기계학습
1.데이터 전처리 (Data preprocessing)
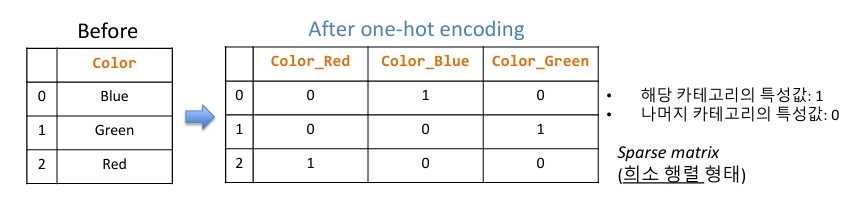
개념: 입력 데이터와 그에 해당하는 정답(라벨, 목표값)이 함께 주어진 상태에서 학습하는 방식목적: 새로운 입력에 대해 올바른 출력을 예측개념: 정답(라벨) 없이 입력 데이터만 주어진 상태에서, 데이터의 숨겨진 구조나 패턴을 찾는 방식목적: 데이터의 군집, 특징, 차원
2.분류 (Classification)
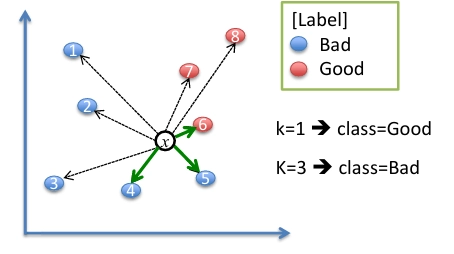
주어진 훈련 데이터로 분류기(classifier)나 회귀기(regressor)를 학습시킴기계학습 알고리즘은 이 데이터들의 분포와 패턴을 학습하여, 새로운 데이터가 들어왔을 때 어떤 클래스에 속할지 구분할 수 있는 결정 경계(decision boundary) 를 만듦보지
3.SVM(Support Vector Machine)
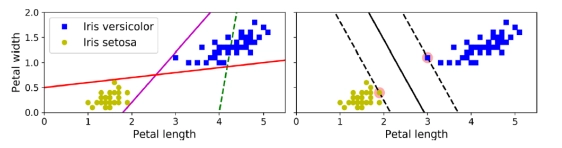
개념: 주어진 데이터를 기반으로 분류 또는 회귀 분석을 할 수 있는 알고리즘목적분류 작업: 결정 경계를 찾고 데이터를 클래스로 분류마친 최대화: 데이터 포인트 사이의 간격(마진)을 최대화하려고 노력장점: 쉽게 확장이 가능개념두 클래스가 명확하게 분리되는 경우, 직선으로
4.성능 평가
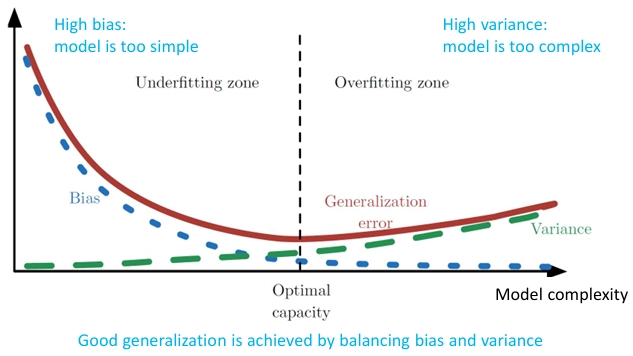
개념: 모델이 너무 단순해서 생기는 오차특징훈련 데이터와 상관없이 항상 비슷한 형태의 예측 오류 발생일반화가 잘 안 됨개념: 모델이 훈련 데이터에 너무 민감해서 생기는 오차(→과적합)특징훈련 데이터셋이 조금만 바뀌어도 예측 결과가 크게 달라짐훈련 데이터 정확도는 높지만
5.Linear Regression
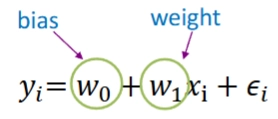
개념: 지도 학습 기법 중 하나로, 수치형 결과값을 예측하고 분석하는 데 사용됨원리: 둘 이상의 변수(독립변수 X, 종속변수 Y) 간의 관계를 모델링하여, X의 값을 알면 Y를 추론할 수 있도록 하는 것예시: X = 공부 시간, Y = 시험 점수 → "공부 시간을 알면
6.Logistic Regression
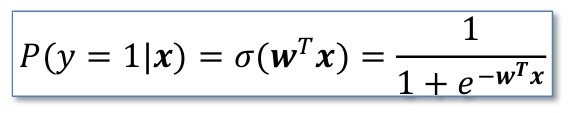
개념: 일반적인 선형 회귀와는 다르게, 이진 분류 문제를 해결하는 데 사용되는 방법그렇다면 왜 Regression인가? → 결과값은 확률값으로 나오기 때문!개념: 실제값과 예측값의 차이를 보여주는 함수로, 실수를 0~1 사이의 값으로 매핑해줌특징:0일때는 0.5, 무한