줄지 않고 다시 증가하기 시작하면 조기 종료
4️⃣경사하강법의 변형
1. (Batch) Gradient Descent
- 방식: 전체 데이터셋을 이용해서 기울기를 계산 → 한 번 업데이트
- 특징:
- 정확한 기울기 제공
- 데이터가 커지면 계산량이 너무 크고 느려짐
- 장점: 안정적이고 수렴이 보장됨
- 단점: 대규모 데이터에서는 한 번의 기울기 계산에 시간이 오래 걸림
2. Stochastic Gradient Descent (SGD)
- 방식: 한 번 업데이트할 때 데이터 1개 샘플만 사용
- 특징:
- 빠른 업데이트 가능 → 온라인 학습(실시간 데이터)에 유용
- 기울기가 노이즈가 심하지만, 평균적으로는 올바른 방향을 향함
- 장점:
- 빠르고 자주 업데이트 가능 → 큰 데이터셋에 적합
- 지역 최소값에서 벗어날 수 있음
- 단점:
- 너무 불안정하게 요동치면서 학습될 수 있음
3. Mini-batch Gradient Descent
- 방식: 전체 데이터 대신, 작은 묶음(예: 32, 64, 128개 샘플)을 사용해 업데이트
- 특징: Batch GD와 SGD의 절충안
- 장점:
- Batch GD보다 빠르게 수렴 (더 많은 업데이트 수행 가능)
- SGD보다 안정적 (노이즈 감소)
- GPU 같은 하드웨어에서 벡터화 연산 가능 → 효율적 계산
- Batch size의 크기에 따른 효과:
- 너무 크면 → Batch GD처럼 느려짐
- 너무 작으면 → SGD처럼 불안정해짐
✅Epoch
- 개념: 1 epoch=전체 데이터셋 학습을 1회 진행하는것 (ex. Mini-batch는 여러 번 반복해야 1 epoch임)
5️⃣Learning Rate (학습률)
1. Learning rate(학습률)의 역할
- 가중치를 업데이트할 때 한 번에 움직이는 보폭
2. 크기에 따른 차이
- 너무 클 때👎
- 너무 크게 움직여서 최소점을 지나쳐버림
- 발산하거나, 손실이 오히려 커질 수 있음
- 너무 작을 때👎
- 업데이트 폭이 작아서 매우 천천히 수렴
- 최적점에 도달하기 위해 많은 반복 필요
- → 장점: 안정적 / 단점: 시간 오래 걸림
- 적절할 때👍
- 빠르면서도 안정적으로 수렴
- 최적값 근처에서 잘 멈춤
3. Adaptive Learning rate (적응적 학습률)
- 고정된 학습률은 최적화에 방해될 수 있음
- 그래서 보통 처음에는 크게 → 점점 작게 하는 방식 사용
✅선형 회귀의 문제점
- 불필요한 feature가 많아서 과적합 위험 증가
- 모델이 복잡해지면 데이터 요구량이 많아져서 과적합 위험 증가
✅해결책
- Feature Selection (특징 선택)
- Regularization (정규화)
6️⃣모델의 복잡도
1. 결정 계수
- 개념: 모델이 실제 데이터 분산을 얼마나 잘 설명하는지 비율로 나타낸 지표 (클수록 좋음)
- 특징: Feature를 추가할수록 증가
- 문제점: 과대평가 위험이 있음
- 해결책: 수정된 결정계수 사용
2. 모델 복잡도를 줄이는 방법
- Exhaustive Search (Best Subset Selection)
- 개념: 모든 가능한 Feature의 조합을 탐색하여 가장 좋은 모델을 선택하는 기법
- Forward Selection
- 개념: 한 번에 하나씩, 가장 성능이 좋아지는 Feature를 추가하는 기법
- Backward Elimination
- 개념: 한 번에 하나씩, 가장 덜 중요한 Feature를 제거하는 기법
- Regularization (정규화)
- 개념: 학습 알고리즘에 벌점을 추가하여 ****일반화 오류는 줄이고 훈련 오류는 크게 늘리지 않도록 제어하는 기법
7️⃣정규화
1. Lasso Regression (L1 정규화)
- 수학적으로, 일부 계수가 정확히 0이 됨 → Feature Selection 효과
- 즉, 불필요한 변수를 자동으로 제거
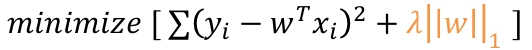
2. Ridge Regression (L2 정규화)
- 계수를 0에 가깝게 줄이는 효과
- 하지만 계수가 정확히 0이 되지는 않음 → 모든 Feature는 모델에 남음
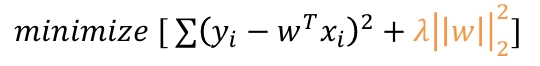
3. Elastic Net (L1 + L2 혼합)
✅정규화가 도움이 되는 이유?
- 계수가 크면 → 모델이 입력 데이터의 작은 변화에도 민감하게 반응 (variance ↑)
- 계수를 줄이면 → 모델이 더 단순해지고, 일반화 능력(generalization) ↑
→ L1 / L2 정규화 = 큰 계수를 줄여주는 역할 = 일반화 성능 개선

개발자를 꿈꾸는 대학생